|
本文档采用自动化机器翻译技术翻译。 尽管我们力求提供准确的译文,但不对翻译内容的完整性、准确性或可靠性作出任何保证。 若出现任何内容不一致情况,请以原始 英文 版本为准,且原始英文版本为权威文本。 |
从 v1.2.2/v1.3.0 升级到 v1.3.1
已知问题
1.集群升级在第一个节点升级后卡住
|
为防止此问题发生,在开始升级过程之前标记 |
当将 Harvester 集群从 v1.2.2 或 v1.3.0 升级到 v1.3.1 时,升级过程在第一个节点升级后会卡住。
示例:
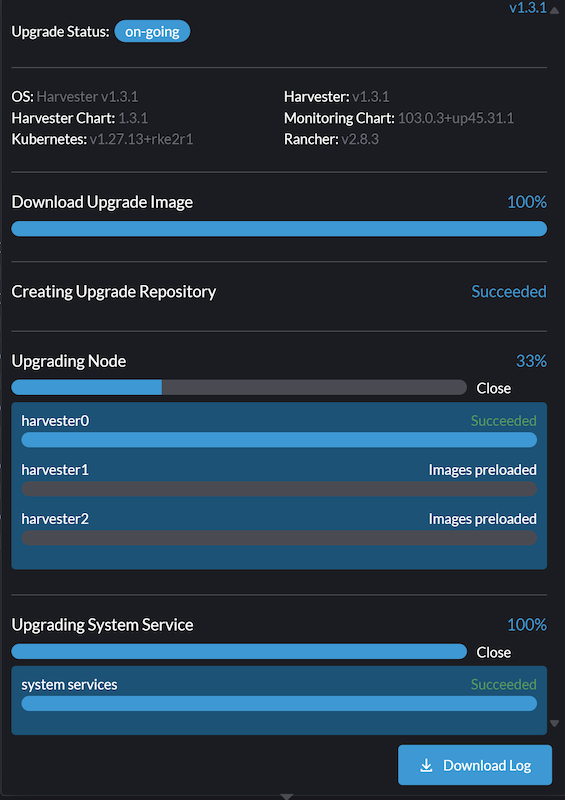
要解决此问题,请执行以下步骤:
-
识别集群状态:
kubectl get clusters.provisioning.cattle.io local -n fleet-local -o yaml输出示例:
... - lastUpdateTime: "2024-06-18T23:37:39Z" message: 'configuring bootstrap node(s) custom-9cb22ccf7984: waiting for kubelet to update' reason: Waiting status: Unknown type: Updated - lastUpdateTime: "2024-06-18T23:37:39Z" message: 'configuring bootstrap node(s) custom-9cb22ccf7984: waiting for kubelet to update' reason: Waiting status: Unknown type: Provisioned如果输出包含消息
waiting for kubelet,请继续下一步。 -
检查 capi-controller-manager pod 的日志:
kubectl logs -n cattle-provisioning-capi-system deployment/capi-controller-manager如果输出类似于以下示例,则问题可能存在于集群中。
2024-06-19T08:54:22.407423986Z W0619 08:54:22.407257 1 reflector.go:424] k8s.io/client-go@v0.26.1/tools/cache/reflector.go:169: failed to list *v1.Node: Unauthorized 2024-06-19T08:54:22.407470069Z E0619 08:54:22.407283 1 reflector.go:140] k8s.io/client-go@v0.26.1/tools/cache/reflector.go:169: Failed to watch *v1.Node: failed to list *v1.Node: Unauthorized 2024-06-19T08:55:05.153396619Z W0619 08:55:05.153190 1 reflector.go:424] k8s.io/client-go@v0.26.1/tools/cache/reflector.go:169: failed to list *v1.Node: Unauthorized 2024-06-19T08:55:05.153438978Z E0619 08:55:05.153217 1 reflector.go:140] k8s.io/client-go@v0.26.1/tools/cache/reflector.go:169: Failed to watch *v1.Node: failed to list *v1.Node: Unauthorized -
应用以下解决方法以恢复升级:
杀死并重启 capi-controller-manager pod。
示例:
kubectl rollout restart deployment/capi-controller-manager -n cattle-provisioning-capi-system
相关问题: #6041