|
Este documento foi traduzido usando tecnologia de tradução automática de máquina. Sempre trabalhamos para apresentar traduções precisas, mas não oferecemos nenhuma garantia em relação à integridade, precisão ou confiabilidade do conteúdo traduzido. Em caso de qualquer discrepância, a versão original em inglês prevalecerá e constituirá o texto official. |
Fazer upgrade da v1.4.2 ou v1.4.3 para v1.5.2
Informações gerais
Um botão Fazer upgrade aparece na tela Dashboard sempre que uma nova versão SUSE Virtualization para a qual você pode fazer upgrade se torna disponível. Para mais informações, veja Iniciar um upgrade.
Você pode fazer upgrade diretamente da v1.4.2 para a v1.5.2 porque SUSE Virtualization permite um máximo de um upgrade de versão menor para componentes subjacentes. A v1.4.2 e a v1.4.3 usam a mesma versão menor de RKE2 (v1.31), enquanto a v1.5.0, v1.5.1 e v1.5.2 usam a próxima versão menor (v1.32).
Para informações sobre como fazer upgrade do SUSE Virtualization em ambientes air-gapped, veja Preparar um upgrade em ambiente air-gapped.
Atualize a extensão da UI do Harvester na SUSE Rancher Prime v2.11.0
Você deve usar v1.5.2 da Extensão da UI do Harvester para importar clusters SUSE Virtualization v1.5.2 na Rancher v2.11.0.
-
Na UI do Rancher, vá para local → Apps → Repositórios.
-
Localize o repositório chamado harvester, e então selecione ⋮ → Atualizar.
-
Vá para a tela Extensões.
-
Localize a extensão chamada Harvester, e então clique em Atualizar.
-
Selecione a versão 1.5.2, e então clique em Atualizar.
-
Permita algum tempo para que a extensão seja atualizada, e então atualize a tela.
Problemas conhecidos
O upgrade air-gapped travou com erro ImagePullBackOff nos pods do Fluentd e do Fluent Bit
O upgrade pode travar logo no início do processo, como indicado por 0% de progresso e itens marcados como Pendente na caixa de diálogo Upgrade da UI do SUSE Virtualization
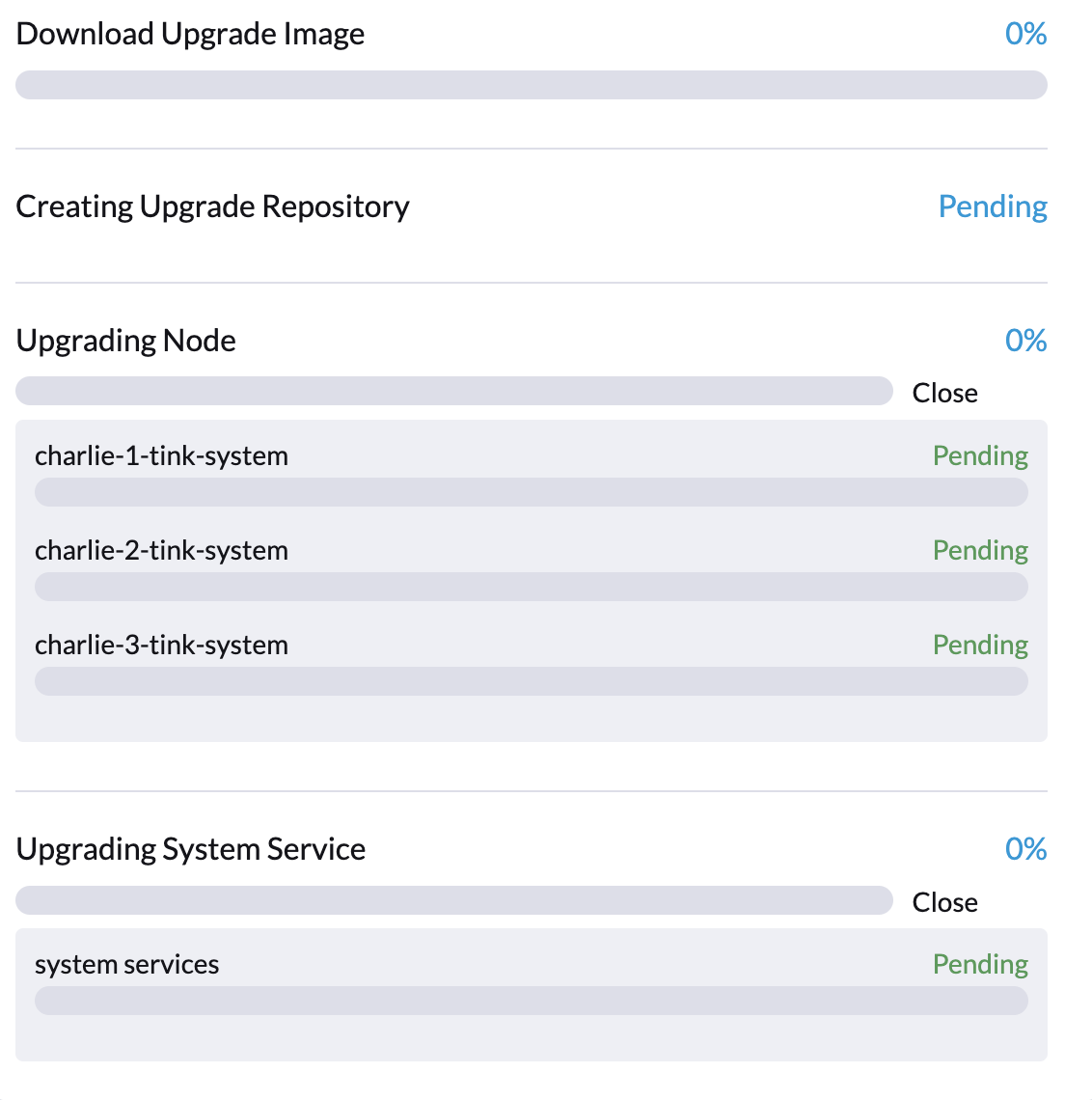
Especificamente, os pods do Fluentd e do Fluent Bit podem ficar travados no status ImagePullBackOff. Para verificar o status dos pods, execute os seguintes comandos:
$ kubectl -n harvester-system get upgrades -l harvesterhci.io/latestUpgrade=true
NAME AGE
hvst-upgrade-x2hz8 7m14s
$ kubectl -n harvester-system get upgradelogs -l harvesterhci.io/upgrade=hvst-upgrade-x2hz8
NAME UPGRADE
hvst-upgrade-x2hz8-upgradelog hvst-upgrade-x2hz8
$ kubectl -n harvester-system get pods -l harvesterhci.io/upgradeLog=hvst-upgrade-x2hz8-upgradelog
NAME READY STATUS RESTARTS AGE
hvst-upgrade-x2hz8-upgradelog-downloader-6cdb864dd9-6bw98 1/1 Running 0 7m7s
hvst-upgrade-x2hz8-upgradelog-infra-fluentbit-2nq7q 0/1 ImagePullBackOff 0 7m42s
hvst-upgrade-x2hz8-upgradelog-infra-fluentbit-697wf 0/1 ImagePullBackOff 0 7m42s
hvst-upgrade-x2hz8-upgradelog-infra-fluentbit-kd8kl 0/1 ImagePullBackOff 0 7m42s
hvst-upgrade-x2hz8-upgradelog-infra-fluentd-0 0/2 ImagePullBackOff 0 7m42sIsso ocorre porque as seguintes imagens de contêiner não estão pré-carregadas nos nós do cluster nem baixadas da internet:
-
ghcr.io/kube-logging/fluentd:v1.15-ruby3 -
ghcr.io/kube-logging/config-reloader:v0.0.5 -
fluent/fluent-bit:2.1.8
Para corrigir o problema, execute qualquer uma das seguintes ações:
-
Atualize o CR de Logging para usar as imagens que já estão pré-carregadas nos nós do cluster. Para fazer isso, execute os seguintes comandos no cluster:
# Get the Logging CR names OPERATOR_LOGGING_NAME=$(kubectl get loggings -l app.kubernetes.io/name=rancher-logging -o jsonpath="{.items[0].metadata.name}") INFRA_LOGGING_NAME=$(kubectl get loggings -l harvesterhci.io/upgradeLogComponent=infra -o jsonpath="{.items[0].metadata.name}") # Gather image info from operator's Logging CR FLUENTD_IMAGE_REPO=$(kubectl get loggings $OPERATOR_LOGGING_NAME -o jsonpath="{.spec.fluentd.image.repository}") FLUENTD_IMAGE_TAG=$(kubectl get loggings $OPERATOR_LOGGING_NAME -o jsonpath="{.spec.fluentd.image.tag}") FLUENTBIT_IMAGE_REPO=$(kubectl get loggings $OPERATOR_LOGGING_NAME -o jsonpath="{.spec.fluentbit.image.repository}") FLUENTBIT_IMAGE_TAG=$(kubectl get loggings $OPERATOR_LOGGING_NAME -o jsonpath="{.spec.fluentbit.image.tag}") CONFIG_RELOADER_IMAGE_REPO=$(kubectl get loggings $OPERATOR_LOGGING_NAME -o jsonpath="{.spec.fluentd.configReloaderImage.repository}") CONFIG_RELOADER_IMAGE_TAG=$(kubectl get loggings $OPERATOR_LOGGING_NAME -o jsonpath="{.spec.fluentd.configReloaderImage.tag}") # Patch the Logging CR kubectl patch logging $INFRA_LOGGING_NAME --type=json -p="[{\"op\":\"replace\",\"path\":\"/spec/fluentbit/image\",\"value\":{\"repository\":\"$FLUENTBIT_IMAGE_REPO\",\"tag\":\"$FLUENTBIT_IMAGE_TAG\"}}]" kubectl patch logging $INFRA_LOGGING_NAME --type=json -p="[{\"op\":\"replace\",\"path\":\"/spec/fluentd/image\",\"value\":{\"repository\":\"$FLUENTD_IMAGE_REPO\",\"tag\":\"$FLUENTD_IMAGE_TAG\"}}]" kubectl patch logging $INFRA_LOGGING_NAME --type=json -p="[{\"op\":\"replace\",\"path\":\"/spec/fluentd/configReloaderImage\",\"value\":{\"repository\":\"$CONFIG_RELOADER_IMAGE_REPO\",\"tag\":\"$CONFIG_RELOADER_IMAGE_TAG\"}}]"O status dos pods do Fluentd e do Fluent Bit deve mudar para
Runningem breve e o processo de upgrade deve continuar após a atualização do CR de Logging. Se o status do pod Fluentd ainda estiverImagePullBackOff, você pode excluir o pod para forçá-lo a reiniciar.UPGRADE_NAME=$(kubectl -n harvester-system get upgrades -l harvesterhci.io/latestUpgrade=true -o jsonpath='{.items[0].metadata.name}') UPGRADELOG_NAME=$(kubectl -n harvester-system get upgradelogs -l harvesterhci.io/upgrade=$UPGRADE_NAME -o jsonpath='{.items[0].metadata.name}') kubectl -n harvester-system delete pods -l harvesterhci.io/upgradeLog=$UPGRADELOG_NAME,harvesterhci.io/upgradeLogComponent=aggregator -
Em um computador com acesso à internet, baixe as imagens de contêiner necessárias e, em seguida, exporte-as para um arquivo TAR. Em seguida, transfira o arquivo TAR para os nós do cluster e importe as imagens executando os seguintes comandos em cada nó:
# Pull down the three container images docker pull ghcr.io/kube-logging/fluentd:v1.15-ruby3 docker pull ghcr.io/kube-logging/config-reloader:v0.0.5 docker pull fluent/fluent-bit:2.1.8 # Export the images to a tar file docker save \ ghcr.io/kube-logging/fluentd:v1.15-ruby3 \ ghcr.io/kube-logging/config-reloader:v0.0.5 \ fluent/fluent-bit:2.1.8 > upgradelog-images.tar # After transferring the tar file to the cluster nodes, import the images (need to be run on each node) ctr -n k8s.io images import upgradelog-images.tarO processo de upgrade deve continuar após as imagens serem pré-carregadas.
-
(Não recomendado) Reinicie o processo de upgrade com o logging desativado. Certifique-se de que a caixa de seleção Ativar Logging na caixa de diálogo Upgrade não esteja selecionada.
-
Problema relacionado: #7955
Máquinas virtuais que usam volumes RWX migráveis reiniciam inesperadamente
Máquinas virtuais que usam volumes RWX migráveis reiniciam inesperadamente quando os pods do plugin CSI são reiniciados. Esse problema afeta SUSE Virtualization v1.4.x, v1.5.0 e v1.5.1.
A solução alternativa é desativar a configuração Excluir Automaticamente o Pod de Trabalho Quando o Volume for Desconectado Inesperadamente na UI SUSE Storage antes de fazer o upgrade. Você deve habilitar a configuração novamente assim que o upgrade for concluído.
O problema será corrigido na versão SUSE Storage v1.8.3, v1.9.1 e versões posteriores. A versão SUSE Virtualization v1.6.0 incluirá SUSE Storage v1.9.1.