Nó de Testemunha
SUSE Virtualization clusters implantados em ambientes de produção requerem um plano de controle para gerenciamento de nós e pods. Um cluster típico de três nós possui três nós de gerenciamento que contêm cada um o conjunto completo de componentes do plano de controle. Um componente-chave é o etcd, que o Kubernetes usa para armazenar os dados (configuração, estado e metadados). A contagem de nós etcd deve sempre ser um número ímpar (por exemplo, 3 é a contagem padrão em SUSE Virtualization) para garantir que um quórum seja mantido.
Algumas situações podem exigir que você evite implantar cargas de trabalho e dados de usuários em nós de gerenciamento. Nessas situações, um nó do cluster pode ser designado para o papel de witness, o que limita sua função a membro do cluster etcd. O nó de testemunha é responsável por estabelecer um quórum de membros (uma maioria de nós), que deve concordar com as atualizações do estado do cluster.
Os nós de testemunha não armazenam nenhum dado, mas as recomendações de hardware para nós etcd ainda devem ser consideradas. Usar hardware com recursos limitados afeta significativamente o desempenho do cluster, conforme descrito no artigo Desempenho lento do etcd (testes de desempenho e otimização).
SUSE Virtualization suporta clusters com dois nós de gerenciamento e um nó de testemunha (e opcionalmente, um ou mais nós de trabalho). Para mais informações sobre papéis de nós, veja Gerenciamento de Papéis.
|
Um nó pode ser designado para o papel de witness apenas no momento em que se junta a um cluster. Cada cluster pode ter apenas um nó de testemunha. |
Criando um SUSE Virtualization Cluster com um Nó de Testemunha
Você pode designar o papel de witness a um nó quando ele se junta a um cluster recém-criado.
No exemplo a seguir, um cluster com três nós foi criado e o nó harvester-node-1 foi designado para o papel de witness. harvester-node-1 consome menos recursos e possui apenas capacidades do etcd.
NAME↑ STATUS ROLE VERSION PODS CPU MEM %CPU %MEM CPU/A MEM/A AGE harvester-node-0 Ready control-plane,etcd,master v1.27.10+rke2r1 70 1095 10143 10 63 10000 15976 4d13h harvester-node-1 Ready etcd v1.27.10+rke2r1 7 258 2258 2 14 10000 15976 4d13h harvester-node-2 Ready control-plane,etcd,master v1.27.10+rke2r1 36 840 6905 8 43 10000 15976 4d13h
Como o cluster deve ter três nós, o controlador de promoção promoverá os outros dois nós. Depois disso, o cluster terá dois nós de plano de controle e um nó de testemunha.
Cargas de trabalho no Nó Testemunha
O nó testemunha executa apenas as seguintes cargas de trabalho essenciais:
-
harvester-node-manager
-
cloud-controller-manager
-
etcd
-
kube-proxy
-
rke2-canal
-
rke2-multus
Fazer upgrade de um Cluster com um Nó Testemunha
Os requisitos e procedimentos gerais de upgrade se aplicam a clusters com um nó de testemunha. No entanto, a existência de volumes degradados em tais clusters pode causar falhas nas operações de upgrade.
Réplicas do Longhorn em Clusters com um Nó de Testemunha
SUSE Virtualization utiliza o Longhorn, um sistema de armazenamento em blocos distribuído, para gerenciamento de volumes de dispositivos de armazenamento em blocos. O Longhorn é provisionado para nós de gerenciamento e de trabalho, mas não para nós de testemunha, que não armazenam dados.
O Longhorn cria réplicas de cada volume para aumentar a disponibilidade. As réplicas contêm uma cadeia de instantâneos do volume, com cada instantâneo armazenando a alteração em relação a um instantâneo anterior. Em SUSE Virtualization, a StorageClass padrão harvester-longhorn tem um valor de contagem de réplicas de 3.
Limitações
Os nós de testemunha não armazenam dados. Isso significa que em clusters de três nós (sem nós de trabalho), apenas duas réplicas são criadas para cada volume do Longhorn. No entanto, a StorageClass padrão harvester-longhorn tem um valor de contagem de réplicas de 3 para alta disponibilidade. Se você usar esta StorageClass para criar volumes, o Longhorn não consegue criar o número configurado de réplicas. Isso resulta em volumes sendo marcados como Degradado na interface do Longhorn.
Em resumo, você deve usar uma StorageClass que corresponda à configuração do cluster.
-
2 nós de gerenciamento + 1 nó de testemunha: Crie uma nova StorageClass padrão com o parâmetro Número de Réplicas definido como 2. Isso garante que apenas duas réplicas sejam criadas para cada volume do Longhorn.
-
2 nós de gerenciamento + 1 nó de testemunha + 1 ou mais nós de trabalho: Você pode usar a StorageClass padrão existente.
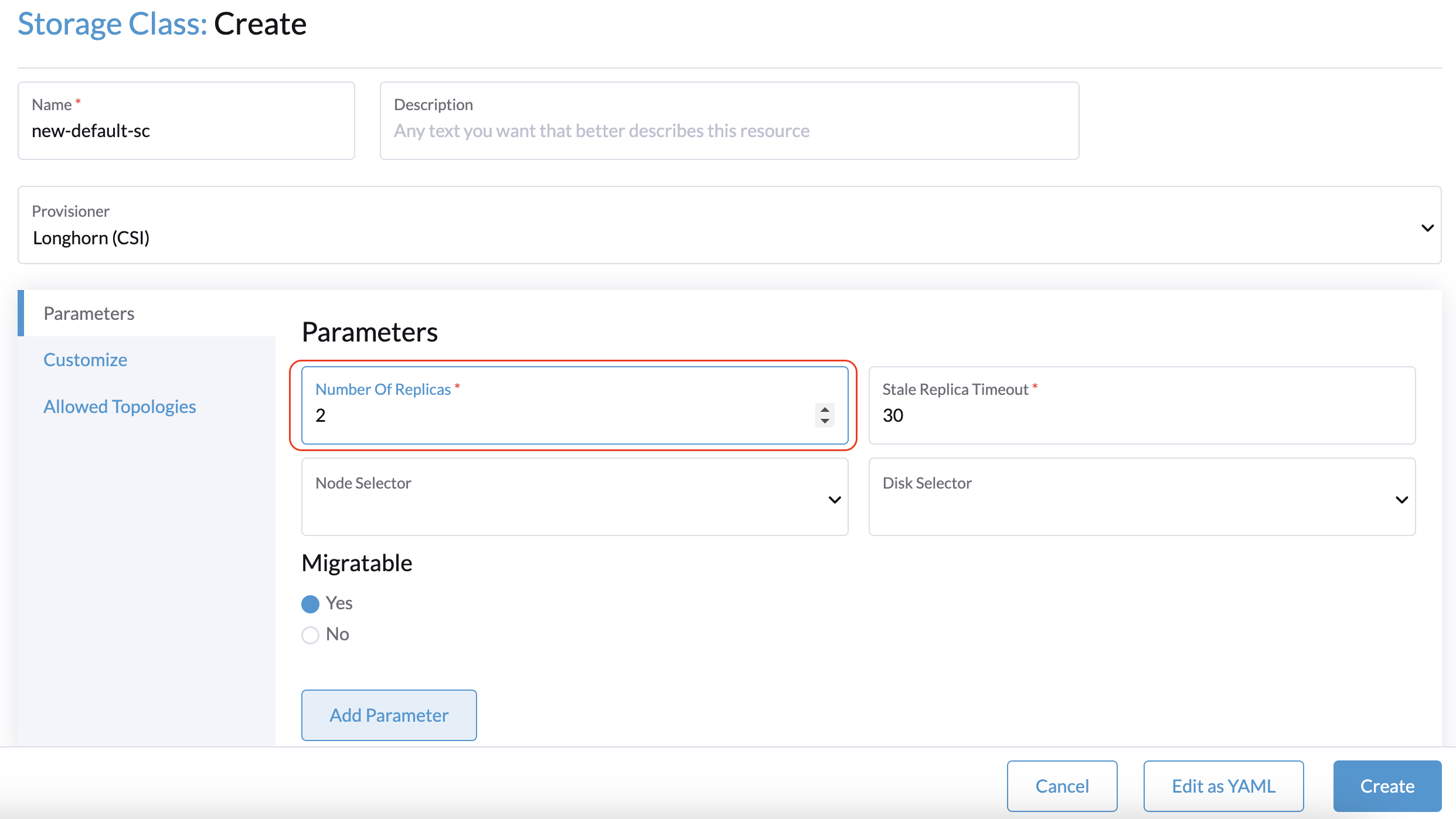
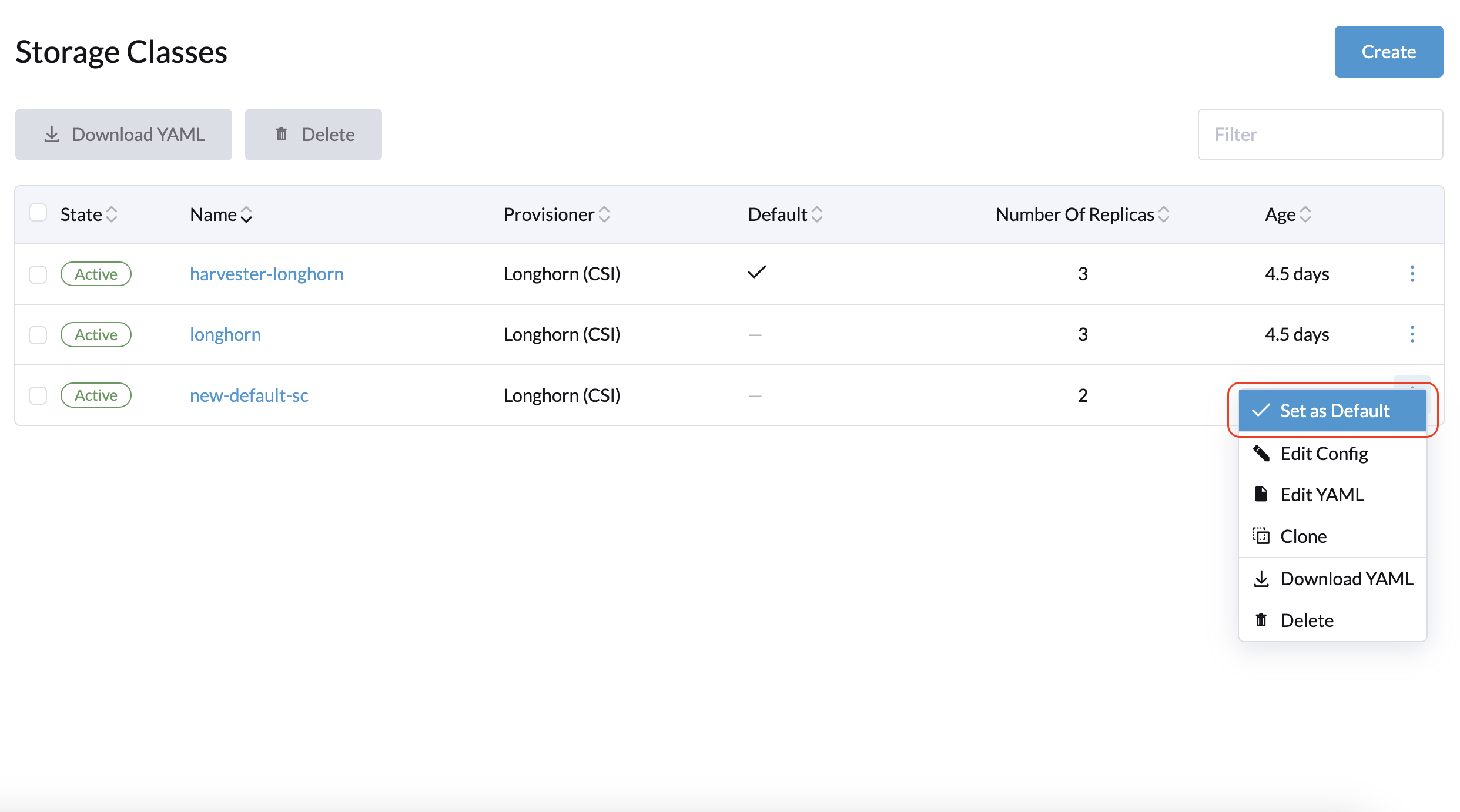
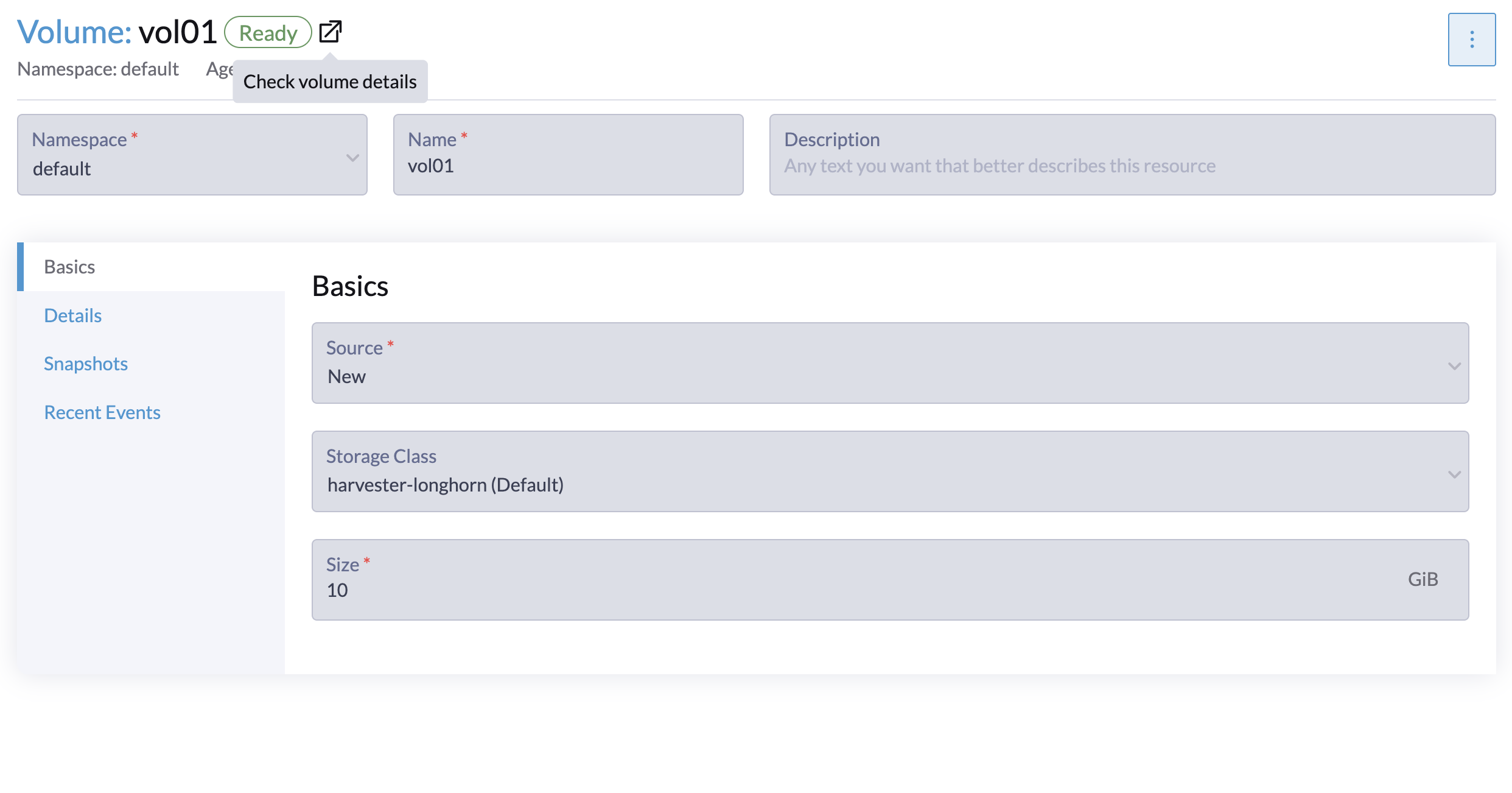
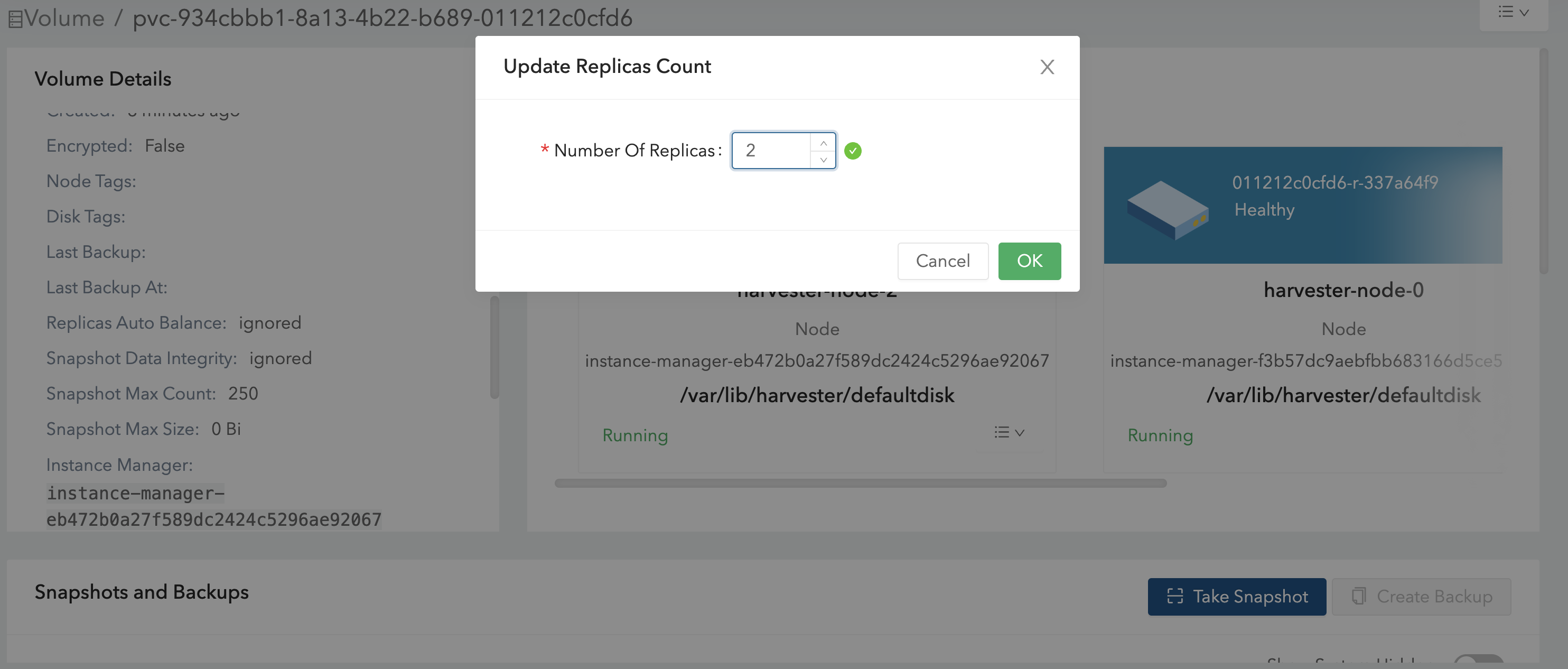
Se você já criou volumes usando a StorageClass padrão original, pode modificar a contagem de réplicas na tela Volume da interface Longhorn incorporada.
Problemas conhecidos
1. Ao criar um cluster com um nó de testemunha, a Configuração de Rede: A tela de criação na interface SUSE Virtualization não consegue identificar nenhuma NIC que possa ser usada com todos os nós.
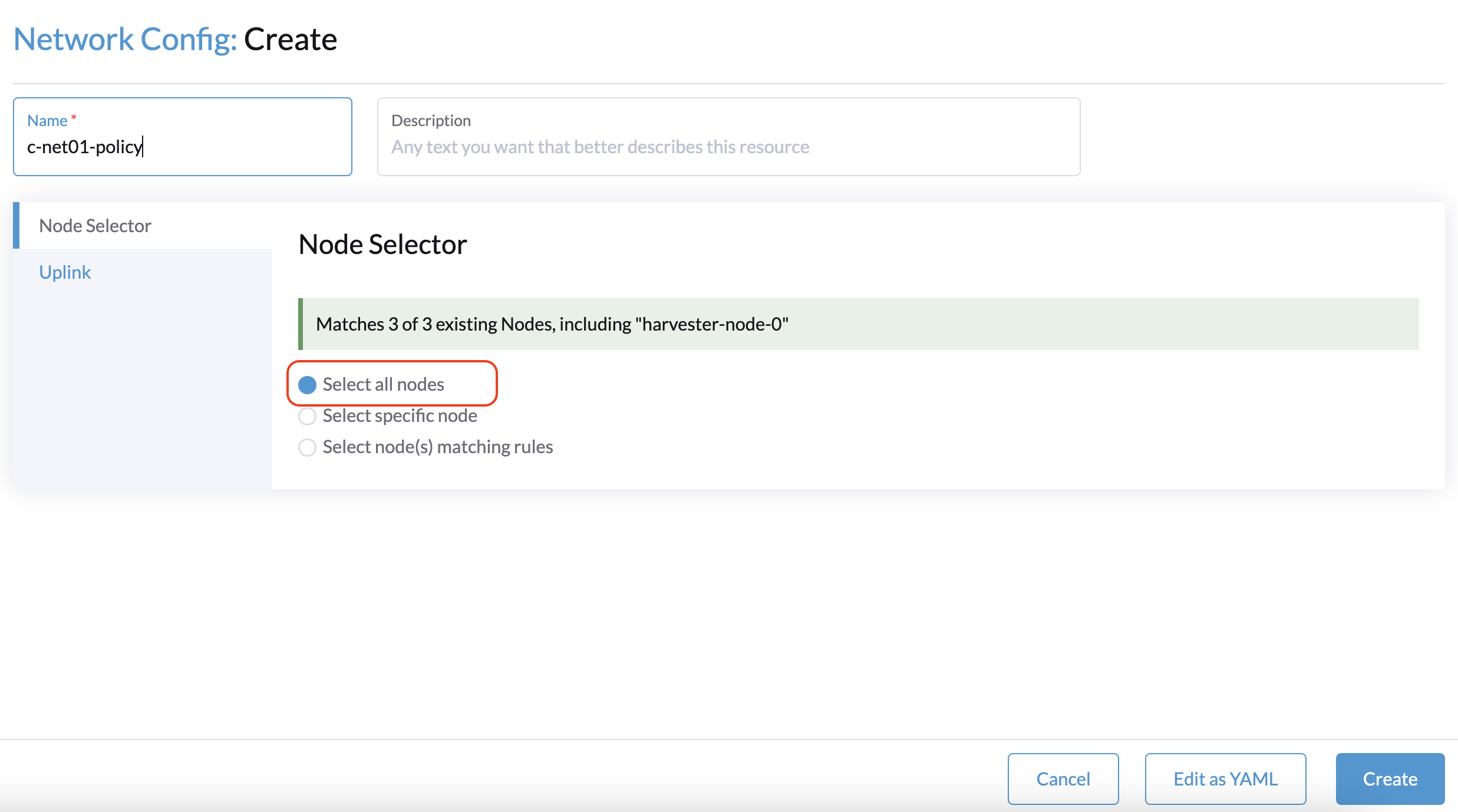
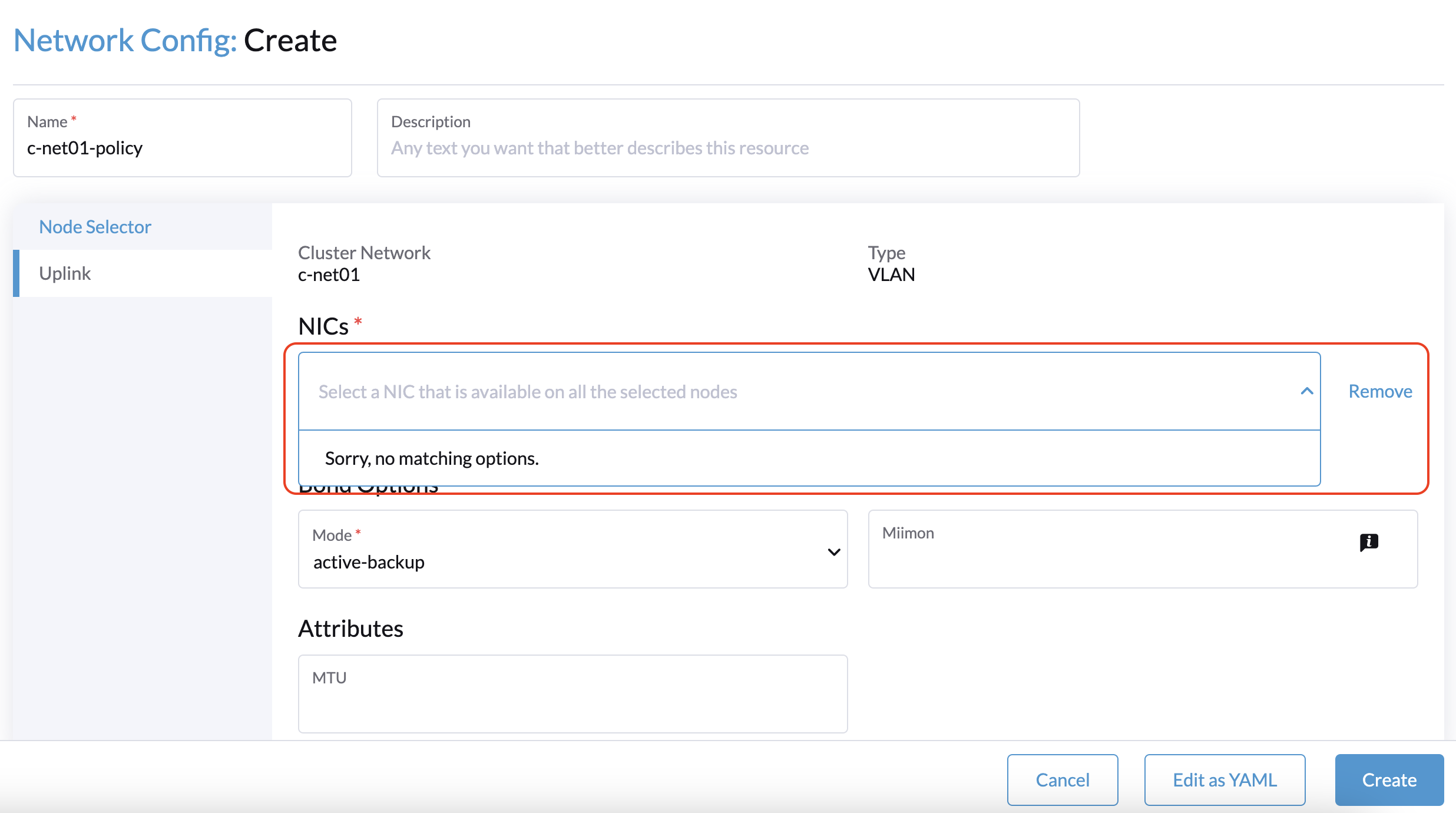
A solução alternativa é selecionar um nó que não seja de testemunha e, em seguida, selecionar uma NIC que possa ser usada com esse nó específico.
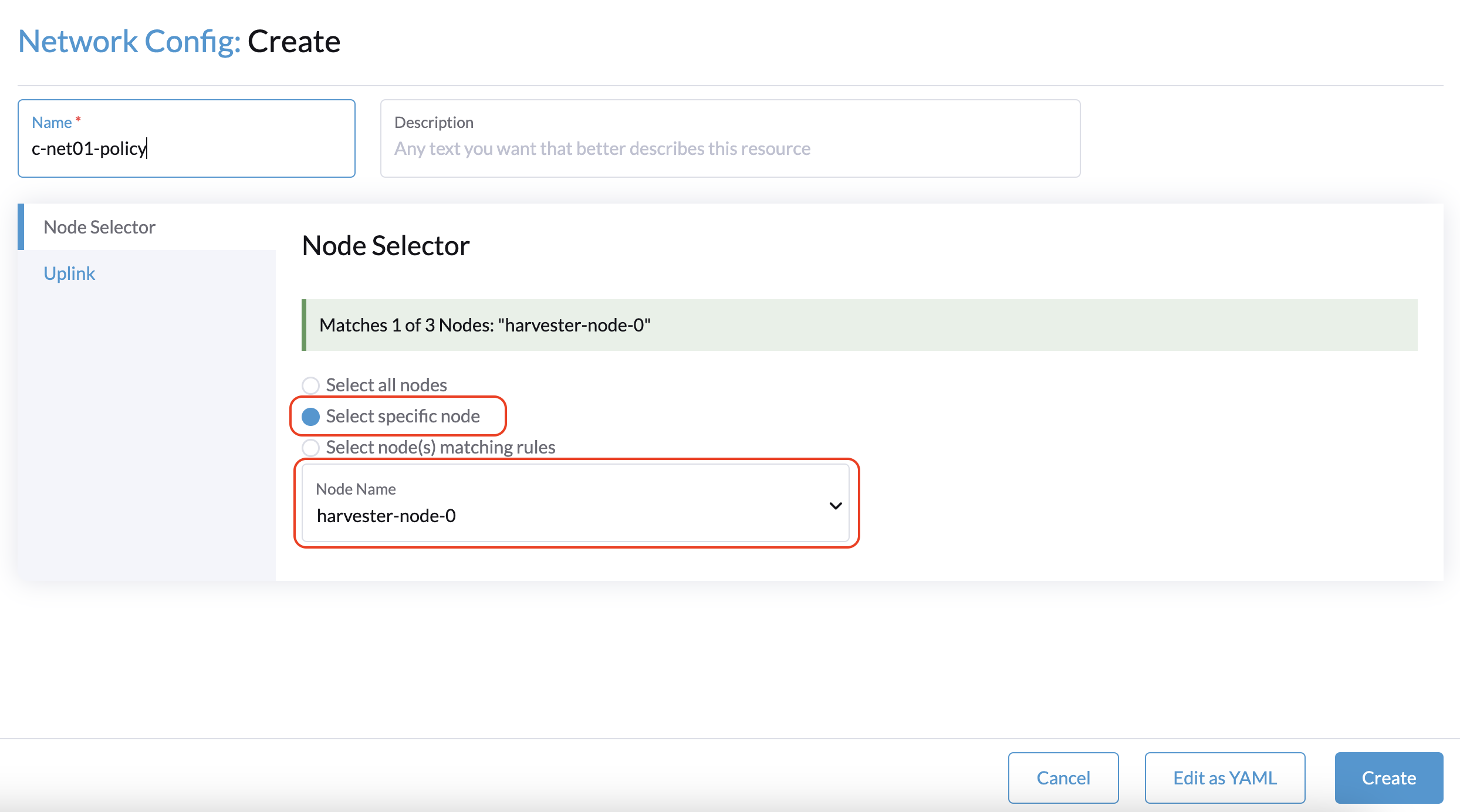
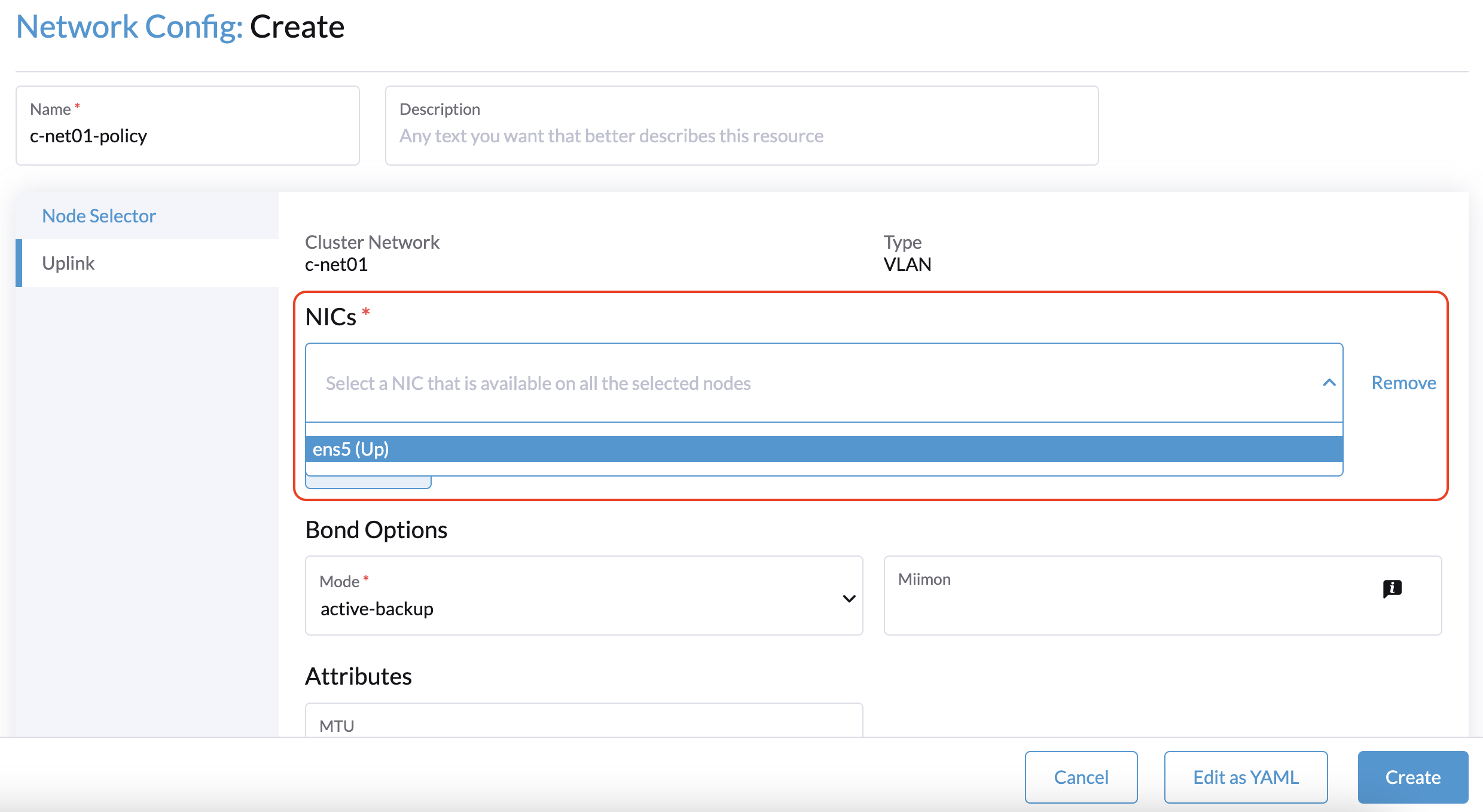
Você deve repetir este procedimento para cada nó que não seja de testemunha no cluster. As mesmas configurações de uplink podem ser usadas entre os nós.
2. Ao selecionar um nó de destino para migração de VM, a lista de destinos inclui o nó de testemunha.
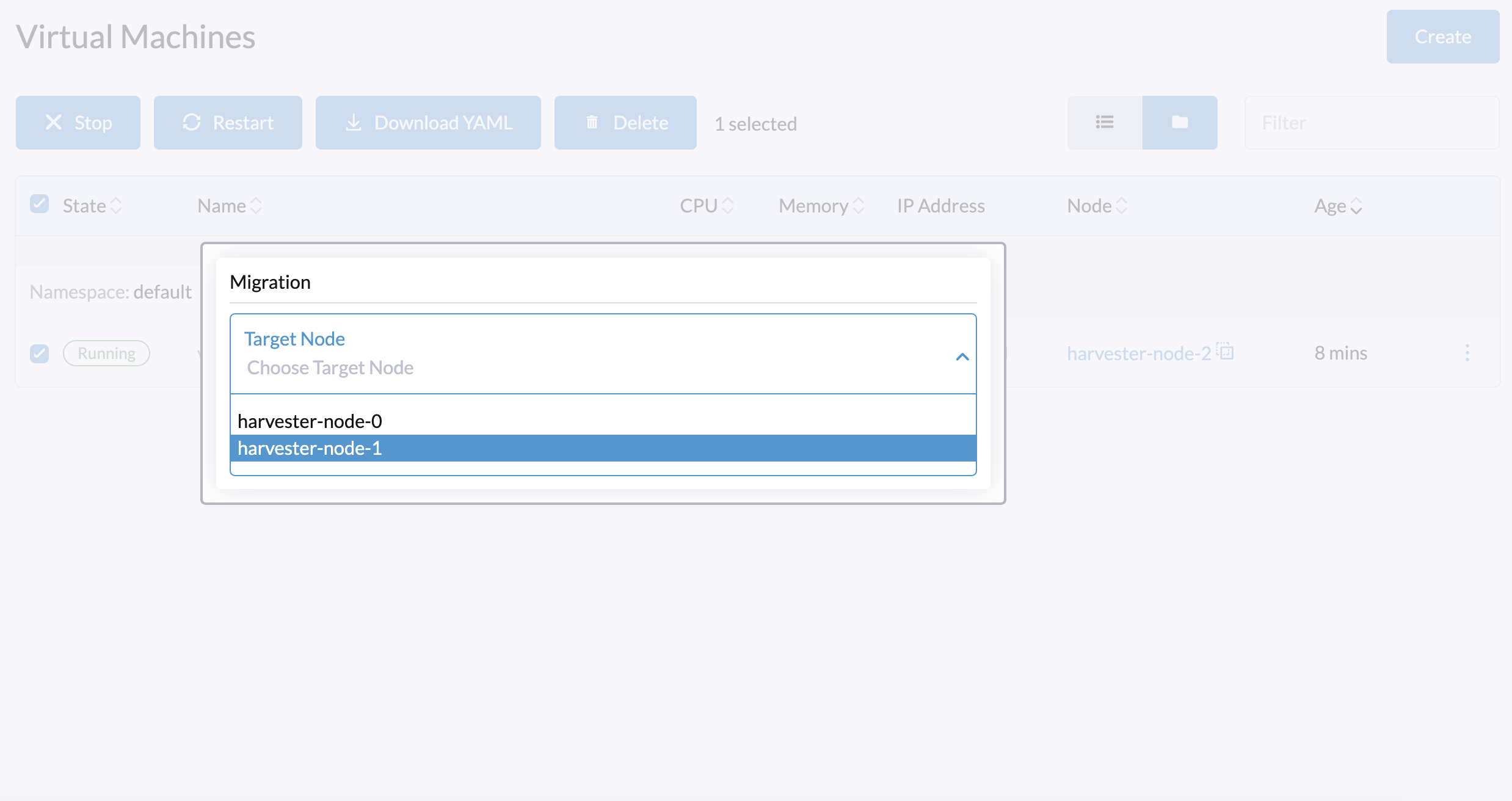
Não selecione o nó de testemunha como o destino da migração. Se você fizer isso, a migração da VM falhará.
Problema relacionado: [BUG] O nó de testemunha não deve ser selecionado como um destino de migração