Problemas de instalação
As seções a seguir contêm dicas para solucionar problemas ou obter assistência com instalações com falha.
Fazendo login no Instalador (um sistema operacional live)
Os usuários podem pressionar a combinação de teclas CTRL + ALT + F2 para alternar para outro TTY e fazer login com as seguintes credenciais:
-
Usuário:
rancher -
Senha:
rancher
Atendendo aos requisitos de hardware
-
Verifique se seu hardware atende aos requisitos mínimos para completar a instalação.
Preso em Loading images. This may take a few minutes…
Como o sistema não possui uma rota padrão, seu instalador pode ficar "preso" neste estado. Você pode verificar o status da sua rota executando o seguinte comando:
$ ip route
default via 10.10.0.10 dev mgmt-br proto dhcp <-- Does a default route exist?
10.10.0.0/24 dev mgmt-br proto kernel scope link src 10.10.0.15Verifique se seu servidor DHCP oferece uma opção de rota padrão. Anexar conteúdo de /run/cos/target/rke2.log também é útil.
Para mais informações, consulte Configuração do Servidor DHCP.
Modificando o token do cluster em nós agentes
Quando um nó agente falha ao ingressar no cluster, isso pode estar relacionado ao token do cluster não ser idêntico ao token do nó servidor.
Para confirmar o problema, conecte-se ao seu nó agente (ou seja, com SSH) e verifique o log do serviço rancherd com o seguinte comando:
sudo journalctl -b -u rancherdSe a configuração do token do cluster no nó agente não corresponder ao token do nó servidor, você encontrará várias entradas da seguinte mensagem:
msg="Bootstrapping Rancher (v2.7.5/v1.25.9+rke2r1)"
msg="failed to bootstrap system, will retry: generating plan: response 502: 502 Bad Gateway getting cacerts: <html>\r\n<head><title>502 Bad Gateway</title></head>\r\n<body>\r\n<center><h1>502 Bad Gateway</h1></center>\r\n<hr><center>nginx</center>\r\n</body>\r\n</html>\r\n"Observe que a versão Rancher e o endereço IP dependem do seu ambiente e podem diferir da mensagem acima.
Para corrigir o problema, você precisa atualizar o valor do token no arquivo de configuração rancherd /etc/rancher/rancherd/config.yaml.
Por exemplo, se a configuração do token do cluster no nó servidor for ThisIsTheCorrectOne, você atualizará o valor do token da seguinte forma:
token: 'ThisIsTheCorrectOne'Para garantir que a alteração seja persistente entre reinicializações, atualize o valor token do arquivo de configuração do sistema operacional /oem/90_custom.yaml:
name: Harvester Configuration
stages:
...
initramfs:
- commands:
- ...
files:
- path: /etc/rancher/rancherd/config.yaml
permissions: 384
owner: 0
group: 0
content: |
server: https://$cluster-vip:443
role: agent
token: "ThisIsTheCorrectOne"
kubernetesVersion: v1.25.9+rke2r1
rancherVersion: v2.7.5
rancherInstallerImage: rancher/system-agent-installer-rancher:v2.7.5
labels:
- harvesterhci.io/managed=true
extraConfig:
disable:
- rke2-snapshot-controller
- rke2-snapshot-controller-crd
- rke2-snapshot-validation-webhook
encoding: ""
ownerstring: ""|
Para ver qual é o valor atual do token do cluster, faça login no seu nó do servidor (ou seja, com SSH) e procure no arquivo |
Verificando o status dos componentes
Antes de verificar o status dos componentes SUSE Virtualization, obtenha uma cópia do arquivo kubeconfig do cluster usando um dos seguintes métodos:
-
Na interface do SUSE Virtualization, vá para a tela Suporte e clique em Baixar KubeConfig.
-
Execute os seguintes comandos em qualquer um dos nós de gerenciamento:
$ sudo su $ cat /etc/rancher/rke2/rke2.yaml
Depois de obter uma cópia do arquivo kubeconfig, execute o seguinte script contra o cluster para verificar a prontidão de cada componente.
-
Componentes do SUSE Virtualization
#!/bin/bash cluster_ready() { namespaces=("cattle-system" "kube-system" "harvester-system" "longhorn-system") for ns in "${namespaces[@]}"; do pod_statuses=($(kubectl -n "${ns}" get pods \ --field-selector=status.phase!=Succeeded \ -ojsonpath='{range .items[*]}{.metadata.namespace}/{.metadata.name},{.status.conditions[?(@.type=="Ready")].status}{"\n"}{end}')) for status in "${pod_statuses[@]}"; do name=$(echo "${status}" | cut -d ',' -f1) ready=$(echo "${status}" | cut -d ',' -f2) if [ "${ready}" != "True" ]; then echo "pod ${name} is not ready" false return fi done done } if cluster_ready; then echo "cluster is ready" else echo "cluster is not ready" fi -
API
$ curl -fk https://<VIP>/versionVocê deve substituir
<VIP>pelo VIP atual, que é o valor dekube-vip.io/requestedIP.
Coletando informações de solução de problemas
Por favor, inclua as seguintes informações em um relatório de erro ao relatar uma instalação com falha:
-
Uma captura de tela da instalação com falha.
-
Informações do sistema e logs.
Por favor, siga o guia em [Logging into the Installer (a live OS)] para fazer login. E execute o comando para gerar um tarball que contém informações de solução de problemas:
supportconfig -k -cAs mensagens de saída do comando contêm o caminho do tarball gerado. Por exemplo, o caminho é
/var/loq/scc_aaa_220520_1021 804d65d-c9ba-4c54-b12d-859631f892c5.txzno seguinte exemplo: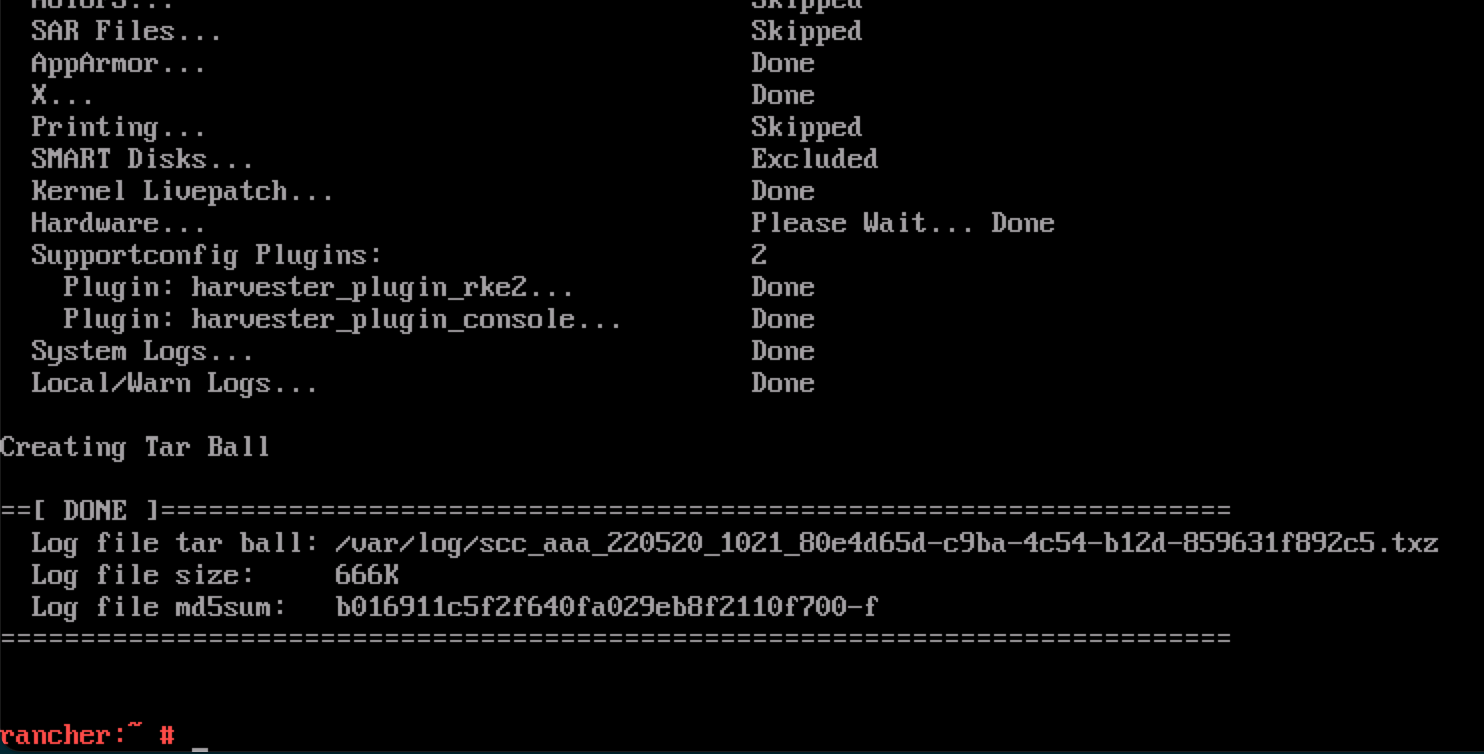
Uma instalação com falha na Inicialização PXE gera automaticamente um tarball se o campo
install.debugestiver definido comotrueno arquivo de configuração.
Verificando o status do gráfico
SUSE Virtualization usa os seguintes CRDs de gráfico:
-
HelmChart: Mantém gráficos RKE2.-
rke2-runtimeclasses -
rke2-multus -
rke2-metrics-server -
rke2-ingress-nginx -
rke2-coredns -
rke2-cannal
-
-
ManagedChart: Gerencia gráficos Rancher e SUSE Virtualization.-
rancher-monitoring-crd -
rancher-logging-crd -
kubeovn-operator-crd -
harvester-crd -
harvester
-
Você pode usar o comando helm list -A para recuperar uma lista de gráficos instalados.
Exemplo de saída:
NAME NAMESPACE REVISION UPDATED STATUS CHART APP VERSION
fleet cattle-fleet-system 4 2025-09-24 09:07:10.801764068 +0000 UTC deployed fleet-107.0.0+up0.13.0 0.13.0
fleet-agent-local cattle-fleet-local-system 1 2025-09-24 08:59:28.686781982 +0000 UTC deployed fleet-agent-local-v0.0.0+s-d4f65a6f642cca930c78e6e2f0d3f9bbb7d3ba47cf1cce34ac3d6b8770ce5
fleet-crd cattle-fleet-system 1 2025-09-24 08:58:28.396419747 +0000 UTC deployed fleet-crd-107.0.0+up0.13.0 0.13.0
harvester harvester-system 1 2025-09-24 08:59:37.718646669 +0000 UTC deployed harvester-0.0.0-master-ac070598 master-ac070598
harvester-crd harvester-system 1 2025-09-24 08:59:35.341316526 +0000 UTC deployed harvester-crd-0.0.0-master-ac070598 master-ac070598
kubeovn-operator-crd kube-system 1 2025-09-24 08:59:34.783356576 +0000 UTC deployed kubeovn-operator-crd-1.13.13 v1.13.13
mcc-local-managed-system-upgrade-controller cattle-system 1 2025-09-24 08:59:10.656784284 +0000 UTC deployed system-upgrade-controller-107.0.0 v0.16.0
rancher cattle-system 1 2025-09-24 08:57:20.690330683 +0000 UTC deployed rancher-2.12.0 8815e66-dirty
rancher-logging-crd cattle-logging-system 1 2025-09-24 08:59:36.262080367 +0000 UTC deployed rancher-logging-crd-107.0.1+up4.10.0-rancher.10
rancher-monitoring-crd cattle-monitoring-system 1 2025-09-24 08:59:35.287099045 +0000 UTC deployed rancher-monitoring-crd-107.1.0+up69.8.2-rancher.15
rancher-provisioning-capi cattle-provisioning-capi-system 1 2025-09-24 08:59:00.561162307 +0000 UTC deployed rancher-provisioning-capi-107.0.0+up0.8.0 1.10.2
rancher-webhook cattle-system 2 2025-09-24 09:02:38.774660489 +0000 UTC deployed rancher-webhook-107.0.0+up0.8.0 0.8.0
rke2-canal kube-system 1 2025-09-24 08:57:25.248839867 +0000 UTC deployed rke2-canal-v3.30.2-build2025071100 v3.30.2
rke2-coredns kube-system 1 2025-09-24 08:57:25.341016864 +0000 UTC deployed rke2-coredns-1.42.302 1.12.2
rke2-ingress-nginx kube-system 3 2025-09-24 09:01:31.331647555 +0000 UTC deployed rke2-ingress-nginx-4.12.401 1.12.4
rke2-metrics-server kube-system 1 2025-09-24 08:57:42.162046899 +0000 UTC deployed rke2-metrics-server-3.12.203 0.7.2
rke2-multus kube-system 1 2025-09-24 08:57:25.341560394 +0000 UTC deployed rke2-multus-v4.2.106 4.2.1
rke2-runtimeclasses kube-system 1 2025-09-24 08:57:40.137168056 +0000 UTC deployed rke2-runtimeclasses-0.1.000 0.1.0CRD HelmChart
Itens HelmChart são instalados por jobs. Você pode determinar o nome e o status de cada job executando o seguinte comando no nó SUSE Virtualization:
$ kubectl get helmcharts -A -o jsonpath='{range .items[*]}{"Namespace: "}{.metadata.namespace}{"\nName: "}{.metadata.name}{"\nStatus:\n"}{range .status.conditions[*]}{" - Type: "}{.type}{"\n Status: "}{.status}{"\n Reason: "}{.reason}{"\n Message: "}{.message}{"\n"}{end}{"JobName: "}{.status.jobName}{"\n\n"}{end}'Exemplo de saída:
Namespace: kube-system
Name: rke2-canal
Status:
- Type: JobCreated
Status: True
Reason: Job created
Message: Applying HelmChart using Job kube-system/helm-install-rke2-canal
- Type: Failed
Status: False
Reason:
Message:
JobName: helm-install-rke2-canal
Namespace: kube-system
Name: rke2-coredns
Status:
- Type: JobCreated
Status: True
Reason: Job created
Message: Applying HelmChart using Job kube-system/helm-install-rke2-coredns
- Type: Failed
Status: False
Reason:
Message:
JobName: helm-install-rke2-coredns
Namespace: kube-system
Name: rke2-ingress-nginx
Status:
- Type: JobCreated
Status: True
Reason: Job created
Message: Applying HelmChart using Job kube-system/helm-install-rke2-ingress-nginx
- Type: Failed
Status: False
Reason:
Message:
JobName: helm-install-rke2-ingress-nginx
Namespace: kube-system
Name: rke2-metrics-server
Status:
- Type: JobCreated
Status: True
Reason: Job created
Message: Applying HelmChart using Job kube-system/helm-install-rke2-metrics-server
- Type: Failed
Status: False
Reason:
Message:
JobName: helm-install-rke2-metrics-server
Namespace: kube-system
Name: rke2-multus
Status:
- Type: JobCreated
Status: True
Reason: Job created
Message: Applying HelmChart using Job kube-system/helm-install-rke2-multus
- Type: Failed
Status: False
Reason:
Message:
JobName: helm-install-rke2-multus
Namespace: kube-system
Name: rke2-runtimeclasses
Status:
- Type: JobCreated
Status: True
Reason: Job created
Message: Applying HelmChart using Job kube-system/helm-install-rke2-runtimeclasses
- Type: Failed
Status: False
Reason:
Message:
JobName: helm-install-rke2-runtimeclassesVocê pode usar as informações das seguintes maneiras:
-
Determinar a causa de um job que falhou: Verifique os valores
ReasoneMessageda condiçãoFailed. -
Reexecutar um job: Remova o campo
Statuspara aquele job específico do CRDHelmChart. O controlador implanta um novo job.
CRD ManagedChart
Rancher usa SUSE® Rancher Prime: Continuous Delivery para instalar gráficos em clusters de destino. SUSE Virtualization tem apenas um cluster de destino (fleet-local/local).
SUSE® Rancher Prime: Continuous Delivery implanta um agente em cada cluster de destino via helm install, para que você possa encontrar o gráfico fleet-agent-local usando o comando helm list -A. O CRD cluster.fleet.cattle.io contém o status do agente.
apiVersion: fleet.cattle.io/v1alpha1
kind: Cluster
metadata:
name: local
namespace: fleet-local
spec:
agentAffinity:
nodeAffinity:
preferredDuringSchedulingIgnoredDuringExecution:
- preference:
matchExpressions:
- key: fleet.cattle.io/agent
operator: In
values:
- "true"
weight: 1
agentNamespace: cattle-fleet-local-system
clientID: xd8cgpm2gq5w25qf46r8ml6qxvhsg858g64s5k7wj5h947vs5sxbwd
kubeConfigSecret: local-kubeconfig
kubeConfigSecretNamespace: fleet-local
redeployAgentGeneration: 1
status:
agent:
lastSeen: "2025-09-01T07:09:28Z"
namespace: cattle-fleet-local-system
agentAffinityHash: f50425c0999a8e18c2d104cdb8cb063762763f232f538b5a7c8bdb61
agentDeployedGeneration: 1
agentMigrated: true
agentNamespaceMigrated: true
agentTLSMode: system-store
apiServerCAHash: 158866807fdf372a1f1946bb72d0fbcdd66e0e63c4799f9d4df0e18b
apiServerURL: https://10.53.0.1:443
cattleNamespaceMigrated: true
conditions:
- lastUpdateTime: "2025-08-28T04:43:02Z"
status: "True"
type: Processed
- lastUpdateTime: "2025-08-28T10:08:31Z"
status: "True"
type: Imported
- lastUpdateTime: "2025-08-28T10:08:30Z"
status: "True"
type: Reconciled
- lastUpdateTime: "2025-08-28T10:09:30Z"
status: "True"
type: ReadyRancher converte o CRD ManagedChart em um recurso Bundle com um prefixo mcc-. O agente SUSE® Rancher Prime: Continuous Delivery observa recursos Bundle e os implanta no cluster de destino. O recurso BundleDeployment contém o status da implantação.
O controlador SUSE® Rancher Prime: Continuous Delivery não envia dados para o agente. Em vez disso, o agente consulta os dados de recurso Bundle do cluster no qual o controlador SUSE® Rancher Prime: Continuous Delivery está instalado. Em SUSE Virtualization, o controlador e o agente SUSE® Rancher Prime: Continuous Delivery estão no mesmo cluster, portanto, problemas de rede não são uma preocupação.
$ kubectl get bundledeployments -A -o jsonpath='{range .items[*]}{"Namespace: "}{.metadata.namespace}{"\nName: "}{.metadata.name}{"\nStatus:\n"}{range .status.conditions[*]}{" - Type: "}{.type}{"\n Status: "}{.status}{"\n Reason: "}{.reason}{"\n Message: "}{.message}{"\n"}{end}{"\n"}{end}'
Namespace: cluster-fleet-local-local-1a3d67d0a899
Name: fleet-agent-local
Status:
- Type: Installed
Status: True
Reason:
Message:
- Type: Deployed
Status: True
Reason:
Message:
- Type: Ready
Status: True
Reason:
Message:
- Type: Monitored
Status: True
Reason:
Message:
Namespace: cluster-fleet-local-local-1a3d67d0a899
Name: mcc-harvester
Status:
- Type: Installed
Status: True
Reason:
Message:
- Type: Deployed
Status: True
Reason:
Message:
- Type: Ready
Status: True
Reason:
Message:
- Type: Monitored
Status: True
Reason:
Message:
Namespace: cluster-fleet-local-local-1a3d67d0a899
Name: mcc-harvester-crd
Status:
- Type: Installed
Status: True
Reason:
Message:
- Type: Deployed
Status: True
Reason:
Message:
- Type: Ready
Status: True
Reason:
Message:
- Type: Monitored
Status: True
Reason:
Message:
Namespace: cluster-fleet-local-local-1a3d67d0a899
Name: mcc-kubeovn-operator-crd
Status:
- Type: Installed
Status: True
Reason:
Message:
- Type: Deployed
Status: True
Reason:
Message:
- Type: Ready
Status: True
Reason:
Message:
- Type: Monitored
Status: True
Reason:
Message:
Namespace: cluster-fleet-local-local-1a3d67d0a899
Name: mcc-rancher-logging-crd
Status:
- Type: Installed
Status: True
Reason:
Message:
- Type: Deployed
Status: True
Reason:
Message:
- Type: Ready
Status: True
Reason:
Message:
- Type: Monitored
Status: True
Reason:
Message:
Namespace: cluster-fleet-local-local-1a3d67d0a899
Name: mcc-rancher-monitoring-crd
Status:
- Type: Installed
Status: True
Reason:
Message:
- Type: Deployed
Status: True
Reason:
Message:
- Type: Ready
Status: True
Reason:
Message:
- Type: Monitored
Status: True
Reason:
Message:Se você alterar a imagem de implantação harvester-system/harvester, o agente SUSE® Rancher Prime: Continuous Delivery detecta a mudança e atualiza o status correspondente no recurso BundleDeployment.
Exemplo:
status:
appliedDeploymentID: s-89f9ce3f33c069befb4ebdceaa103af7b71db0e70a39760cb6653366964e5:1cd9188211e318033f89b77acf7b996
e5bb3d9a25319528c47dc052528056f78
conditions:
- lastUpdateTime: "2025-08-28T04:44:18Z"
status: "True"
type: Installed
- lastUpdateTime: "2025-08-28T04:44:18Z"
status: "True"
type: Deployed
- lastUpdateTime: "2025-09-01T07:40:28Z"
message: deployment.apps harvester-system/harvester modified {"spec":{"template":{"spec":{"containers":[{"env":[{"
name":"HARVESTER_SERVER_HTTPS_PORT","value":"8443"},{"name":"HARVESTER_DEBUG","value":"false"},{"name":"HARVESTER_SERV
ER_HTTP_PORT","value":"0"},{"name":"HCI_MODE","value":"true"},{"name":"RANCHER_EMBEDDED","value":"true"},{"name":"HARV
ESTER_SUPPORT_BUNDLE_IMAGE_DEFAULT_VALUE","value":"{\"repository\":\"rancher/support-bundle-kit\",\"tag\":\"master-hea
d\",\"imagePullPolicy\":\"IfNotPresent\"}"},{"name":"NAMESPACE","valueFrom":{"fieldRef":{"apiVersion":"v1","fieldPath"
:"metadata.namespace"}}}],"image":"frankyang/harvester:fix-renovate-head","imagePullPolicy":"IfNotPresent","name":"api
server","ports":[{"containerPort":8443,"name":"https","protocol":"TCP"},{"containerPort":6060,"name":"profile","protoc
ol":"TCP"}],"resources":{"requests":{"cpu":"250m","memory":"256Mi"}},"securityContext":{"appArmorProfile":{"type":"Unc
onfined"},"capabilities":{"add":["SYS_ADMIN"]}},"terminationMessagePath":"/dev/termination-log","terminationMessagePol
icy":"File"}]}}}}O console mostra Setting up Harvester após a instalação do dia 0
Descrição do problema
Após uma instalação bem-sucedida, o console mostra persistentemente Setting up Harvester. Embora a maioria das operações de UI e CLI permaneçam inalteradas, tentativas de fazer upgrade são bloqueadas.
As seguintes informações são exibidas após você executar o comando kubectl get managedchart -n fleet-local harvester -oyaml:
...
status:
conditions:
- lastUpdateTime: "2025-10-22T08:01:18Z"
message: 'NotReady(1) [Cluster fleet-local/local]; daemonset.apps harvester-system/harvester-network-controller
modified {"spec":{"template":{"spec":{"containers":[{"args":["agent"],"command":["harvester-network-controller"],
"env":[{"name":"NODENAME","valueFrom":{"fieldRef":{"apiVersion":"v1","fieldPath":"spec.nodeName"}}},
{"name":"NAMESPACE","valueFrom":{"fieldRef":{"apiVersion":"v1","fieldPath":"metadata.namespace"}}}],
"image":"rancher/harvester-network-controller:master-head","imagePullPolicy":"IfNotPresent","name":"harvester-network",
"resources":{"limits":{"cpu":"100m","memory":"128Mi"},"requests":{"cpu":"10m","memory":"64Mi"}},
"securityContext":{"privileged":true},"terminationMessagePath":"/dev/termination-log","terminationMessagePolicy":"File",
"volumeMounts":[{"mountPath":"/dev","name":"dev"},{"mountPath":"/lib/modules","name":"modules"}]}]}}}};'
status: "False"
type: ReadyCausa raiz
O console executa o seguinte comando para determinar se o status do ManagedChart harvester (no namespace fleet-local) é Ready.
cmd := exec.Command("/bin/sh", "-c", kubectl -n fleet-local get ManagedChart harvester -o jsonpath='{.status.conditions}' |
jq 'map(select(.type == "Ready" and .status == "True")) | length')O CRD ManagedChart é usado por SUSE® Rancher Prime: Continuous Delivery para gerenciar recursos via GitOps. Se algum desses recursos for modificado diretamente, ManagedChart registra e sinaliza as divergências. No exemplo acima, o erro ocorreu porque uma tag de imagem personalizada foi aplicada diretamente ao DaemonSet harvester-system/harvester-network-controller.
Para recuperar a lista completa de recursos ManagedChart, execute o comando kubectl get bundle -n fleet-local mcc-harvester -oyaml.
apiVersion: fleet.cattle.io/v1alpha1
kind: Bundle
metadata:
name: mcc-harvester
namespace: fleet-local
spec:
resources:
- content: H4s...===
encoding: base64+gz
charts/harvester-network-controller/templates/daemonset.yaml
- content: ...Solução
Você pode realizar uma das seguintes ações:
-
Reverter as alterações diretas feitas nos recursos afetados.
-
Atualizar
ManagedChartCRD com a configuração personalizada desejada usandokubectl edit managedchart -n fleet-local harvester.