Solução de problemas
Visão Geral
Aqui estão algumas dicas para solucionar uma falha no fazer upgrade:
-
Verifique notas de fazer upgrade específicas da versão. Você pode clicar na versão na tabela da matriz de suporte para ver se há problemas conhecidos.
-
Aprofunde-se no proposta de design do fazer upgrade. A seção a seguir descreve brevemente as fases dentro do fazer upgrade e possíveis métodos de diagnóstico.
Fluxo do fazer upgrade
O processo de fazer upgrade inclui várias fases.
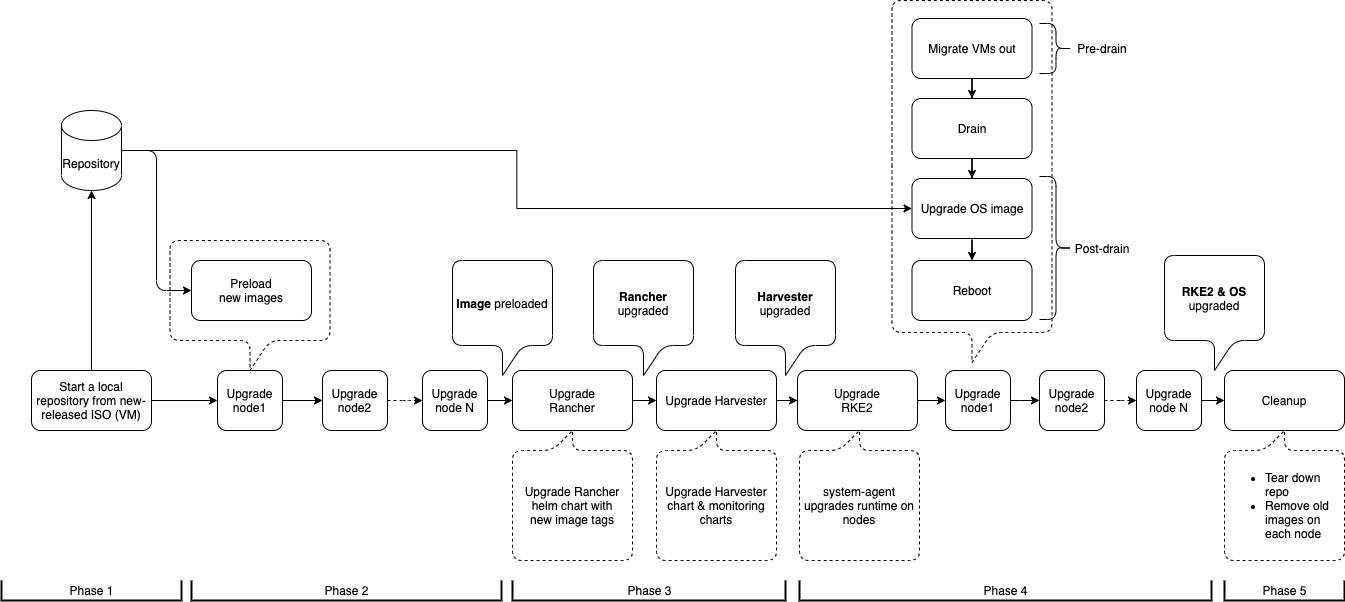
Fase 1: Provisionar máquina virtual do repositório de fazer upgrade
O controlador SUSE Virtualization baixa um arquivo ISO de lançamento e o utiliza para provisionar uma máquina virtual do repositório de fazer upgrade. O nome da máquina virtual usa o formato upgrade-repo-hvst-xxxx.
A velocidade da rede e a utilização de recursos do cluster influenciam o tempo necessário para concluir esta fase. Os fazer upgrades geralmente falham devido a problemas de velocidade da rede.
Se o fazer upgrade falhar neste ponto, verifique o status da máquina virtual do repositório e seu pod correspondente antes de reiniciar o fazer upgrade. Você pode verificar o status usando o comando kubectl get vm -n harvester-system.
Exemplo:
$ kubectl get vm -n harvester-system
NAME AGE STATUS READY
upgrade-repo-hvst-upgrade-9gmg2 101s Starting False
$ kubectl get pods -n harvester-system | grep upgrade-repo-hvst
virt-launcher-upgrade-repo-hvst-upgrade-9gmg2-4mnmq 1/1 Running 0 4m44sFase 2: Pré-carregar imagens de contêiner
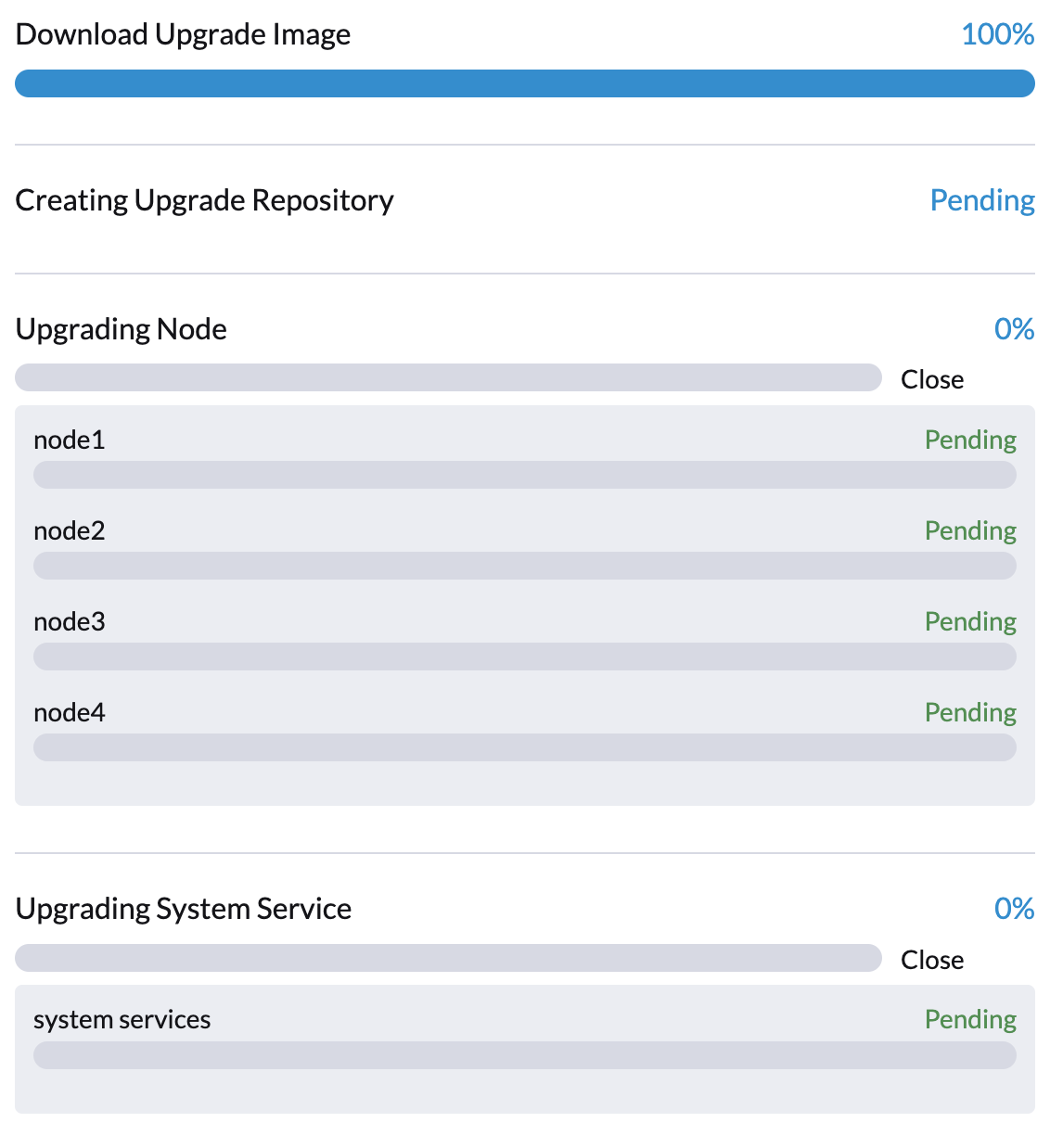
O controlador SUSE Virtualization cria tarefas que baixam e pré-carregam imagens de contêiner da máquina virtual do repositório de fazer upgrade. Essas imagens são necessárias para o próximo fazer upgrade.
Permita algum tempo para que as imagens sejam baixadas e pré-carregadas em todos os nodes.

Se o fazer upgrade falhar neste ponto, verifique os logs das tarefas no namespace cattle-system antes de reiniciar o fazer upgrade. Você pode verificar os logs usando o comando kubectl get jobs -n cattle-system | grep prepare.
Exemplo:
$ kubectl get jobs -n cattle-system | grep prepare
apply-hvst-upgrade-9gmg2-prepare-on-node1-with-2bbea1599a-f0e86 0/1 47s 47s
apply-hvst-upgrade-9gmg2-prepare-on-node4-with-2bbea1599a-041e4 1/1 2m3s 2m50s
$ kubectl logs jobs/apply-hvst-upgrade-9gmg2-prepare-on-node1-with-2bbea1599a-f0e86 -n cattle-system
...Fase 3: Atualizar serviços do sistema
O controlador SUSE Virtualization cria uma tarefa que faz o fazer upgrade dos Helm charts dos componentes.
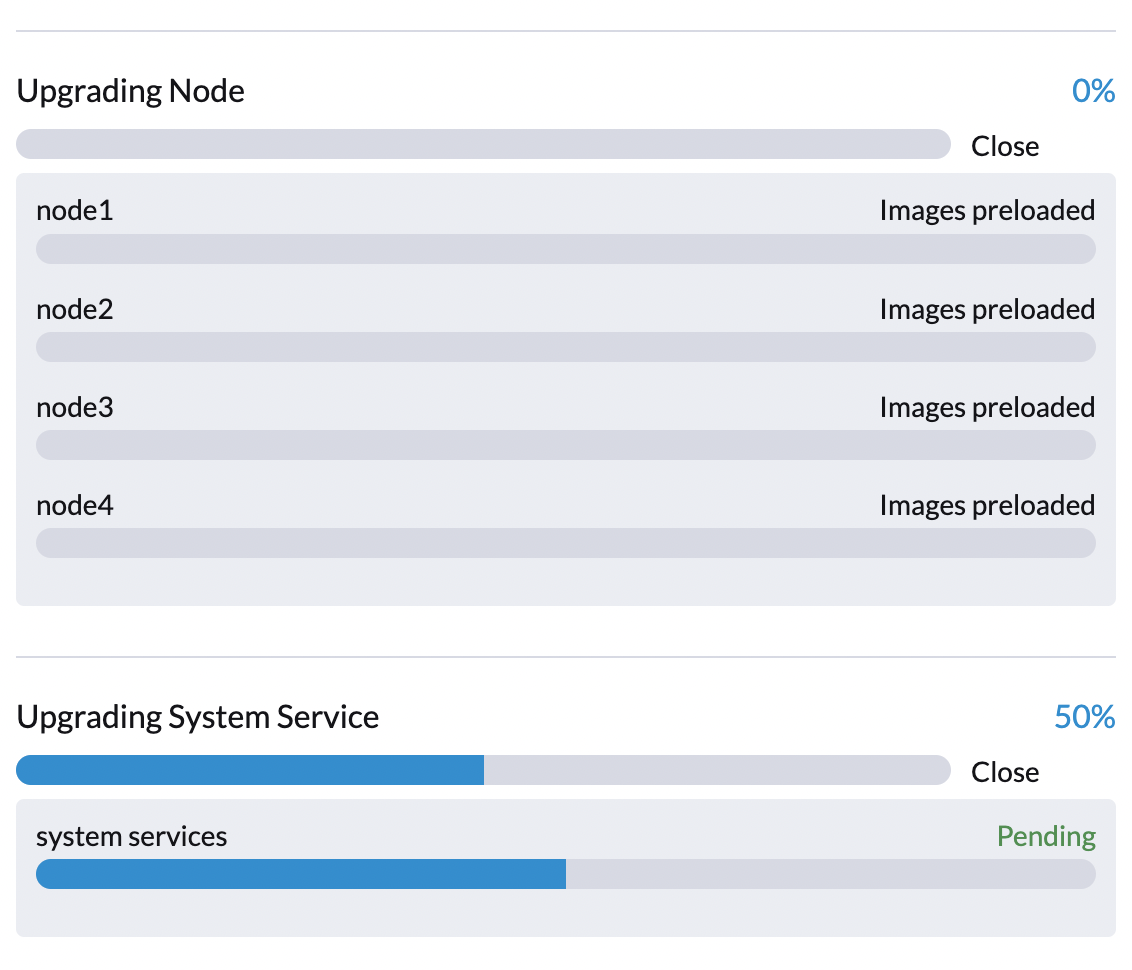
Você pode verificar a tarefa apply-manifest usando o comando $ kubectl get jobs -n harvester-system -l harvesterhci.io/upgradeComponent=manifest.
Exemplo:
$ kubectl get jobs -n harvester-system -l harvesterhci.io/upgradeComponent=manifest
NAME COMPLETIONS DURATION AGE
hvst-upgrade-9gmg2-apply-manifests 0/1 46s 46s
$ kubectl logs jobs/hvst-upgrade-9gmg2-apply-manifests -n harvester-system
...|
Se o fazer upgrade falhar neste ponto, você deve gerar um pacote de suporte antes de reiniciar o fazer upgrade. O pacote de suporte contém logs e manifestos de recursos que podem ajudar a identificar a causa da falha. |
Fase 4: Atualizar nodes
O controlador SUSE Virtualization cria as seguintes tarefas em cada node:
-
Clusters de múltiplos nodes:
-
Tarefa
pre-drain: Realiza a migração ao vivo ou desliga máquinas virtuais no node. Uma vez concluído, o serviço Rancher embutido faz o fazer upgrade do runtime RKE2 no node. -
Tarefa
post-drain: Faz o fazer upgrade e reinicia o sistema operacional.
-
-
Clusters de um único node:
-
Tarefa
single-node-upgrade: Faz o fazer upgrade do sistema operacional e do runtime RKE2. O nome da tarefa usa o formatohvst-upgrade-xxx-single-node-upgrade-<hostname>.
-

Você pode verificar as tarefas em execução em cada node executando o comando kubectl get jobs -n harvester-system -l harvesterhci.io/upgradeComponent=node.
Exemplo:
$ kubectl get jobs -n harvester-system -l harvesterhci.io/upgradeComponent=node
NAME COMPLETIONS DURATION AGE
hvst-upgrade-9gmg2-post-drain-node1 1/1 118s 6m34s
hvst-upgrade-9gmg2-post-drain-node2 0/1 9s 9s
hvst-upgrade-9gmg2-pre-drain-node1 1/1 3s 8m14s
hvst-upgrade-9gmg2-pre-drain-node2 1/1 7s 85s
$ kubectl logs -n harvester-system jobs/hvst-upgrade-9gmg2-post-drain-node2
...|
Se o fazer upgrade falhar neste ponto, não reinicie o fazer upgrade a menos que instruído por SUSE Support. |
Operações comuns
Reiniciar o fazer upgrade
|
Se o fazer upgrade em andamento falhar ou ficar preso em [Phase 4: Upgrade nodes], não reinicie o fazer upgrade, a menos que instruído por SUSE Support. |
-
Gere um pacote de suporte.
-
Clique no botão Atualizar na tela Dashboard.
Se você personalizou a versão, pode ser necessário criar o objeto de versão novamente.
Pare o fazer upgrade em andamento
|
Se o fazer upgrade em andamento falhar ou ficar preso em [Phase 4: Upgrade nodes], identifique a causa primeiro. |
Você pode parar o fazer upgrade realizando os seguintes passos:
-
Faça login em um nó do plano de controle.
-
Recupere uma lista de
UpgradeCRs no cluster.# become root $ sudo -i # list the on-going upgrade $ kubectl get upgrade.harvesterhci.io -n harvester-system -l harvesterhci.io/latestUpgrade=true NAME AGE hvst-upgrade-9gmg2 10m -
Exclua o
UpgradeCR.$ kubectl delete upgrade.harvesterhci.io/hvst-upgrade-9gmg2 -n harvester-system -
Retome os ManagedCharts pausados.
Os ManagedCharts são pausados para evitar uma corrida de dados entre o fazer upgrade e outros processos. Você deve retomar manualmente todos os ManagedCharts pausados.
cat > resumeallcharts.sh << 'FOE' resume_all_charts() { local patchfile="/tmp/charttmp.yaml" cat >"$patchfile" << 'EOF' spec: paused: false EOF echo "the to-be-patched file" cat "$patchfile" local charts="harvester harvester-crd rancher-monitoring-crd rancher-logging-crd" for chart in $charts; do echo "unapuse managedchart $chart" kubectl patch managedcharts.management.cattle.io $chart -n fleet-local --patch-file "$patchfile" --type merge || echo "failed, check reason" done rm "$patchfile" } resume_all_charts FOE chmod +x ./resumeallcharts.sh ./resumeallcharts.sh
Baixe os logs do fazer upgrade
O SUSE Virtualization coleta automaticamente todos os logs relacionados ao fazer upgrade e exibe o procedimento do fazer upgrade. Por padrão, isso está habilitado. Você também pode optar por não participar desse comportamento.
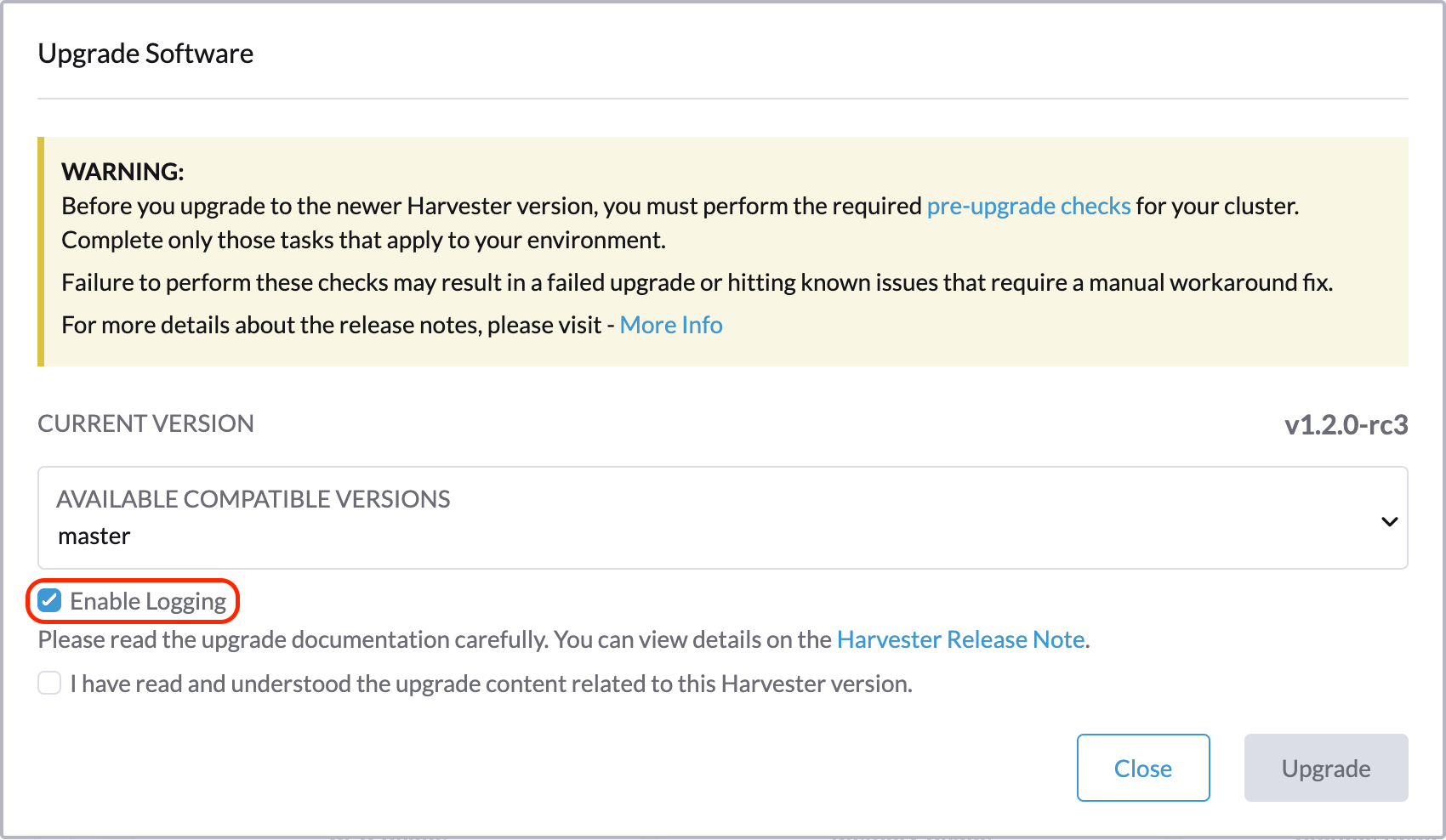
Você pode clicar no botão Baixar Registro para baixar o arquivo de registro durante o fazer upgrade.
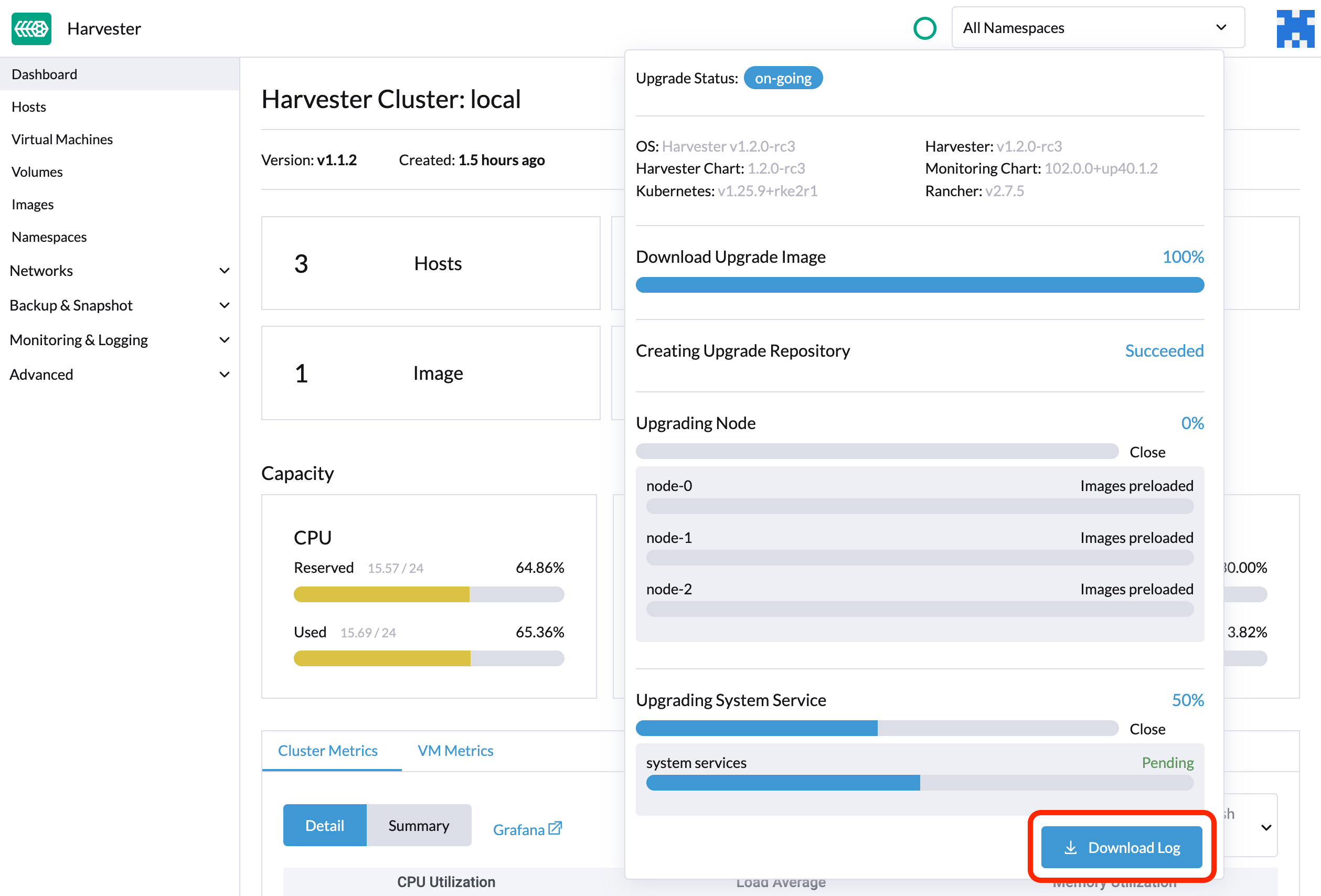
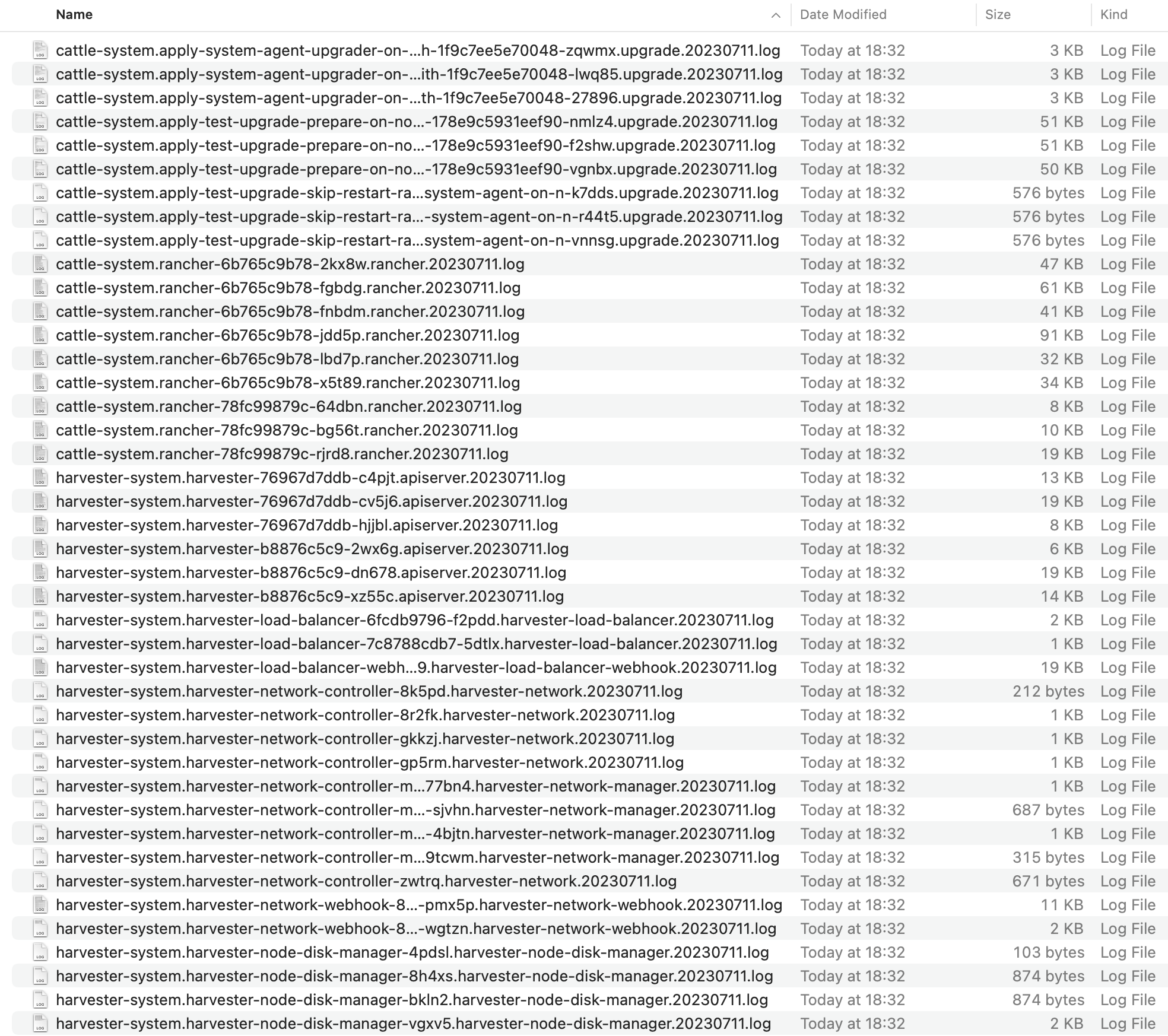
As entradas de registro serão coletadas como arquivos para cada Pod relacionado à atualização, mesmo para Pods intermediários. O pacote de suporte fornece um instantâneo do estado atual do cluster, incluindo logs e manifestos de recursos, enquanto o registro do fazer upgrade preserva quaisquer registros gerados durante um fazer upgrade. Ao combinar esses dois, você pode investigar ainda mais os problemas durante os fazer upgrades.
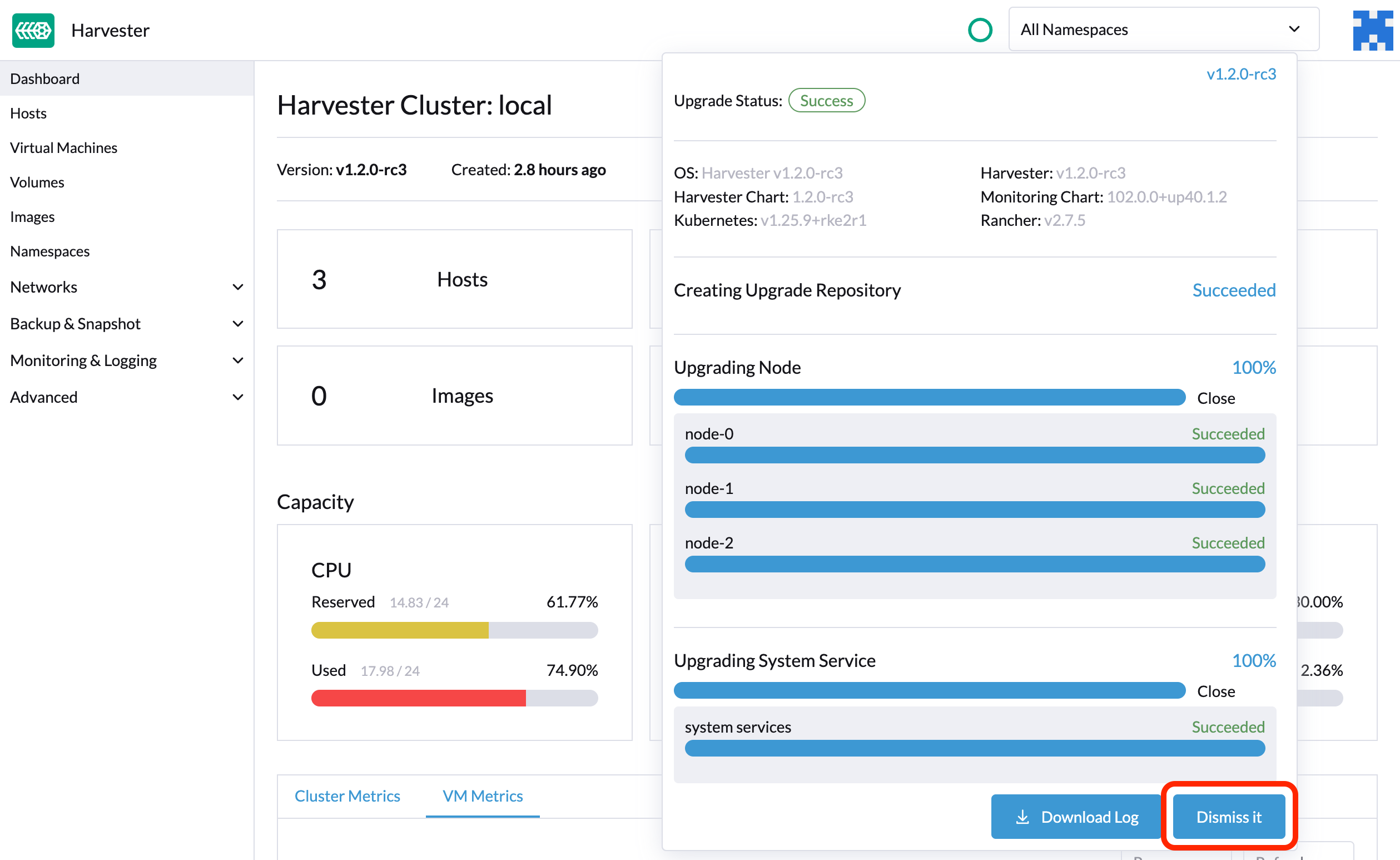
Após o término do fazer upgrade, SUSE Virtualization para de coletar os registros do fazer upgrade para evitar ocupar espaço em disco. Além disso, você pode clicar no botão Desconsiderar para purgar os registros do fazer upgrade.
|
A implantação do No entanto, esses componentes continuam a consumir recursos do cluster e podem bloquear certas operações, como atualizar as configurações da rede de armazenamento (veja problema #9599). Para liberar recursos e desbloquear operações, execute uma das seguintes ações:
|
Para mais detalhes, consulte o registro do fazer upgrade HEP.
|
O tamanho padrão do volume que armazena registros relacionados ao fazer upgrade é de 1 GB. Quando ocorrem erros, esses registros podem consumir completamente o espaço disponível do volume. Para contornar esse problema, você pode realizar os seguintes passos:
|
Limpe as imagens não utilizadas.
O valor padrão de imageGCHighThresholdPercent em Configuração do Kubelet é 85. Quando o uso do disco excede 85%, o kubelet tenta remover imagens não utilizadas.
Novas imagens são carregadas em cada nó SUSE Virtualization durante os fazer upgrades. Quando o uso do disco excede 85%, essas novas imagens podem ser marcadas para limpeza porque não são usadas por nenhum contêiner. Em ambientes air-gapped, a remoção de novas imagens do cluster pode interromper o processo de fazer upgrade.
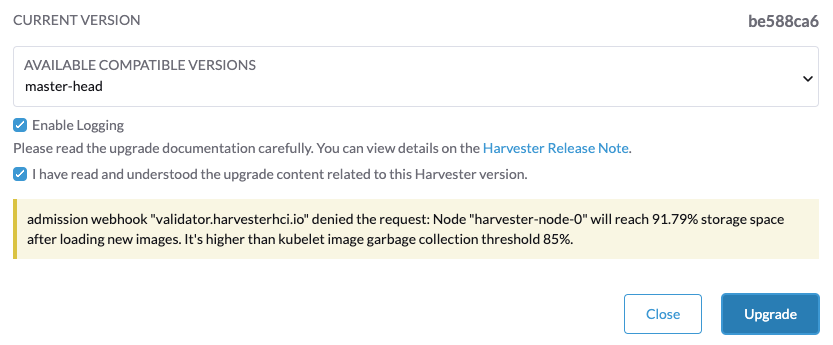
Se você encontrar a mensagem de erro Node xxx will reach xx.xx% storage space after loading new images. It’s higher than kubelet image garbage collection threshold 85%., execute crictl rmi --prune para limpar as imagens não utilizadas antes de iniciar um novo fazer upgrade.
Verifique o status de um fazer upgrade travado.
Se o fazer upgrade ficar travado e a interface SUSE Virtualization não exibir mensagens de erro, execute os seguintes passos:
-
Verifique os pods que foram criados durante o processo de fazer upgrade usando o comando
kubectl get pods -n harvester-system | grep upgrade.O script principal está no pod
hvst-upgrade-xxxxx-apply-manifests-xxxxx. Se os registros de log incluírem as seguintes mensagens, o CRmanagedChartpode estar causando problemas.Current version: x.x.x, Current state: WaitApplied, Current generation: x Sleep for 5 seconds to retry -
Recupere informações sobre o CR
bundleusando o comandokubectl get bundles -A.Exemplo:
NAMESPACE NAME BUNDLEDEPLOYMENTS-READY STATUS fleet-local fleet-agent-local 1/1 fleet-local local-managed-system-agent 1/1 fleet-local mcc-harvester 0/1 Modified(1) [Cluster fleet-local/local]; kubevirt.kubevirt.io harvester-system/kubevirt modified {"spec":{"configuration":{"vmStateStorageClass":"vmstate-persistence"}}} fleet-local mcc-harvester-crd 1/1 fleet-local mcc-local-managed-system-upgrade-controller 1/1 fleet-local mcc-rancher-logging-crd 1/1 fleet-local mcc-rancher-monitoring-crd 1/1