|
本文档采用自动化机器翻译技术翻译。 尽管我们力求提供准确的译文,但不对翻译内容的完整性、准确性或可靠性作出任何保证。 若出现任何内容不一致情况,请以原始 英文 版本为准,且原始英文版本为权威文本。 |
从 v1.4.2 或 v1.4.3 升级到 v1.5.2
一般信息
已知问题
隔离升级在 Fluentd 和 Fluent Bit pod 中卡住,出现 ImagePullBackOff 错误
升级可能在过程的最开始卡住,表现为进度为 0% 和在 SUSE Virtualization UI 的 升级 对话框中标记为 待处理 的项目。
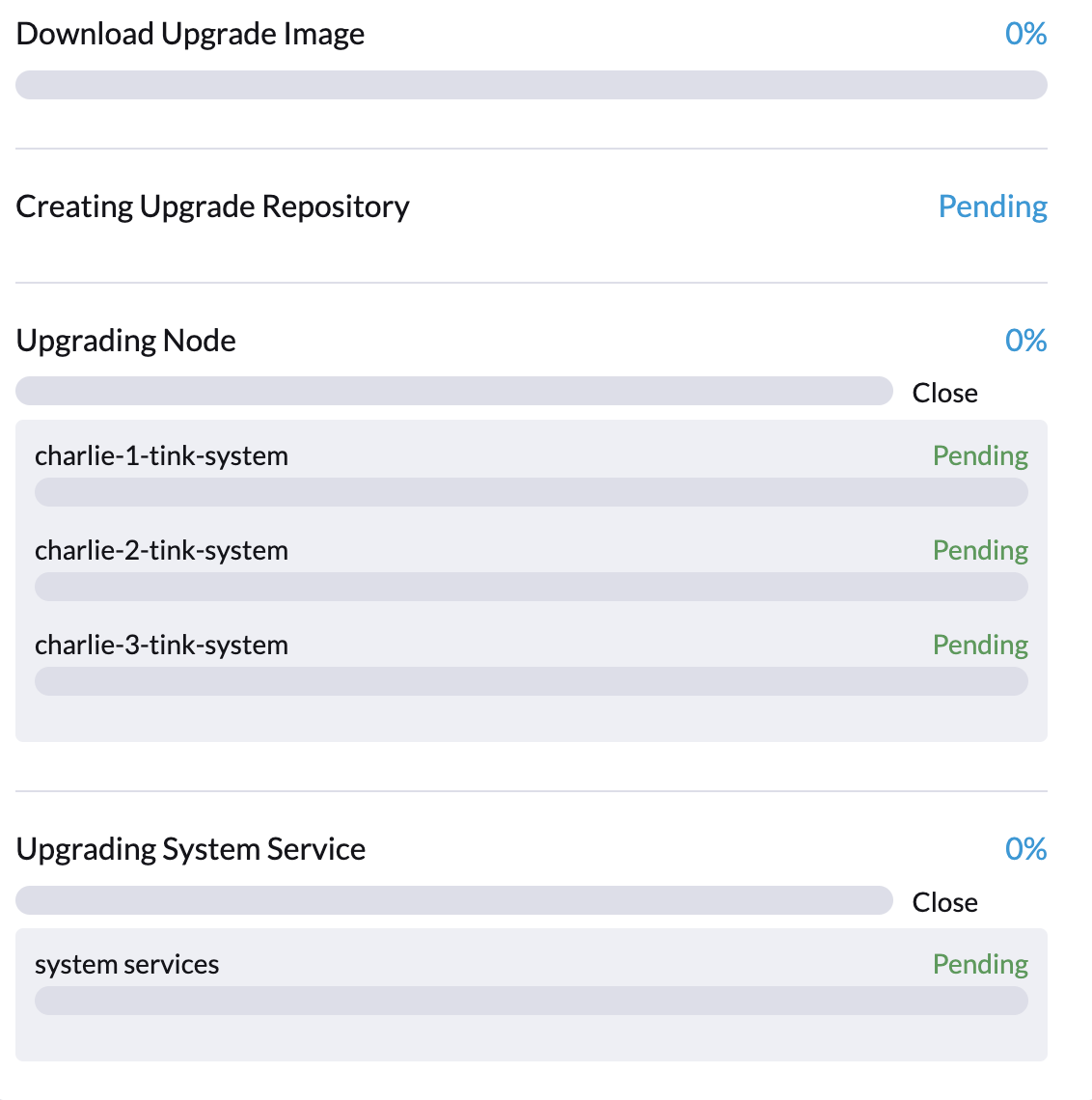
具体来说,Fluentd 和 Fluent Bit pod 可能会卡在 ImagePullBackOff 状态。要检查 pod 的状态,请运行以下命令:
$ kubectl -n harvester-system get upgrades -l harvesterhci.io/latestUpgrade=true
NAME AGE
hvst-upgrade-x2hz8 7m14s
$ kubectl -n harvester-system get upgradelogs -l harvesterhci.io/upgrade=hvst-upgrade-x2hz8
NAME UPGRADE
hvst-upgrade-x2hz8-upgradelog hvst-upgrade-x2hz8
$ kubectl -n harvester-system get pods -l harvesterhci.io/upgradeLog=hvst-upgrade-x2hz8-upgradelog
NAME READY STATUS RESTARTS AGE
hvst-upgrade-x2hz8-upgradelog-downloader-6cdb864dd9-6bw98 1/1 Running 0 7m7s
hvst-upgrade-x2hz8-upgradelog-infra-fluentbit-2nq7q 0/1 ImagePullBackOff 0 7m42s
hvst-upgrade-x2hz8-upgradelog-infra-fluentbit-697wf 0/1 ImagePullBackOff 0 7m42s
hvst-upgrade-x2hz8-upgradelog-infra-fluentbit-kd8kl 0/1 ImagePullBackOff 0 7m42s
hvst-upgrade-x2hz8-upgradelog-infra-fluentd-0 0/2 ImagePullBackOff 0 7m42s这发生是因为以下容器镜像既没有在集群节点中预加载,也没有从互联网拉取:
-
ghcr.io/kube-logging/fluentd:v1.15-ruby3 -
ghcr.io/kube-logging/config-reloader:v0.0.5 -
fluent/fluent-bit:2.1.8
要解决此问题,请执行以下任一操作:
-
更新 Logging CR 以使用已经在集群节点中预加载的镜像。要做到这一点,请对集群运行以下命令:
# Get the Logging CR names OPERATOR_LOGGING_NAME=$(kubectl get loggings -l app.kubernetes.io/name=rancher-logging -o jsonpath="{.items[0].metadata.name}") INFRA_LOGGING_NAME=$(kubectl get loggings -l harvesterhci.io/upgradeLogComponent=infra -o jsonpath="{.items[0].metadata.name}") # Gather image info from operator's Logging CR FLUENTD_IMAGE_REPO=$(kubectl get loggings $OPERATOR_LOGGING_NAME -o jsonpath="{.spec.fluentd.image.repository}") FLUENTD_IMAGE_TAG=$(kubectl get loggings $OPERATOR_LOGGING_NAME -o jsonpath="{.spec.fluentd.image.tag}") FLUENTBIT_IMAGE_REPO=$(kubectl get loggings $OPERATOR_LOGGING_NAME -o jsonpath="{.spec.fluentbit.image.repository}") FLUENTBIT_IMAGE_TAG=$(kubectl get loggings $OPERATOR_LOGGING_NAME -o jsonpath="{.spec.fluentbit.image.tag}") CONFIG_RELOADER_IMAGE_REPO=$(kubectl get loggings $OPERATOR_LOGGING_NAME -o jsonpath="{.spec.fluentd.configReloaderImage.repository}") CONFIG_RELOADER_IMAGE_TAG=$(kubectl get loggings $OPERATOR_LOGGING_NAME -o jsonpath="{.spec.fluentd.configReloaderImage.tag}") # Patch the Logging CR kubectl patch logging $INFRA_LOGGING_NAME --type=json -p="[{\"op\":\"replace\",\"path\":\"/spec/fluentbit/image\",\"value\":{\"repository\":\"$FLUENTBIT_IMAGE_REPO\",\"tag\":\"$FLUENTBIT_IMAGE_TAG\"}}]" kubectl patch logging $INFRA_LOGGING_NAME --type=json -p="[{\"op\":\"replace\",\"path\":\"/spec/fluentd/image\",\"value\":{\"repository\":\"$FLUENTD_IMAGE_REPO\",\"tag\":\"$FLUENTD_IMAGE_TAG\"}}]" kubectl patch logging $INFRA_LOGGING_NAME --type=json -p="[{\"op\":\"replace\",\"path\":\"/spec/fluentd/configReloaderImage\",\"value\":{\"repository\":\"$CONFIG_RELOADER_IMAGE_REPO\",\"tag\":\"$CONFIG_RELOADER_IMAGE_TAG\"}}]"Fluentd 和 Fluent Bit pod 的状态应该在一瞬间变为
Running,并且在更新 Logging CR 后,升级过程应该继续。如果 Fluentd pod 的状态仍为ImagePullBackOff,您可以删除该 pod 以强制其重启。UPGRADE_NAME=$(kubectl -n harvester-system get upgrades -l harvesterhci.io/latestUpgrade=true -o jsonpath='{.items[0].metadata.name}') UPGRADELOG_NAME=$(kubectl -n harvester-system get upgradelogs -l harvesterhci.io/upgrade=$UPGRADE_NAME -o jsonpath='{.items[0].metadata.name}') kubectl -n harvester-system delete pods -l harvesterhci.io/upgradeLog=$UPGRADELOG_NAME,harvesterhci.io/upgradeLogComponent=aggregator -
在可以访问互联网的计算机上,拉取所需的容器镜像,然后将其导出为 TAR 文件。接下来,将 TAR 文件传输到集群节点,然后在每个节点上运行以下命令以导入镜像:
# Pull down the three container images docker pull ghcr.io/kube-logging/fluentd:v1.15-ruby3 docker pull ghcr.io/kube-logging/config-reloader:v0.0.5 docker pull fluent/fluent-bit:2.1.8 # Export the images to a tar file docker save \ ghcr.io/kube-logging/fluentd:v1.15-ruby3 \ ghcr.io/kube-logging/config-reloader:v0.0.5 \ fluent/fluent-bit:2.1.8 > upgradelog-images.tar # After transferring the tar file to the cluster nodes, import the images (need to be run on each node) ctr -n k8s.io images import upgradelog-images.tar在镜像预加载后,升级过程应该继续。
-
(不推荐)在禁用日志记录的情况下重新启动升级过程。确保在 升级 对话框中 启用日志记录 复选框未被选中。
-
相关问题: #7955
使用可迁移 RWX 卷的虚拟机意外重启。
使用可迁移 RWX 卷 的虚拟机在 CSI 插件 pod 重启时意外重启。此问题影响 SUSE Virtualization v1.4.x、v1.5.0 和 v1.5.1。
解决方法是在开始升级之前,在 SUSE Storage UI 上禁用设置 意外分离卷时自动删除工作负载 pod。升级完成后,您必须再次启用该设置。
该问题将在 SUSE Storage v1.8.3、v1.9.1 及更高版本中修复。 SUSE Virtualization v1.6.0 将包含 SUSE Storage v1.9.1。