|
本文档采用自动化机器翻译技术翻译。 尽管我们力求提供准确的译文,但不对翻译内容的完整性、准确性或可靠性作出任何保证。 若出现任何内容不一致情况,请以原始 英文 版本为准,且原始英文版本为权威文本。 |
从 v1.4.0 升级到 v1.4.1
一般信息
每当有新的 SUSE Virtualization 版本可供升级时,升级 按钮会出现在 仪表板 屏幕上。有关更多信息,请参见 开始升级。
对于隔离环境,请参见 准备隔离升级。
|
在开始升级之前,请检查每个节点上操作系统映像的磁盘使用情况。为此,请通过 SSH 访问节点并运行命令 示例: 如果
|
在 SUSE Rancher Prime v2.10.1 上更新 Harvester UI 扩展
您必须使用 v1.0.3 的 Harvester UI 扩展来导入 SUSE Virtualization v1.4.1 集群到 Rancher v2.10.1。
-
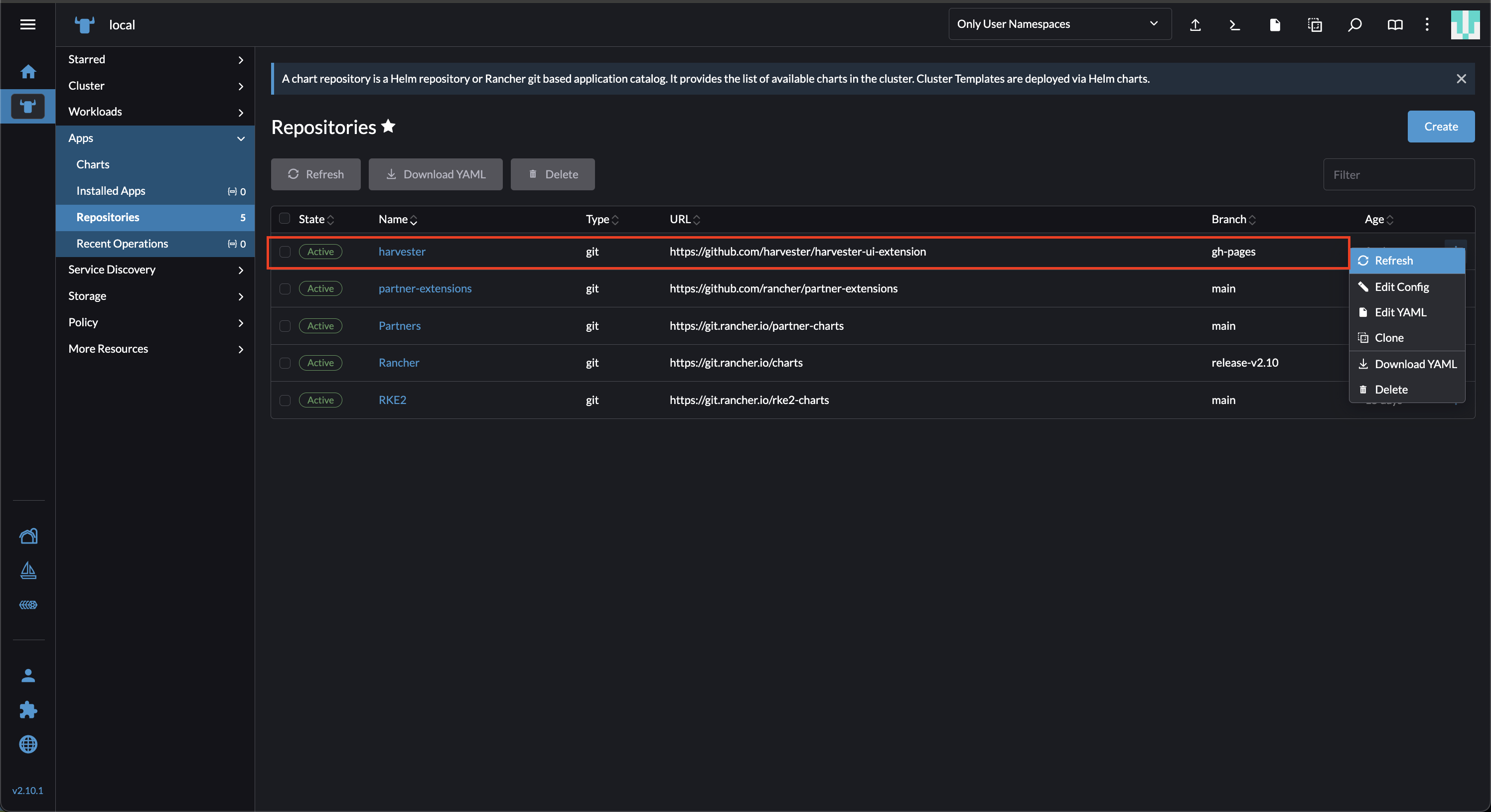
在 Rancher UI 上,转到 本地 → 应用 → 储存库。
-
找到名为 harvester 的储存库,然后选择 ⋮ → 刷新。
该储存库具有以下属性:
-
分支: gh-pages
-
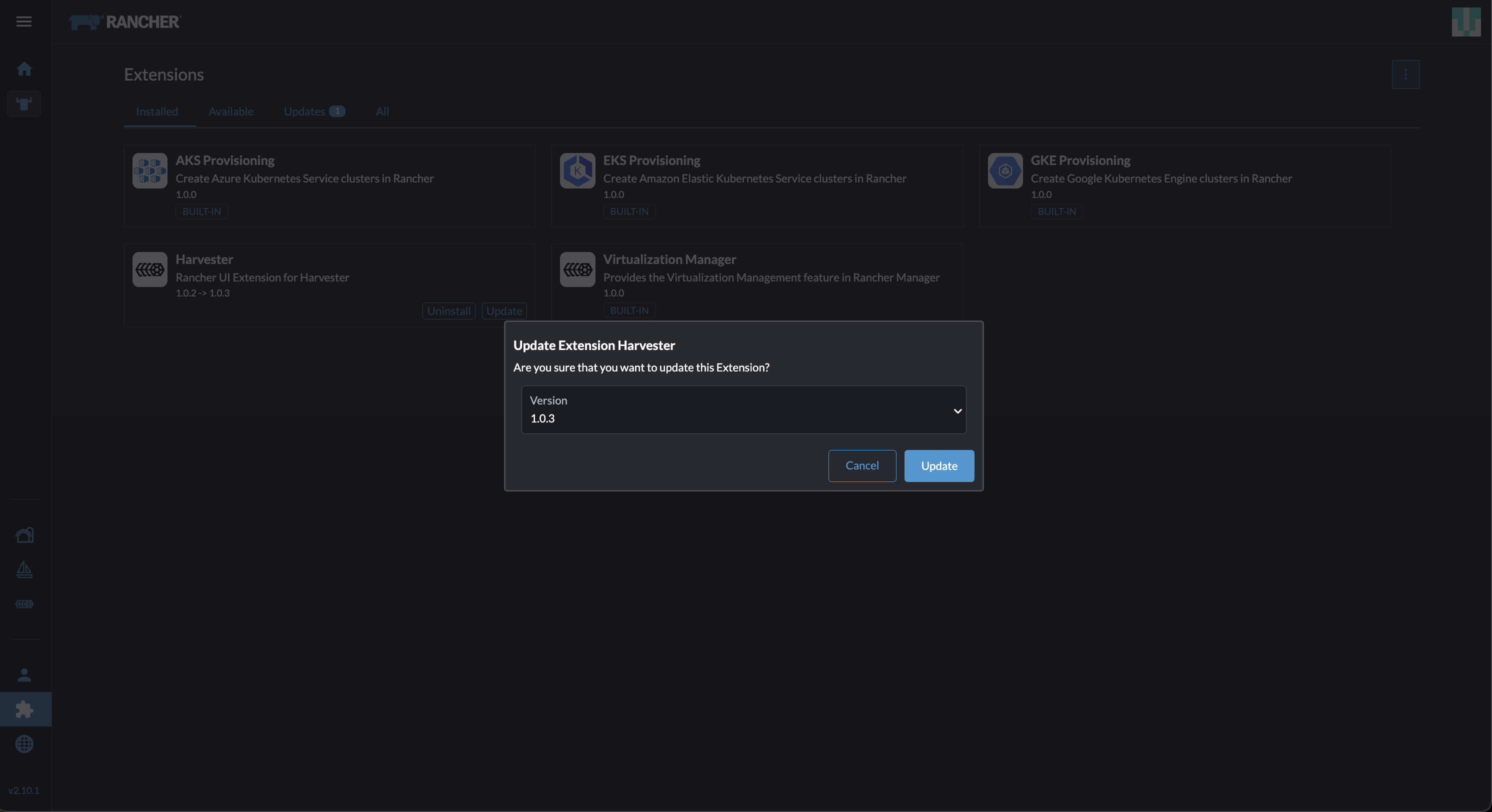
转到 扩展 屏幕。
-
找到名为 Harvester 的扩展,然后点击 更新。
-
选择版本 1.0.3,然后点击 更新。
-
请稍等,等待扩展更新完成,然后刷新屏幕。
|
Rancher UI 在扩展更新后显示错误消息。当您刷新屏幕时,错误消息会消失。 此问题在 Rancher v2.10.0 和 v2.10.1 中存在,将在 v2.10.2 中修复。 |
已知问题
1.升级卡在 "预排空" 状态
升级过程可能会卡在 "预排空" 状态。Kubernetes 应该在节点上排空工作负载,但某些因素可能导致该过程停滞。
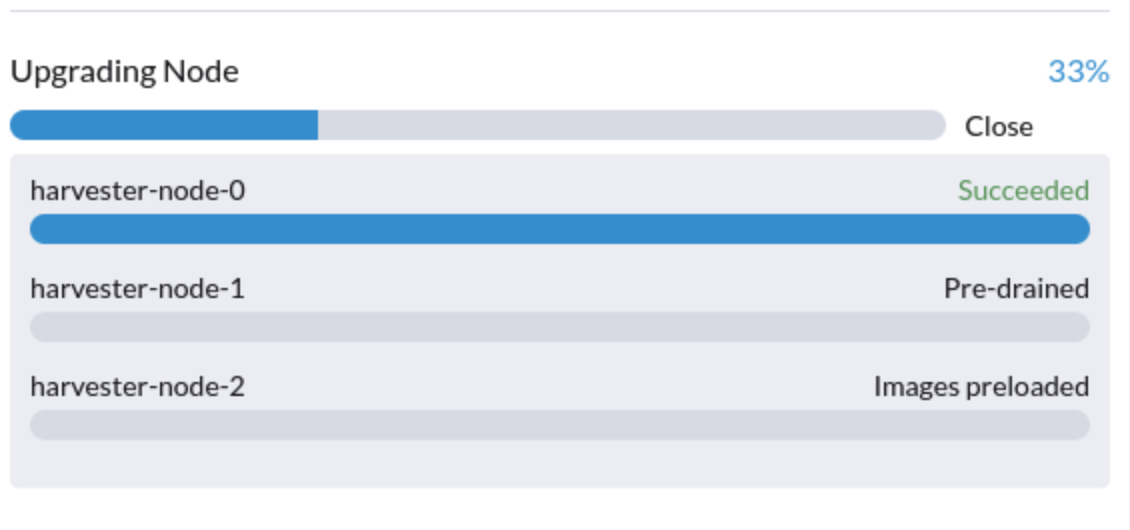
一个可能的原因是与 Longhorn 实例管理器的孤立引擎相关的处理。要确定这是否适用于您的情况,请执行以下步骤:
-
检查卡住节点上
instance-managerpod 的名称。示例:
卡住的节点是
harvester-node-1,实例管理器 pod 的名称是instance-manager-d80e13f520e7b952f4b7593fc1883e2a。$ kubectl get pods -n longhorn-system --field-selector spec.nodeName=harvester-node-1 | grep instance-manager instance-manager-d80e13f520e7b952f4b7593fc1883e2a 1/1 Running 0 3d8h -
检查 Longhorn Manager 日志以获取信息消息。
示例:
$ kubectl -n longhorn-system logs daemonsets/longhorn-manager ... time="2025-01-14T00:00:01Z" level=info msg="Node instance-manager-d80e13f520e7b952f4b7593fc1883e2a is marked unschedulable but removing harvester-node-1 PDB is blocked: some volumes are still attached InstanceEngines count 1 pvc-9ae0e9a5-a630-4f0c-98cc-b14893c74f9e-e-0" func="controller.(*InstanceManagerController).syncInstanceManagerPDB" file="instance_manager_controller.go:823" controller=longhorn-instance-manager node=harvester-node-1由于引擎
pvc-9ae0e9a5-a630-4f0c-98cc-b14893c74f9e-e-0,instance-managerpod 无法被排空。 -
检查引擎是否仍在卡住的节点上运行。
示例:
$ kubectl -n longhorn-system get engines.longhorn.io pvc-9ae0e9a5-a630-4f0c-98cc-b14893c74f9e-e-0 -o jsonpath='{"Current state: "}{.status.currentState}{"\nNode ID: "}{.spec.nodeID}{"\n"}' Current state: stopped Node ID:如果输出显示引擎未运行或未找到,则问题可能存在。
-
检查所有卷是否健康。
kubectl get volumes -n longhorn-system -o yaml | yq '.items[] | select(.status.state == "attached")| .status.robustness'所有卷必须标记为
healthy。如果不是这种情况,请报告该问题。 -
移除
instance-managerpod 的 PodDisruptionBudget (PDB)。示例:
kubectl delete pdb instance-manager-d80e13f520e7b952f4b7593fc1883e2a -n longhorn-system
2.使用不是 harvester-longhorn 的默认 StorageClass 进行升级
Harvester 将注释 storageclass.kubernetes.io/is-default-class: "true" 添加到 harvester-longhorn,这是原始的默认 StorageClass。当您用另一个 StorageClass 替换 harvester-longhorn 时,会发生以下情况:
-
Harvester ManagedChart 显示错误信息
cannot patch "harvester-longhorn" with kind StorageClass: admission webhook "validator.harvesterhci.io" denied the request: default storage class %!s(MISSING) already exists, please reset it first。 -
Webhook 拒绝升级请求。
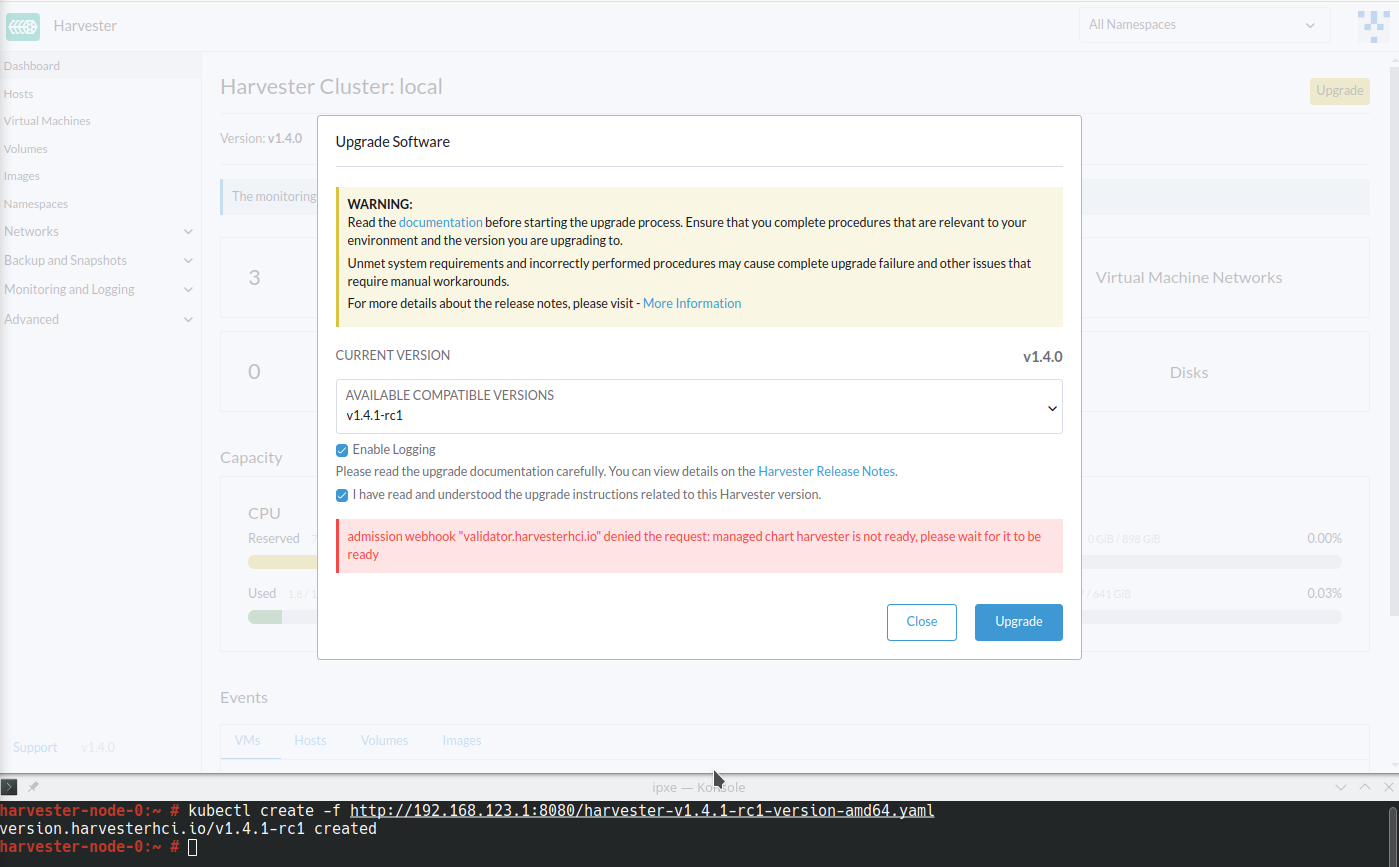
您可以执行以下任一种解决方法:
-
将
harvester-longhorn设置为默认 StorageClass。 -
将
spec.values.storageClass.defaultStorageClass: false添加到harvesterManagedChart。kubectl edit managedchart harvester -n fleet-local -
将
timeoutSeconds: 600添加到 Harvester ManagedChart 规格。kubectl edit managedchart harvester -n fleet-local
相关问题: #7375
3.升级卡在 "等待重启" 状态
在安装 Harvester v1.4.1 镜像到节点并启动重启后,升级过程可能会卡在 "等待重启" 状态。此时,升级控制器会观察 Harvester v1.4.1 操作系统是否正在运行。
如果 Harvester v1.4.1 镜像(以下简称 active.img)因任何原因无法启动,节点将自动以回退模式重启,并启动之前安装的 Harvester v1.4.0 镜像(以下简称 passive.img)。升级控制器无法检测到预期的操作系统,因此升级保持卡住,直到管理员修复 active.img 的问题。
由于在升级过程中 COS_STATE 分区的磁盘空间不足,active.img 可能会损坏并无法启动。如果 Harvester v1.4.0 最初安装在节点上,并且系统配置为使用单独的数据磁盘,则会发生这种情况。在以下情况下不会发生此问题:
-
系统有一个磁盘,操作系统和数据共享该磁盘。
-
最初安装了早期的 Harvester 版本,然后升级到 v1.4.0。
要检查您的环境中是否存在此问题,请执行以下步骤:
-
通过 SSH 访问节点,并使用 root 账户登录。
-
运行命令
cat /proc/cmdline和head -n1 /etc/harvester-release.yaml。示例:
# cat /proc/cmdline BOOT_IMAGE=(loop0)/boot/vmlinuz console=tty1 root=LABEL=COS_STATE cos-img/filename=/cOS/passive.img panic=0 net.ifnames=1 rd.cos.oemlabel=COS_OEM rd.cos.mount=LABEL=COS_OEM:/oem rd.cos.mount=LABEL=COS_PERSISTENT:/usr/local rd.cos.oemtimeout=120 audit=1 audit_backlog_limit=8192 intel_iommu=on amd_iommu=on iommu=pt multipath=off upgrade_failure # head -n1 /etc/harvester-release.yaml harvester: v1.4.0输出中出现
cos-img/filename=/cOS/passive.img和upgrade_failure表明系统已启动到备用模式。在/etc/harvester-release.yaml中的 Harvester 版本确认系统当前使用的是 v1.4.0 镜像。 -
通过运行命令
fsck.ext2 -nf /run/initramfs/cos-state/cOS/active.img检查active.img是否损坏。示例:
# fsck.ext2 -nf /run/initramfs/cos-state/cOS/active.img e2fsck 1.46.4 (18-Aug-2021) Pass 1: Checking inodes, blocks, and sizes Pass 2: Checking directory structure [...a list of various different errors may appear here...] e2fsck: aborted COS_ACTIVE: ********** WARNING: Filesystem still has errors ********** -
通过运行命令
lsblk -o NAME,LABEL,SIZE检查分区大小。示例:
# lsblk -o NAME,LABEL,SIZE NAME LABEL SIZE loop0 COS_ACTIVE 3G sr0 1024M vda 250G ├─vda1 COS_GRUB 64M ├─vda2 COS_OEM 64M ├─vda3 COS_RECOVERY 4G ├─vda4 COS_STATE 8G └─vda5 COS_PERSISTENT 237.9G vdb HARV_LH_DEFAULT 128G示例中的输出显示
COS_STATE分区的大小为 8G。在这种特定情况下,涉及一次不成功的升级尝试和损坏的`active.img`,该分区可能没有足够的可用空间使升级成功。
要修复此问题,请执行以下步骤:
-
如果您的集群有两个或更多节点,请通过 SSH 访问其余节点,并检查
active.img和passive.img的磁盘使用情况。# du -sh /run/initramfs/cos-state/cOS/* 1.7G /run/initramfs/cos-state/cOS/active.img 3.1G /run/initramfs/cos-state/cOS/passive.img如果
passive.img占用 3.1G 的磁盘空间,请使用 root 账户运行以下命令:# mount -o remount,rw /run/initramfs/cos-state # fallocate --dig-holes /run/initramfs/cos-state/cOS/passive.img # mount -o remount,ro /run/initramfs/cos-statepassive.img被转换为稀疏文件,应该只占用 1.7G 的磁盘空间(与active.img相同)。这确保其他节点有足够的可用空间,防止升级过程再次卡住。 -
通过 SSH 访问卡住的节点,然后使用 root 账户运行以下命令:
# mount -o remount,rw /run/initramfs/cos-state # cp /run/initramfs/cos-state/cOS/passive.img \ /run/initramfs/cos-state/cOS/active.img # tune2fs -L COS_ACTIVE /run/initramfs/cos-state/cOS/active.img # mount -o remount,ro /run/initramfs/cos-state现有的(干净的)
passive.img被复制到损坏的active.img上,并且标签设置正确。 -
重启卡住的节点,然后在 GRUB 启动屏幕上选择第一个条目(Harvester v1.4.1)。
GRUB 启动屏幕默认初始显示 Harvester v1.4.1(备用)。尽管 GRUB 上显示的是 Harvester v1.4.1(备用),系统仍然启动到 Harvester v1.4.0。
-
将
rootfs.squashfs从 Harvester v1.4.1 ISO 复制到卡住节点的方便位置。ISO可以在卡住的节点或其他系统上挂载。您可以使用
scp命令复制文件。 -
通过 SSH 访问卡住的节点,然后使用 root 账户运行以下命令:
# mkdir /tmp/manual-os-upgrade # mkdir /tmp/manual-os-upgrade/config # mkdir /tmp/manual-os-upgrade/rootfs # mount -o loop rootfs.squashfs /tmp/manual-os-upgrade/rootfs # cat > /tmp/manual-os-upgrade/config/config.yaml <<EOF upgrade: system: size: 3072 EOF # elemental upgrade \ --logfile /tmp/manual-os-upgrade/upgrade.log \ --directory /tmp/manual-os-upgrade/rootfs \ --config-dir /tmp/manual-os-upgrade/config \ --debug您必须在第四行中用复制的`rootfs.squashfs`的实际路径替换示例路径。
基于Harvester v1.4.1 ISO的根镜像生成一个新的(干净的)
active.img。如果发生任何错误,请保存`/tmp/manual-os-upgrade/upgrade.log`的副本。
-
运行以下命令:
# umount /tmp/manual-os-upgrade/rootfs # reboot节点应成功启动到Harvester v1.4.1,并且升级应按预期进行。
4.点击“Dismiss it”按钮后,升级会意外重启。
当您使用Rancher升级SUSE Virtualization时,Rancher UI 会显示一个带有“Dismiss it”按钮的对话框。点击此按钮可能会导致以下问题:
-
statusCR的`harvesterhci.io/v1beta1/upgrade`部分被清空,导致所有关于升级的重要信息丢失。 -
升级过程意外重启。
此问题影响Rancher v2.10.x,该版本使用了 v1.0.2、v1.0.3 和 v1.0.4 的 Harvester UI 扩展。所有SUSE Virtualization UI版本不受影响。该问题已在 Harvester UI 扩展 v1.0.5 和 v1.5.0 中修复。
为避免此问题,请执行以下任一操作:
-
使用SUSE Virtualization UI进行升级。在 SUSE Virtualization UI 上点击“忽略它”按钮不会导致意外行为。
-
不要在Rancher UI 上点击按钮,而是对集群运行以下命令:
kubectl -n harvester-system label upgrades -l harvesterhci.io/latestUpgrade=true harvesterhci.io/read-message=true
相关问题: #7791
5.使用可迁移 RWX 卷的虚拟机意外重启。
使用可迁移的 RWX 卷 的虚拟机在 CSI 插件 Pod 被重启时会意外重启。此问题影响 SUSE Virtualization v1.4.x、v1.5.0 和 v1.5.1。
解决方法是在升级之前,在 SUSE Storage 界面上禁用设置 意外分离卷时自动删除工作负载 Pod。升级完成后,您必须再次启用该设置。
该问题将在 SUSE Storage v1.8.3、v1.9.1 及更高版本中修复。SUSE Virtualization v1.6.0 将包含 SUSE Storage v1.9.1。