Monitoramento
O recurso de monitoramento agora está implementado com um complemento e está desativado por padrão em novas instalações.
Você pode habilitar e desabilitar o rancher-monitoring complemento após a instalação usando a interface SUSE Virtualization ou o arquivo de configuração.
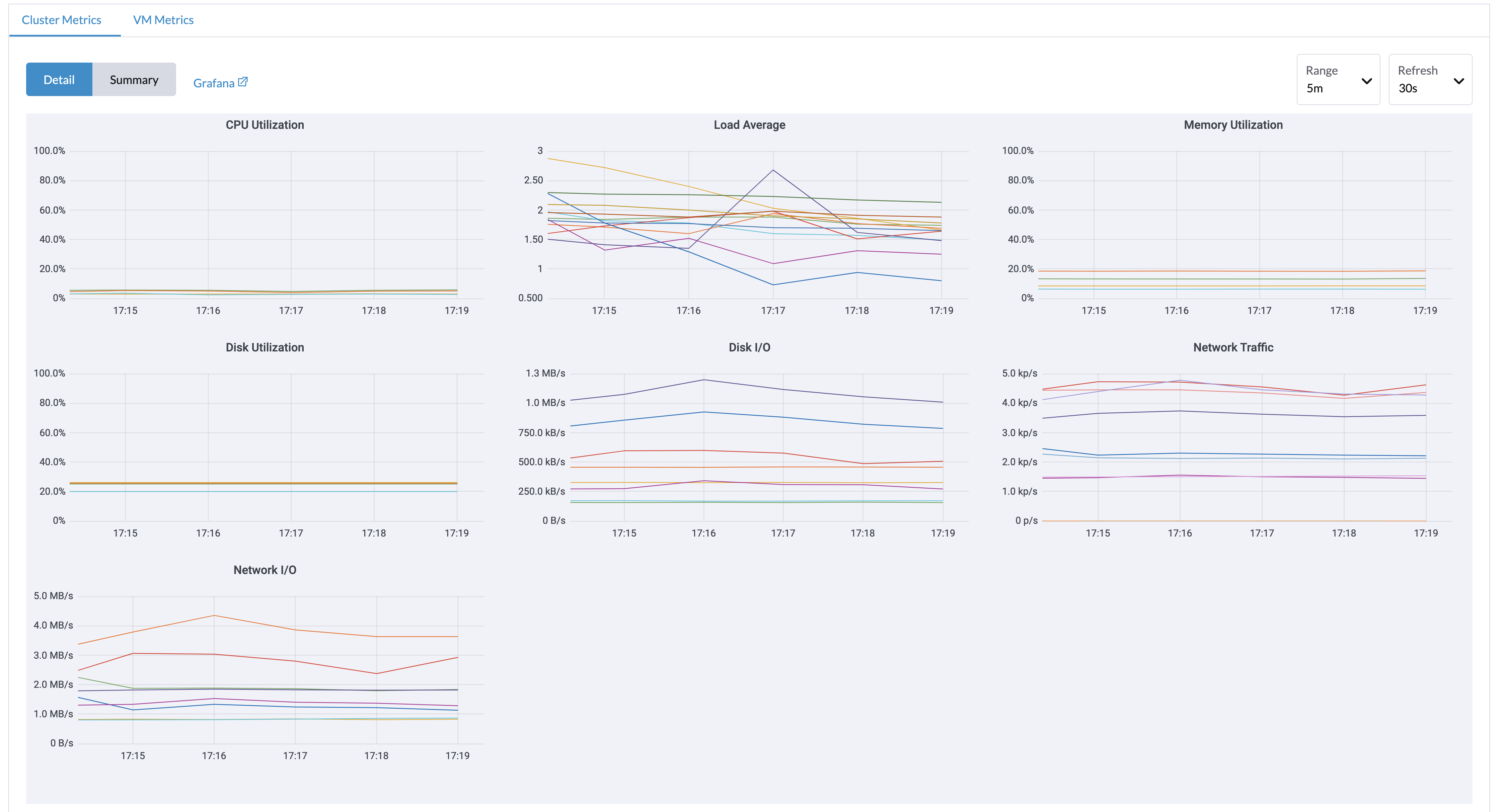
Métricas do Painel
SUSE Virtualization forneceu uma integração de monitoramento incorporada usando Prometheus. O monitoramento é habilitado automaticamente durante a instalação.
Na página Dashboard, os usuários podem visualizar as métricas do cluster e as 10 métricas de VM mais utilizadas, respectivamente.
Além disso, os usuários podem clicar no link do painel Grafana para visualizar mais painéis na interface do Grafana.
|
Apenas usuários administradores podem visualizar as métricas do painel do cluster. Além disso, o Grafana é fornecido por Referência: values.yaml |
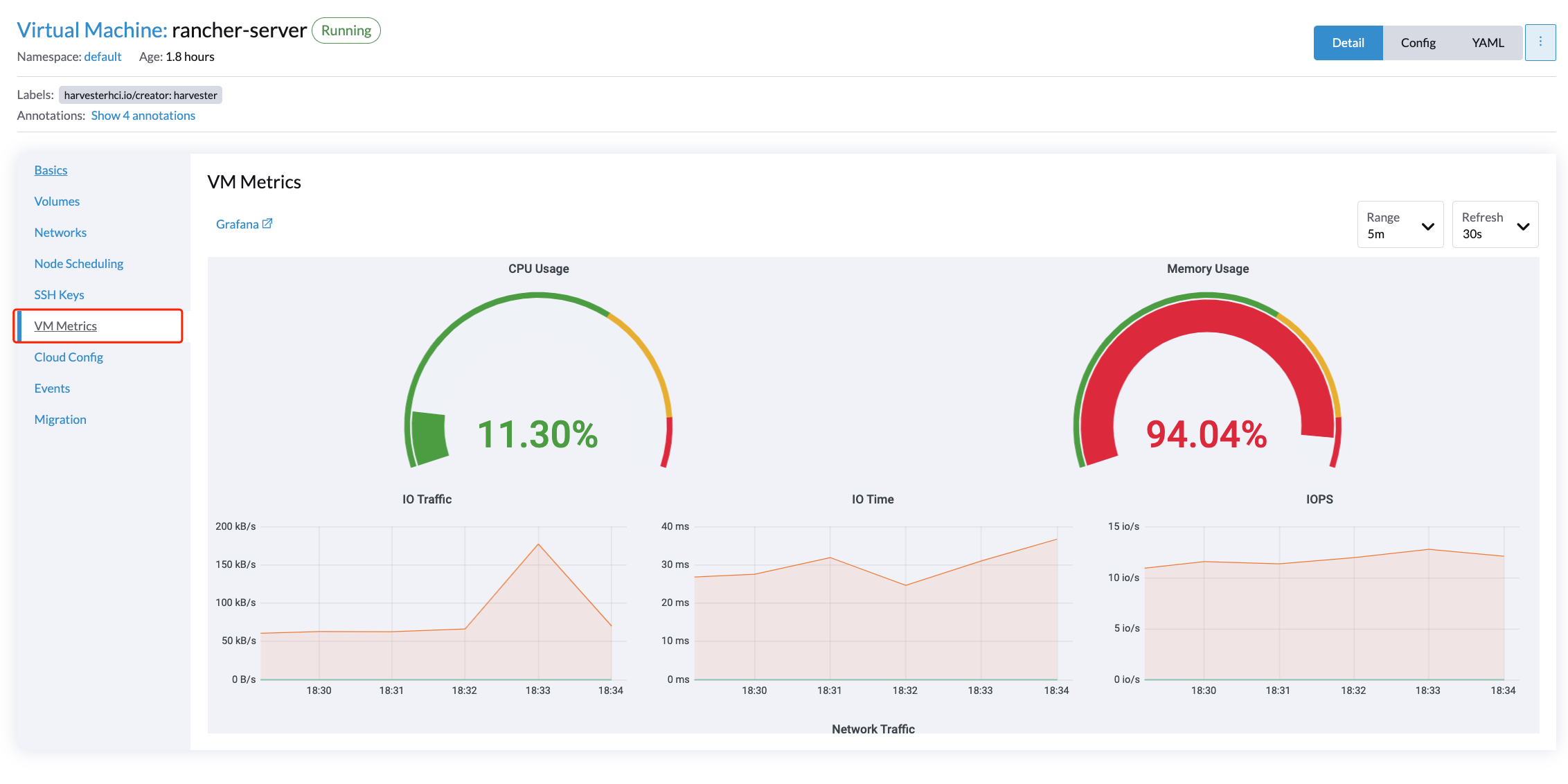
Métricas detalhadas da VM
Para VMs, você pode visualizar as métricas da VM clicando no VM details page > VM Metrics.
|
A |
Por exemplo, em um sistema operacional Linux, o comando free -h exibe as estatísticas de memória atuais da seguinte forma
$ free -h
total used free shared buff/cache available
Mem: 7.7Gi 166Mi 4.6Gi 1.0Mi 2.9Gi 7.2Gi
Swap: 0B 0B 0B
A Memory Usage correspondente é (1 - 4.6/7.7) * 100%, aproximadamente 40%.
Status e métricas de migração ao vivo
A migração ao vivo é um recurso crítico para garantir o tempo de atividade da carga de trabalho. Você pode monitorar o progresso da migração ao vivo da máquina virtual diretamente pela interface do Harvester via o complemento rancher-monitoring.
-
Habilite o complemento rancher-monitoring.
-
Vá para Máquinas Virtuais.
-
Localize a máquina virtual na lista e clique no nome para ver seus detalhes.
-
Vá para a aba Migração.
A aba Migração é dividida nas seguintes seções:
-
Informações gerais: Esta seção mostra a fase atual da migração, os nós de origem e destino, e os horários de início e término da migração.
-
Métricas em tempo real: Essas métricas são geradas pelo Prometheus e são mantidas por cinco dias.
Métrica Descrição Bytes de Dados Restantes da Migração
Quantidade de dados do sistema operacional convidado que não foram migrados
Bytes de Dados Processados da Migração
Quantidade de dados do sistema operacional convidado que já foram migrados
Taxa de Transferência de Memória da Migração
Taxa na qual a memória é transferida
Taxa de Memória Suja da Migração
Taxa na qual os dados são alterados na memória do convidado, mas não sincronizados com os dados no disco
Se o valor de Bytes de Dados Restantes da Migração diminui constantemente enquanto o valor de Bytes de Dados Processados da Migração aumenta, os dados estão sendo migrados com sucesso para o destino.
Se o valor de Bytes de Dados Restantes da Migração estiver flutuando enquanto a Taxa de Memória Suja da Migração permanecer muito alta, a máquina virtual está sob pressão significativa. Em alguns casos, isso pode impedir a conclusão da migração.
-
Eventos de migração: Esses registros de eventos específicos da máquina virtual são gerados pelo servidor da API do Kubernetes (kube-apiserver) e são mantidos por uma hora.
Como configurar as definições de monitoramento
O monitoramento possui vários componentes que ajudam a coletar e agregar dados métricos de todos os Nós/Pods/VMs. Os recursos necessários para monitoramento dependem das suas cargas de trabalho e recursos de hardware. SUSE Virtualization define padrões com base em casos de uso gerais, e você pode alterá-los conforme necessário.
Atualmente, Resources Settings pode ser configurado para os seguintes componentes:
-
Prometheus
-
Prometheus Node Exporter
Da interface
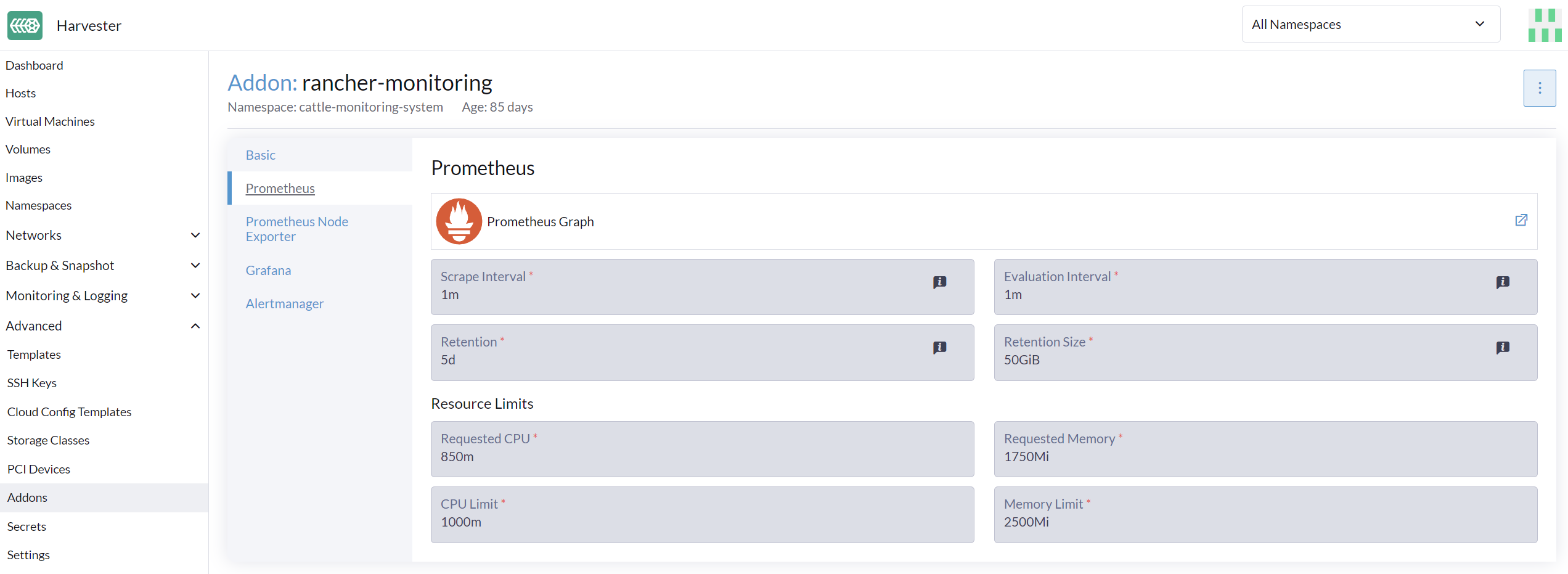
Na página Avançado, você pode visualizar e alterar as configurações de recursos da seguinte forma:
-
Vá para a página Avançado > Complementos e selecione a página rancher-monitoring.
-
Na aba Prometheus, altere os pedidos e limites de recursos.
-
Selecione Salvar ao terminar de configurar as definições para o complemento rancher-monitoring. As implantações de Monitoramento reiniciam em poucos segundos. Por favor, esteja ciente de que o reinício pode levar tempo para recarregar os dados anteriores.
|
A configuração da UI só é visível quando o complemento rancher-monitoring está habilitado. |
A opção mais frequentemente utilizada é a configuração de memória:
-
O
Requested Memoryé a memória mínima necessária pelo recursoMonitoring. O valor recomendado é cerca de 5% a 10% da memória do sistema de um único nó de gerenciamento. Um valor inferior a 500Mi será negado. -
O
Memory Limité a memória máxima que pode ser alocada a um recursoMonitoring. O valor recomendado é cerca de 30% da memória do sistema para um único nó de gerenciamento. Quando oMonitoringatinge esse limite, ele será reiniciado automaticamente.
Dependendo dos recursos de hardware disponíveis e das cargas do sistema, você pode alterar as configurações acima de acordo.
|
Se você tiver vários nós de gerenciamento com diferentes recursos de hardware, defina o valor do Prometheus com base no menor deles. |
|
Quando um número crescente de VMs é implantado em um nó, o pod |
Da CLI
Você pode usar o seguinte comando kubectl para alterar as configurações de recursos para o complemento rancher-monitoring: kubectl edit addons.harvesterhci.io -n cattle-monitoring-system rancher-monitoring.
O caminho do recurso e os valores padrão são os seguintes:
apiVersion: harvesterhci.io/v1beta1
kind: Addon
metadata:
name: rancher-monitoring
namespace: cattle-monitoring-system
spec:
valuesContent: |
prometheus:
prometheusSpec:
resources:
limits:
cpu: 1000m
memory: 2500Mi
requests:
cpu: 850m
memory: 1750Mi
|
Você ainda pode fazer ajustes de configuração quando o complemento está desativado. No entanto, essas alterações só têm efeito quando você reativa o complemento. |
Alertmanager
SUSE Virtualization usa Alertmanager para coletar e gerenciar todos os alertas que ocorreram/estão ocorrendo no cluster.
Configuração do Alertmanager
Ativar/Desativar Alertmanager
Alertmanager é habilitado por padrão. Você pode desativá-lo a partir do seguinte caminho de configuração.
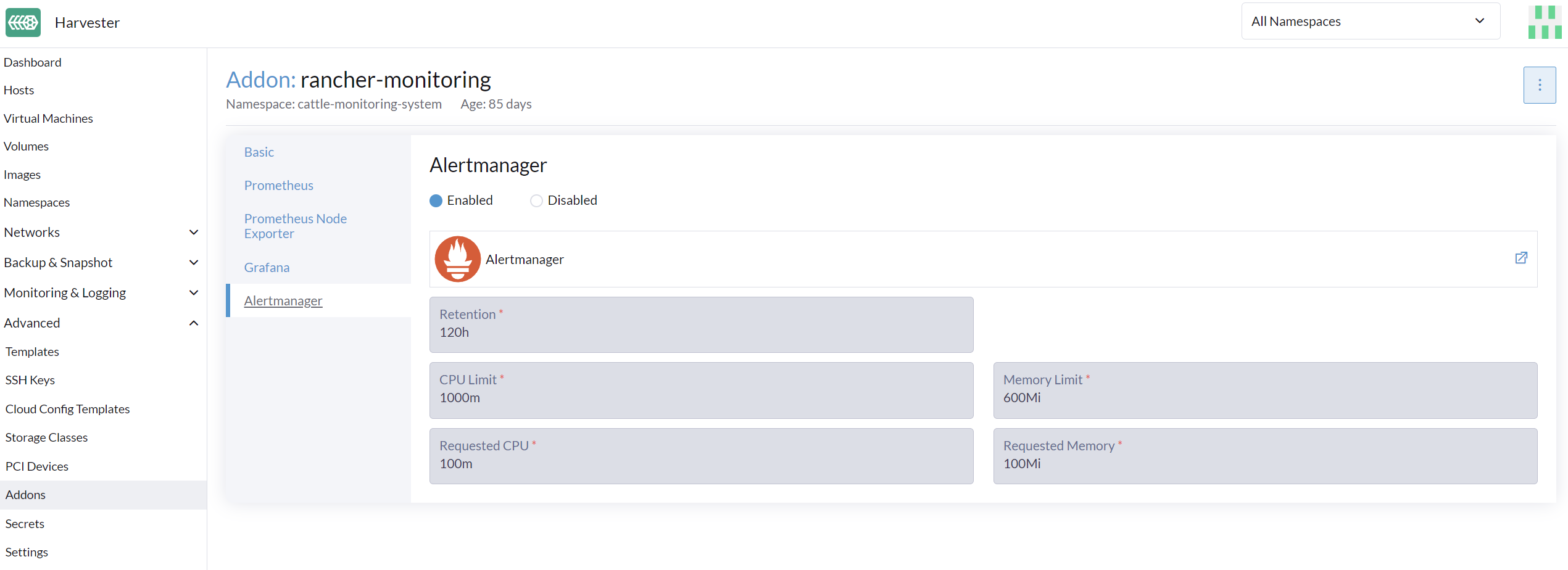
Alterar Configuração de Recursos
Você também pode alterar as configurações de recursos de Alertmanager conforme mostrado na imagem acima.
Configurar AlertmanagerConfig a partir do WebUI
Para enviar os alertas para servidores de terceiros, configure AlertmanagerConfig.
-
Na interface, vá para Monitoramento & Registro → Monitoramento → Configurações do Alertmanager.
-
Na configuração do Alertmanager: Crie a tela, especifique um namespace e um nome, e então clique em Criar.
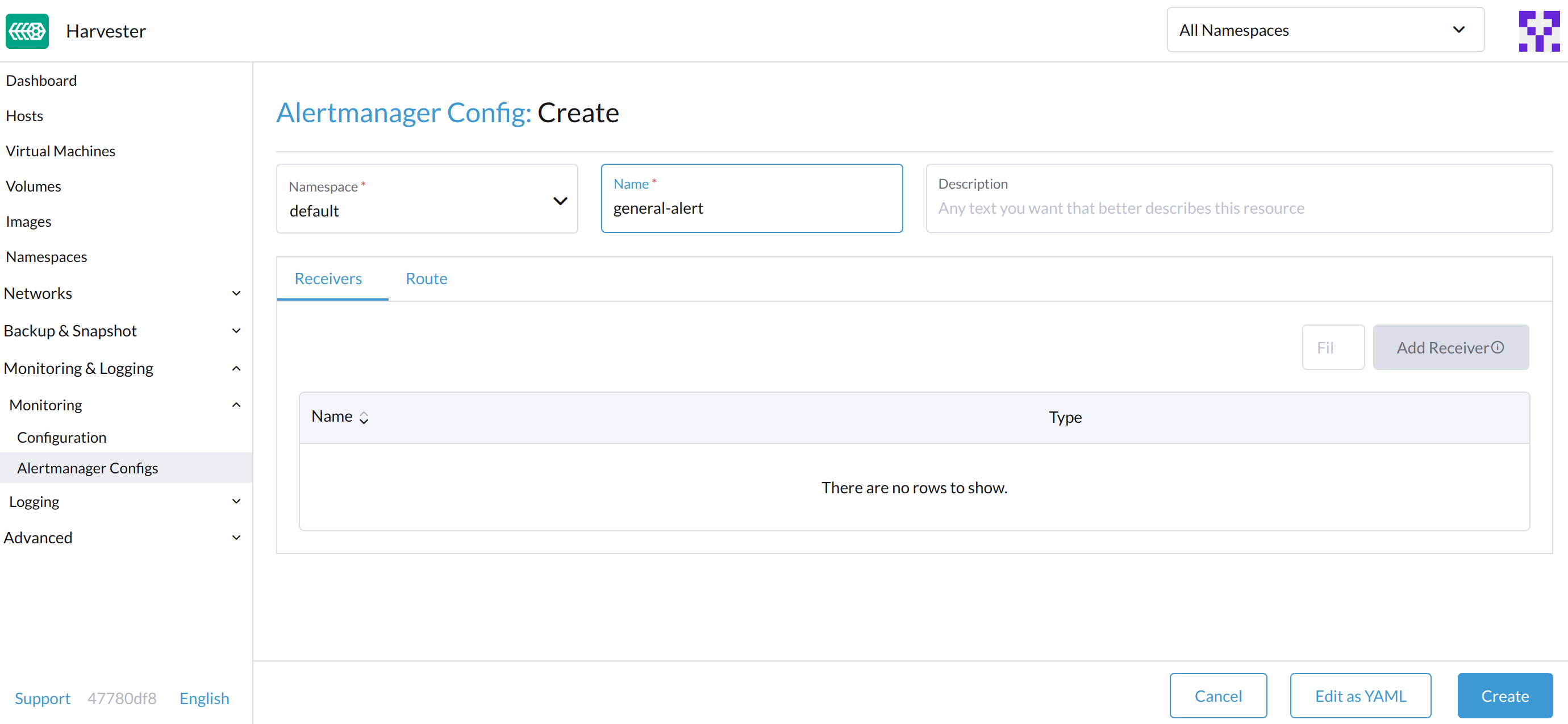
-
Clique no nome da configuração que você acabou de criar.
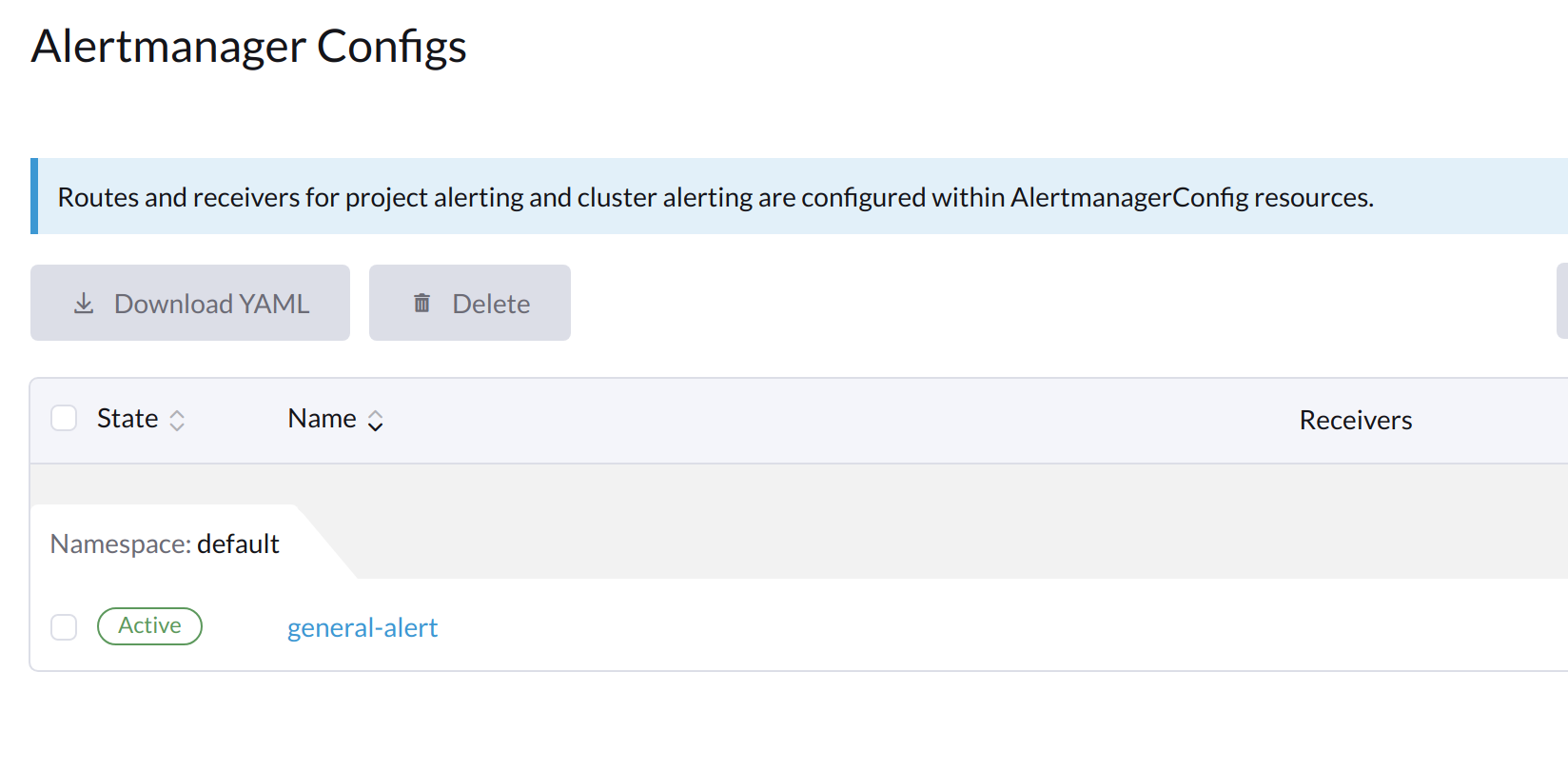
-
Clique em Adicionar Receptor.
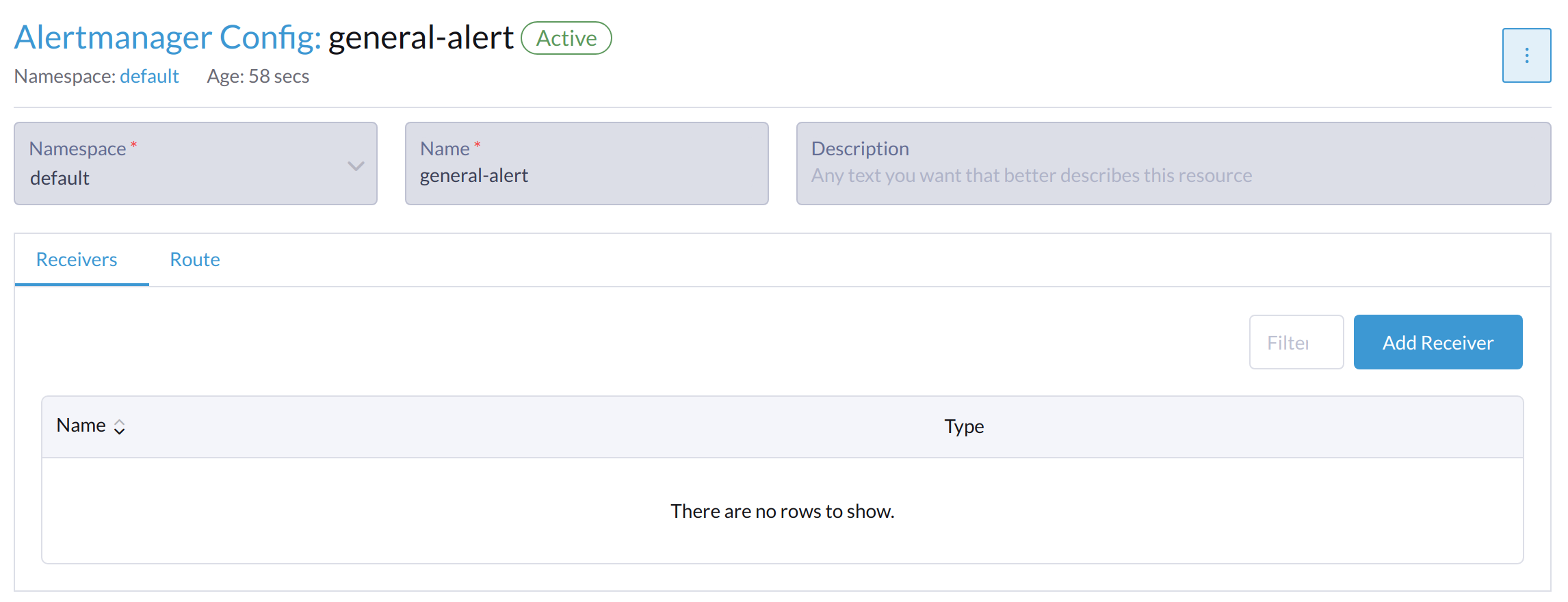
-
Especifique um nome para o receptor e, em seguida, selecione um tipo de receptor.
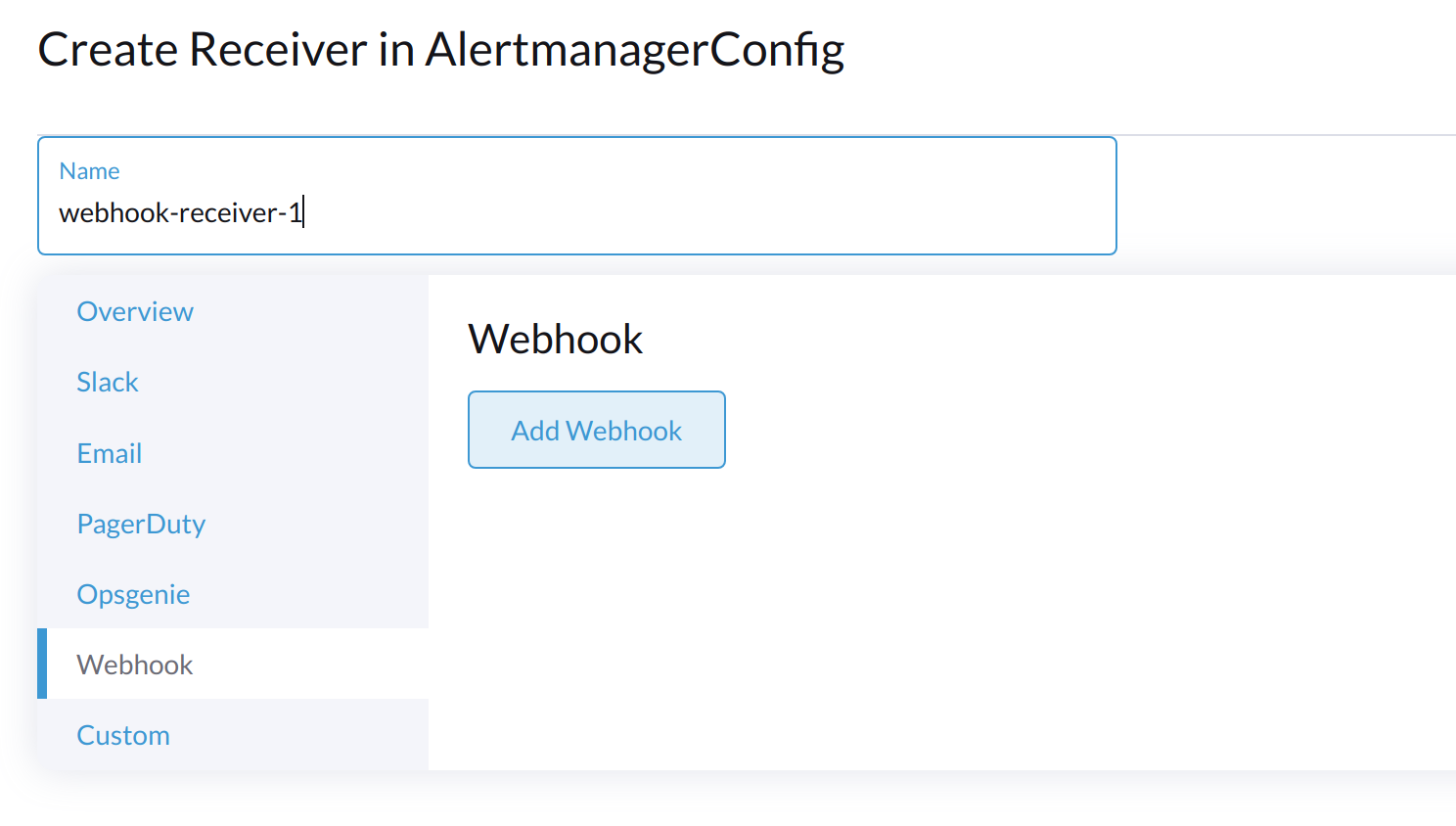
-
Configure as configurações necessárias e, em seguida, clique em Criar.
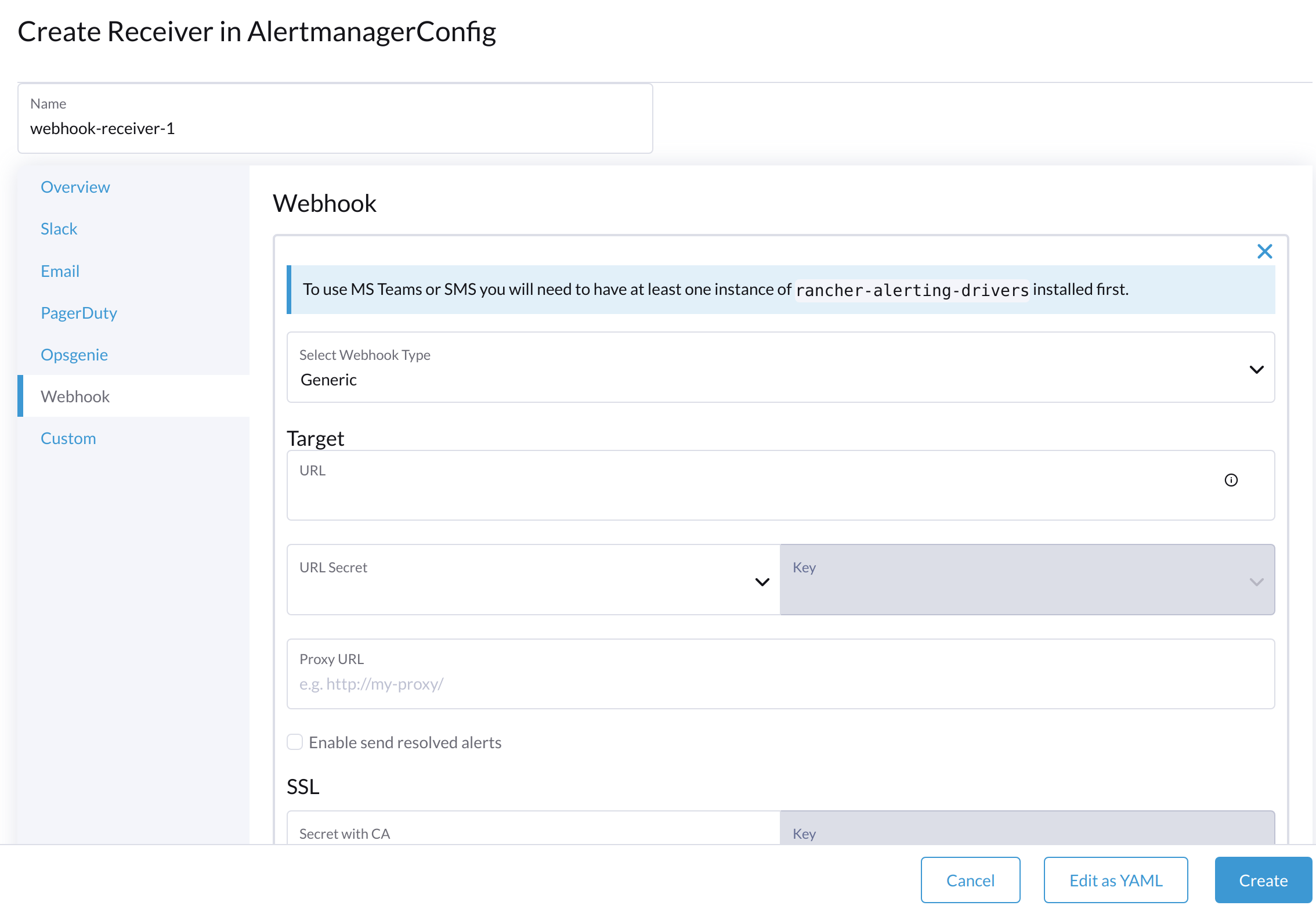
Para configurar webhooks do Microsoft Teams ou SMS, primeiro instale o aplicativo rancher-alerting-drivers usando os seguintes comandos:
helm repo add rancher-charts https://charts.rancher.io/
helm repo update
helm install rancher-charts/rancher-alerting-drivers \
--set sachet.enabled=false \ # Set to true if you want to use SMS Webhook
--set prom2teams.enabled=true \ # Set to true if you want to use MS Teams Webhook
--namespace cattle-monitoring-system \
--generate-namePara instruções detalhadas de configuração, consulte Configuração do Receptor na documentação Rancher.
Se o seu ambiente não tiver acesso direto à internet (air-gapped), você deve baixar manualmente o gráfico Helm e as imagens de contêiner relacionadas, e então enviá-las para o cluster SUSE Virtualization.
-
Baixe o gráfico Helm do rancher-alerting-drivers e empacote-o.
helm pull rancher-charts/rancher-alerting-drivers --version <VERSION>
-
Baixe as imagens necessárias.
docker save -o sachet.tar rancher/mirrored-messagebird-sachet:<VERSION> docker save -o prom2teams.tar rancher/mirrored-idealista-prom2teams:<VERSION>
-
Envie o gráfico e as imagens para o cluster SUSE Virtualization.
-
Carregue as imagens em todos os nós SUSE Virtualization.
docker load -i sachet.tar docker load -i prom2teams.tar
-
Instale o rancher-alerting-drivers no cluster SUSE Virtualization.
|
SUSE Virtualization não gerencia os upgrades do aplicativo |
Configure o AlertmanagerConfig a partir da CLI
Você também pode adicionar AlertmanagerConfig a partir da CLI.
Exemplo: um receptor Webhook no namespace default.
cat << EOF > a-single-receiver.yaml
apiVersion: monitoring.coreos.com/v1alpha1
kind: AlertmanagerConfig
metadata:
name: amc-example
# namespace: your value
labels:
alertmanagerConfig: example
spec:
route:
continue: true
groupBy:
- cluster
- alertname
receiver: "amc-webhook-receiver"
receivers:
- name: "amc-webhook-receiver"
webhookConfigs:
- sendResolved: true
url: "http://192.168.122.159:8090/"
EOF
# kubectl apply -f a-single-receiver.yaml
alertmanagerconfig.monitoring.coreos.com/amc-example created
# kubectl get alertmanagerconfig -A
NAMESPACE NAME AGE
default amc-example 27s
Exemplo de um Alerta Recebido por Webhook
Os alertas enviados para o servidor webhook estarão no seguinte formato:
{
'receiver': 'longhorn-system-amc-example-amc-webhook-receiver',
'status': 'firing',
'alerts': [],
'groupLabels': {},
'commonLabels': {'alertname': 'LonghornVolumeStatusWarning', 'container': 'longhorn-manager', 'endpoint': 'manager', 'instance': '10.52.0.83:9500', 'issue': 'Longhorn volume is Degraded.',
'job': 'longhorn-backend', 'namespace': 'longhorn-system', 'node': 'harv2', 'pod': 'longhorn-manager-r5bgm', 'prometheus': 'cattle-monitoring-system/rancher-monitoring-prometheus',
'service': 'longhorn-backend', 'severity': 'warning'},
'commonAnnotations': {'description': 'Longhorn volume is Degraded for more than 5 minutes.', 'runbook_url': 'https://longhorn.io/docs/1.3.0/monitoring/metrics/',
'summary': 'Longhorn volume is Degraded'},
'externalURL': 'https://192.168.122.200/api/v1/namespaces/cattle-monitoring-system/services/http:rancher-monitoring-alertmanager:9093/proxy',
'version': '4',
'groupKey': '{}/{namespace="longhorn-system"}:{}',
'truncatedAlerts': 0
}
|
Diferentes receptores podem apresentar os alertas em formatos diferentes. Para mais detalhes, consulte os documentos relacionados. |
Limitação conhecida
O AlertmanagerConfig é imposto pelo namespace. O AlertmanagerConfig de nível global sem um namespace não é suportado.
Já criamos um problema no GitHub para acompanhar as mudanças upstream. Assim que o recurso estiver disponível, SUSE Virtualization o adotará.
Visualizar e Gerenciar Alertas
Do Painel do Alertmanager
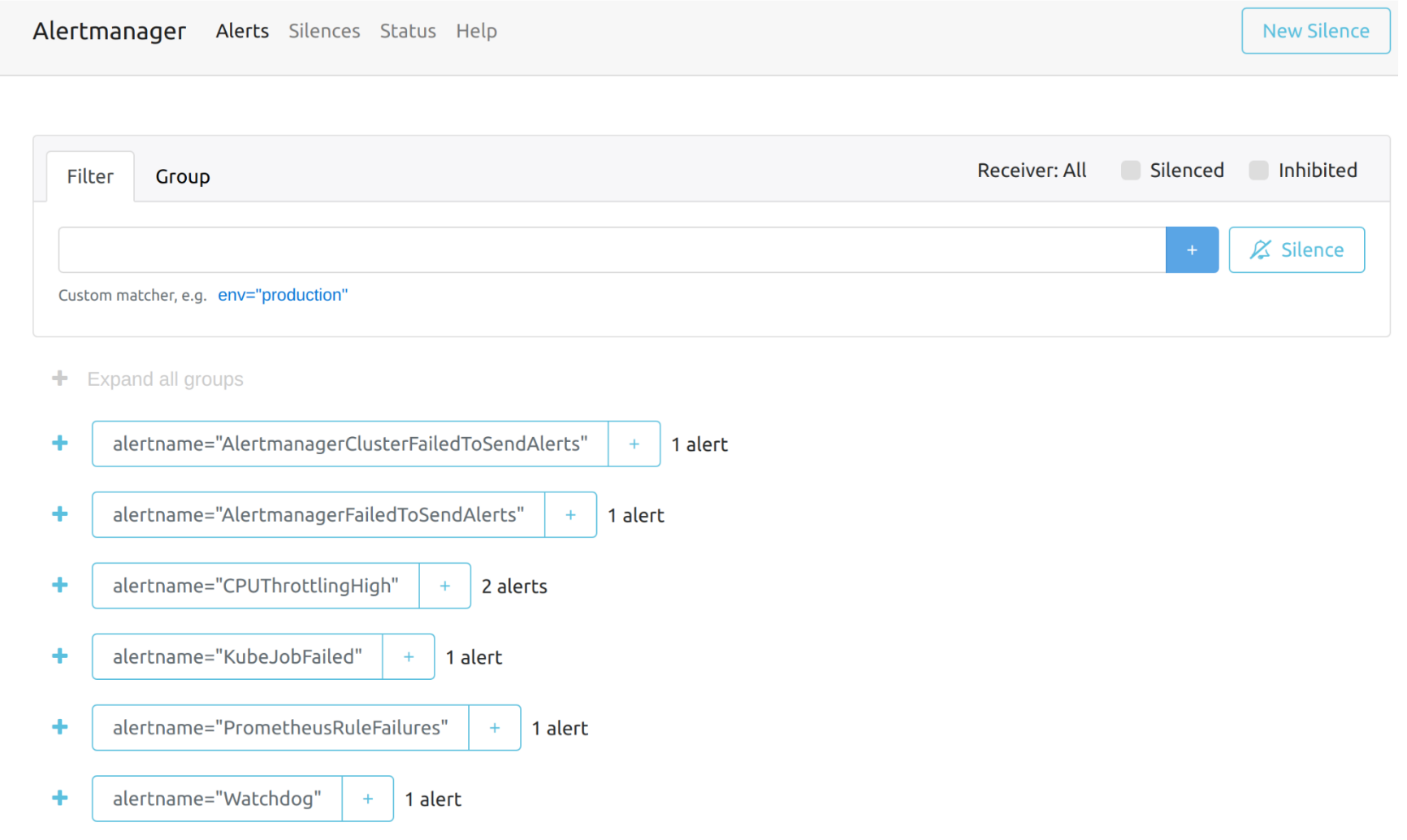
Você pode visitar o painel original do Alertmanager pelo link abaixo. Observe que você precisa substituir the-cluster-vip pelo cluster-vip real:
A visão geral do painel Alertmanager é a seguinte.
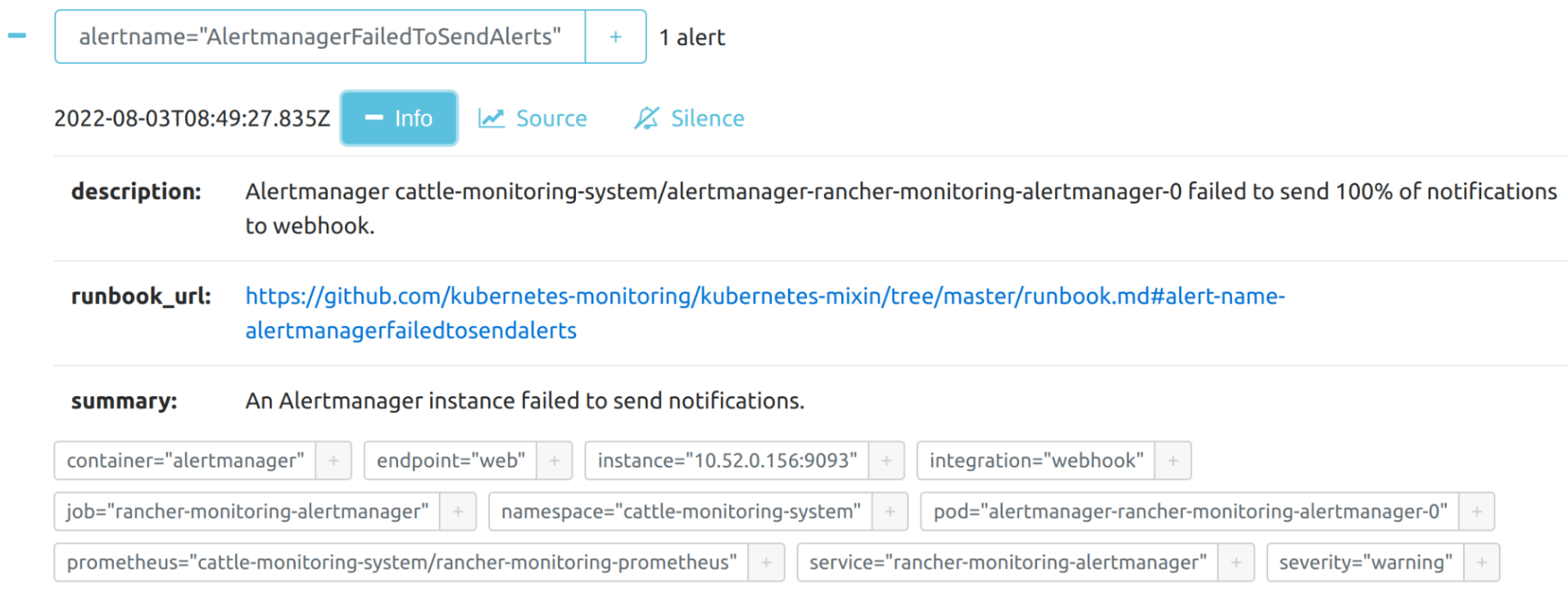
Você pode visualizar os detalhes de um alerta:
Do Painel do Prometheus
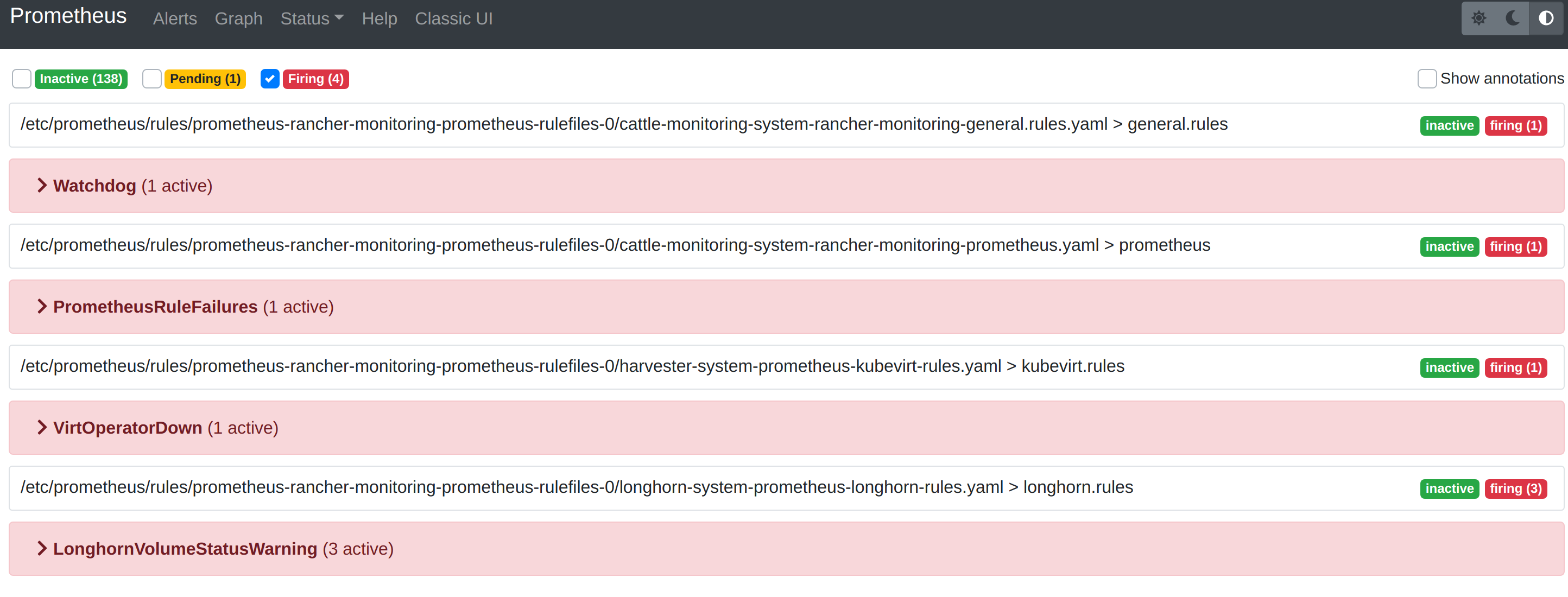
Você pode visitar o painel original do Prometheus pelo link abaixo. Observe que você precisa substituir the-cluster-vip pelo cluster-vip real:
O menu Alerts na barra de navegação superior mostra todas as regras definidas no Prometheus. Você pode usar os filtros Inactive, Pending e Firing para encontrar rapidamente as informações que você precisa.
Solução de problemas
Para suporte e resolução de problemas de monitoramento, consulte a página de resolução de problemas.