|
この文書は自動機械翻訳技術を使用して翻訳されています。 正確な翻訳を提供するように努めておりますが、翻訳された内容の完全性、正確性、信頼性については一切保証いたしません。 相違がある場合は、元の英語版 英語 が優先され、正式なテキストとなります。 |
v1.4.0からv1.4.1にアップグレードする
一般情報
新しいSUSE Virtualizationバージョンが利用可能になると、*ダッシュボード*画面に*アップグレード*ボタンが表示されます。詳細については、アップグレードを開始するを参照してください。
エアギャップ(された)環境については、エアギャップアップグレードの準備をするを参照してください。
|
アップグレードを開始する前に、各ノードのオペレーティングシステムイメージのディスク使用量を確認してください。これを行うには、SSH経由でノードにアクセスし、コマンド`du -sh /run/initramfs/cos-state/cOS/*`を実行します。 例:
`passive.img`はスパースファイルに変換され、1.7Gのディスクスペースしか消費しないはずです(`active.img`と同じです)。これにより、各ノードに十分な空きスペースが確保され、アップグレードプロセスが「再起動待機」状態で停止するのを防ぎます。 |
SUSE Rancher Prime v2.10.1でHarvester UI拡張を更新する
Rancher v2.10.1でSUSE Virtualization v1.4.1クラスターをインポートするには、Harvester UI拡張のv1.0.3を使用する必要があります。
-
Rancher UIで、*ローカル → アプリ → リポジトリ*に移動します。
-
harvester*という名前のリポジトリを見つけて、⋮ → 更新*を選択します。
このリポジトリには以下のプロパティがあります:
-
ブランチ: gh-pages
-
*拡張機能*画面に移動します。
-
*Harvester*という名前の拡張機能を見つけて、*更新*をクリックします。
-
バージョン*1.0.3*を選択し、*更新*をクリックします。
-
拡張機能が更新されるまでしばらく時間を置き、その後画面を更新してください。
|
Rancher UIは、拡張機能が更新された後にエラーメッセージを表示します。エラーメッセージは、画面を更新すると消えます。 この問題は、Rancher v2.10.0 および v2.10.1 に存在し、v2.10.2 で修正される予定です。 |
当バージョンの注意事項
1.アップグレードが「プレドレイン」状態で停止しています。
アップグレードプロセスは「プレドレイン」状態で停止する可能性があります。Kubernetesはノード上のワークロードを退避させることになっていますが、いくつかの要因がプロセスを停止させる可能性があります。
考えられる原因は、Longhornインスタンスマネージャーの孤児エンジンに関連するプロセスです。これがあなたの状況に当てはまるかどうかを判断するには、次の手順を実行してください:
-
停止しているノード上の`instance-manager`ポッドの名前を確認してください。
例:
停止しているノードは`harvester-node-1`で、インスタンスマネージャーポッドの名前は`instance-manager-d80e13f520e7b952f4b7593fc1883e2a`です。
$ kubectl get pods -n longhorn-system --field-selector spec.nodeName=harvester-node-1 | grep instance-manager instance-manager-d80e13f520e7b952f4b7593fc1883e2a 1/1 Running 0 3d8h -
Longhornマネージャーログに情報メッセージがあるか確認してください。
例:
$ kubectl -n longhorn-system logs daemonsets/longhorn-manager ... time="2025-01-14T00:00:01Z" level=info msg="Node instance-manager-d80e13f520e7b952f4b7593fc1883e2a is marked unschedulable but removing harvester-node-1 PDB is blocked: some volumes are still attached InstanceEngines count 1 pvc-9ae0e9a5-a630-4f0c-98cc-b14893c74f9e-e-0" func="controller.(*InstanceManagerController).syncInstanceManagerPDB" file="instance_manager_controller.go:823" controller=longhorn-instance-manager node=harvester-node-1`instance-manager`ポッドはエンジン`pvc-9ae0e9a5-a630-4f0c-98cc-b14893c74f9e-e-0`のために退避できません。
-
停止しているノード上でエンジンがまだ実行中か確認してください。
例:
$ kubectl -n longhorn-system get engines.longhorn.io pvc-9ae0e9a5-a630-4f0c-98cc-b14893c74f9e-e-0 -o jsonpath='{"Current state: "}{.status.currentState}{"\nNode ID: "}{.spec.nodeID}{"\n"}' Current state: stopped Node ID:出力にエンジンが実行されていないか、見つからないと表示されている場合、問題が存在する可能性があります。
-
すべてのボリュームが正常であるか確認してください。
kubectl get volumes -n longhorn-system -o yaml | yq '.items[] | select(.status.state == "attached")| .status.robustness'すべてのボリュームは`healthy`としてマークされている必要があります。これが当てはまらない場合は、問題を報告してください。
-
`instance-manager`ポッドのPodDisruptionBudget (PDB)を削除してください。
例:
kubectl delete pdb instance-manager-d80e13f520e7b952f4b7593fc1883e2a -n longhorn-system
2.`harvester-longhorn`ではないデフォルトのStorageClassでアップグレードします。
Harvesterは、元のデフォルトのStorageClassである`harvester-longhorn`に注釈`storageclass.kubernetes.io/is-default-class: "true"`を追加します。`harvester-longhorn`を別のStorageClassに置き換えると、次のことが発生します:
-
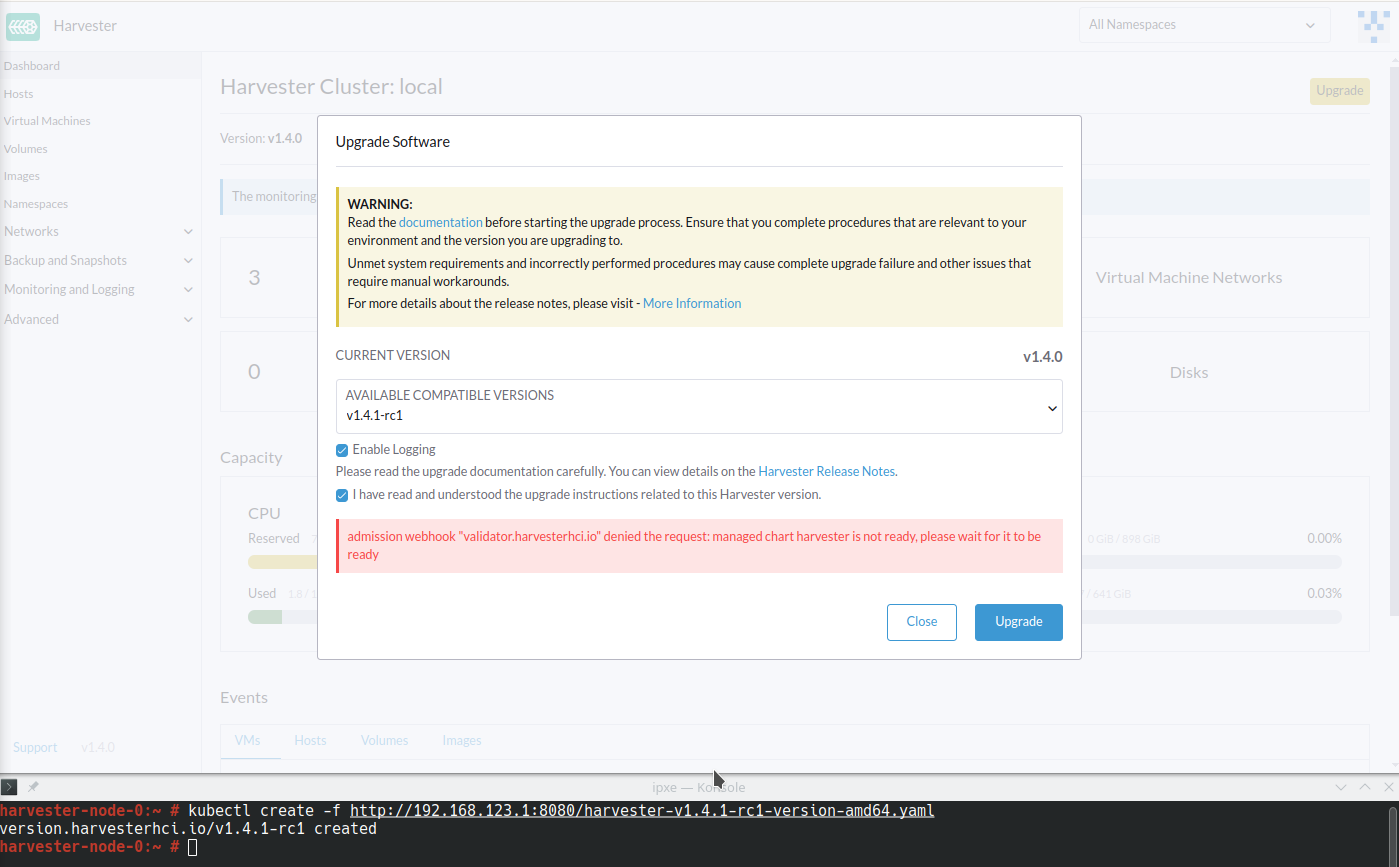
Harvester ManagedChartはエラーメッセージ`cannot patch "harvester-longhorn" with kind StorageClass: admission webhook "validator.harvesterhci.io" denied the request: default storage class %!s(MISSING) already exists, please reset it first`を表示します。
-
Webhookはアップグレードリクエストを拒否します。
以下の解決策のいずれかを使用できます:
-
`harvester-longhorn`をデフォルトのStorageClassとして設定します。
-
spec.values.storageClass.defaultStorageClass: false`を`harvesterManagedChartに追加します。kubectl edit managedchart harvester -n fleet-local -
`timeoutSeconds: 600`をHarvester ManagedChartのspecに追加します。
kubectl edit managedchart harvester -n fleet-local
関連する問題: #7375
3.アップグレードが「再起動待機」状態で停止しています。
Harvester v1.4.1イメージがノードにインストールされ、再起動が開始された後、アップグレードプロセスが「再起動待機」状態で停止する可能性があります。この時点で、アップグレードコントローラーはHarvester v1.4.1オペレーティングシステムが実行されているかどうかを確認します。
Harvester v1.4.1イメージ(以下`active.img`と呼ぶ)が何らかの理由で起動に失敗した場合、ノードは自動的にフォールバックモードで再起動し、以前にインストールされたHarvester v1.4.0イメージ(以下`passive.img`と呼ぶ)を起動します。Upgrade Controllerは期待されるオペレーティングシステムを検出できないため、管理者が`active.img`の問題を修正するまでアップグレードは停止したままになります。
アップグレード中に`COS_STATE`パーティションのディスクスペースが不足すると、`active.img`が破損して起動できなくなる可能性があります。これは、Harvester v1.4.0が元々ノードにインストールされ、システムが別のデータディスクを使用するように構成されている場合に発生します。この問題は、以下の状況では発生しません:
-
システムには、オペレーティングシステムとデータが共有する単一のディスクがあります。
-
以前のHarvesterバージョンが元々インストールされ、その後v1.4.0にアップグレードされた。
問題があなたの環境に存在するかどうかを確認するには、次の手順を実行してください。
-
SSHを介してノードにアクセスし、rootアカウントを使用してログインします。
-
コマンド`cat /proc/cmdline`と`head -n1 /etc/harvester-release.yaml`を実行します。
例:
# cat /proc/cmdline BOOT_IMAGE=(loop0)/boot/vmlinuz console=tty1 root=LABEL=COS_STATE cos-img/filename=/cOS/passive.img panic=0 net.ifnames=1 rd.cos.oemlabel=COS_OEM rd.cos.mount=LABEL=COS_OEM:/oem rd.cos.mount=LABEL=COS_PERSISTENT:/usr/local rd.cos.oemtimeout=120 audit=1 audit_backlog_limit=8192 intel_iommu=on amd_iommu=on iommu=pt multipath=off upgrade_failure # head -n1 /etc/harvester-release.yaml harvester: v1.4.0出力に`cos-img/filename=/cOS/passive.img`と`upgrade_failure`が存在する場合、システムがフォールバックモードで起動したことを示します。`/etc/harvester-release.yaml`のHarvesterバージョンは、システムが現在v1.4.0イメージを使用していることを確認します。
-
コマンド`fsck.ext2 -nf /run/initramfs/cos-state/cOS/active.img`を実行して`active.img`が破損しているかどうかを確認します。
例:
# fsck.ext2 -nf /run/initramfs/cos-state/cOS/active.img e2fsck 1.46.4 (18-Aug-2021) Pass 1: Checking inodes, blocks, and sizes Pass 2: Checking directory structure [...a list of various different errors may appear here...] e2fsck: aborted COS_ACTIVE: ********** WARNING: Filesystem still has errors ********** -
コマンド`lsblk -o NAME,LABEL,SIZE`を実行してパーティションサイズを確認します。
例:
# lsblk -o NAME,LABEL,SIZE NAME LABEL SIZE loop0 COS_ACTIVE 3G sr0 1024M vda 250G ├─vda1 COS_GRUB 64M ├─vda2 COS_OEM 64M ├─vda3 COS_RECOVERY 4G ├─vda4 COS_STATE 8G └─vda5 COS_PERSISTENT 237.9G vdb HARV_LH_DEFAULT 128G例の出力には、サイズが8Gの`COS_STATE`パーティションが表示されています。この特定のケースでは、アップグレードの試行が失敗し、`active.img`が破損しているため、パーティションにはアップグレードが成功するための十分な空き容量がなかった可能性があります。
問題を修正するには、次の手順を実行してください。
-
クラスターに2つ以上のノードがある場合、残りのノードにSSHでアクセスし、`active.img`と`passive.img`のディスク使用量を確認します。
# du -sh /run/initramfs/cos-state/cOS/* 1.7G /run/initramfs/cos-state/cOS/active.img 3.1G /run/initramfs/cos-state/cOS/passive.img`passive.img`が3.1Gのディスクスペースを消費している場合、rootアカウントを使用して次のコマンドを実行します:
# mount -o remount,rw /run/initramfs/cos-state # fallocate --dig-holes /run/initramfs/cos-state/cOS/passive.img # mount -o remount,ro /run/initramfs/cos-state`passive.img`はスパースファイルに変換され、1.7Gのディスクスペースしか消費しないはずです(`active.img`と同じです)。これにより、他のノードに十分な空き容量が確保され、アップグレードプロセスが再び停止するのを防ぎます。
-
停止したノードにSSHでアクセスし、次にrootアカウントを使用して次のコマンドを実行します:
# mount -o remount,rw /run/initramfs/cos-state # cp /run/initramfs/cos-state/cOS/passive.img \ /run/initramfs/cos-state/cOS/active.img # tune2fs -L COS_ACTIVE /run/initramfs/cos-state/cOS/active.img # mount -o remount,ro /run/initramfs/cos-state既存の(クリーンな)`passive.img`が破損した`active.img`の上にコピーされ、ラベルが正しく設定されます。
-
停止したノードを再起動し、GRUBブート画面で最初のエントリ(Harvester v1.4.1)を選択します。
GRUBブート画面は、初めに*Harvester v1.4.1 (fallback)*をデフォルトで表示します。表示されているバージョンにもかかわらず、システムはHarvester v1.4.0で起動します。
-
停止したノードの便利な場所にHarvester v1.4.1 ISOから`rootfs.squashfs`をコピーします。
ISOは、停止したノードまたは別のシステムにマウントできます。`scp`コマンドを使用してファイルをコピーできます。
-
停止したノードにSSHでアクセスし、次にルートアカウントを使用して次のコマンドを実行します:
# mkdir /tmp/manual-os-upgrade # mkdir /tmp/manual-os-upgrade/config # mkdir /tmp/manual-os-upgrade/rootfs # mount -o loop rootfs.squashfs /tmp/manual-os-upgrade/rootfs # cat > /tmp/manual-os-upgrade/config/config.yaml <<EOF upgrade: system: size: 3072 EOF # elemental upgrade \ --logfile /tmp/manual-os-upgrade/upgrade.log \ --directory /tmp/manual-os-upgrade/rootfs \ --config-dir /tmp/manual-os-upgrade/config \ --debugコピーした`rootfs.squashfs`の実際のパスに4行目のサンプルパスを置き換える必要があります。
Harvester v1.4.1 ISOのルートイメージに基づいて新しい(クリーンな)`active.img`が生成されます。
エラーが発生した場合は、`/tmp/manual-os-upgrade/upgrade.log`のコピーを保存してください。
-
次のコマンドを実行します。
# umount /tmp/manual-os-upgrade/rootfs # rebootノードはHarvester v1.4.1に正常にブートし、アップグレードは期待通りに進行するはずです。
4.「Dismiss it」ボタンがクリックされた後、アップグレードが予期せず再起動します。
Rancherを使用してSUSE Virtualizationをアップグレードすると、Rancher UIに「Dismiss it」とラベル付けされたボタンを含むダイアログが表示されます。このボタンをクリックすると、次の問題が発生する可能性があります:
-
harvesterhci.io/v1beta1/upgradeCRの`status`セクションがクリアされ、アップグレードに関するすべての重要な情報が失われます。 -
アップグレードプロセスが予期せず再起動します。
この問題は、v1.0.2、v1.0.3、およびv1.0.4のHarvester UI Extensionを使用するRancher v2.10.xに影響します。すべてのSUSE Virtualization UIバージョンには影響しません。この問題はHarvester UI Extension v1.0.5およびv1.5.0で修正されています。
この問題を回避するには、次のいずれかのアクションを実行してください:
-
アップグレードにはSUSE Virtualization UIを使用してください。SUSE Virtualization UIの「Dismiss it」ボタンをクリックしても、予期しない動作は発生しません。
-
Rancher UI上のボタンをクリックする代わりに、クラスターに対して次のコマンドを実行してください。
kubectl -n harvester-system label upgrades -l harvesterhci.io/latestUpgrade=true harvesterhci.io/read-message=true
関連する問題: #7791
5.移行可能なRWXボリュームを使用する仮想マシンが予期せず再起動します。
移行可能なRWXボリュームを使用する仮想マシンは、CSIプラグインポッドが再起動されると予期せず再起動します。この問題は、SUSE Virtualization v1.4.x、v1.5.0、およびv1.5.1に影響します。
アップグレードを開始する前に、SUSE Storage UIで設定 ボリュームが予期せず切り離されたときにワークロードポッドを自動的に削除する を無効にすることが回避策です。アップグレードが完了したら、再度設定を有効にする必要があります。
この問題は、SUSE Storage v1.8.3、v1.9.1、およびそれ以降のバージョンで修正されます。SUSE Virtualization v1.6.0 には SUSE Storage v1.9.1 が含まれます。