PromQL-Abfragen für repräsentative Diagramme schreiben
Richtlinien
Wenn SUSE® Observability Daten in einem Diagramm anzeigt, muss es fast immer die Auflösung der gespeicherten Daten ändern, um sie in den verfügbaren Platz für das Diagramm einzupassen. Um die repräsentativsten Diagramme zu erhalten, befolgen Sie diese Richtlinien:
-
Fragen Sie nicht nach der Rohmetrik, sondern aggregieren Sie immer über die Zeit (unter Verwendung der
*_over_timeoderrateFunktionen). -
Verwenden Sie den
${__interval}Parameter als Bereich für Aggregationen über die Zeit, er wird sich automatisch mit der Auflösung des Diagramms anpassen. -
Verwenden Sie den
${__rate_interval}Parameter als Bereich fürrateAggregationen, er wird sich ebenfalls automatisch mit der Auflösung des Diagramms anpassen, berücksichtigt jedoch spezifische Verhaltensweisen vonrate. -
Projiziere Metriken nur auf die Labels, die durch Aggregation über verschiedene Zeitreihen verwendet werden.
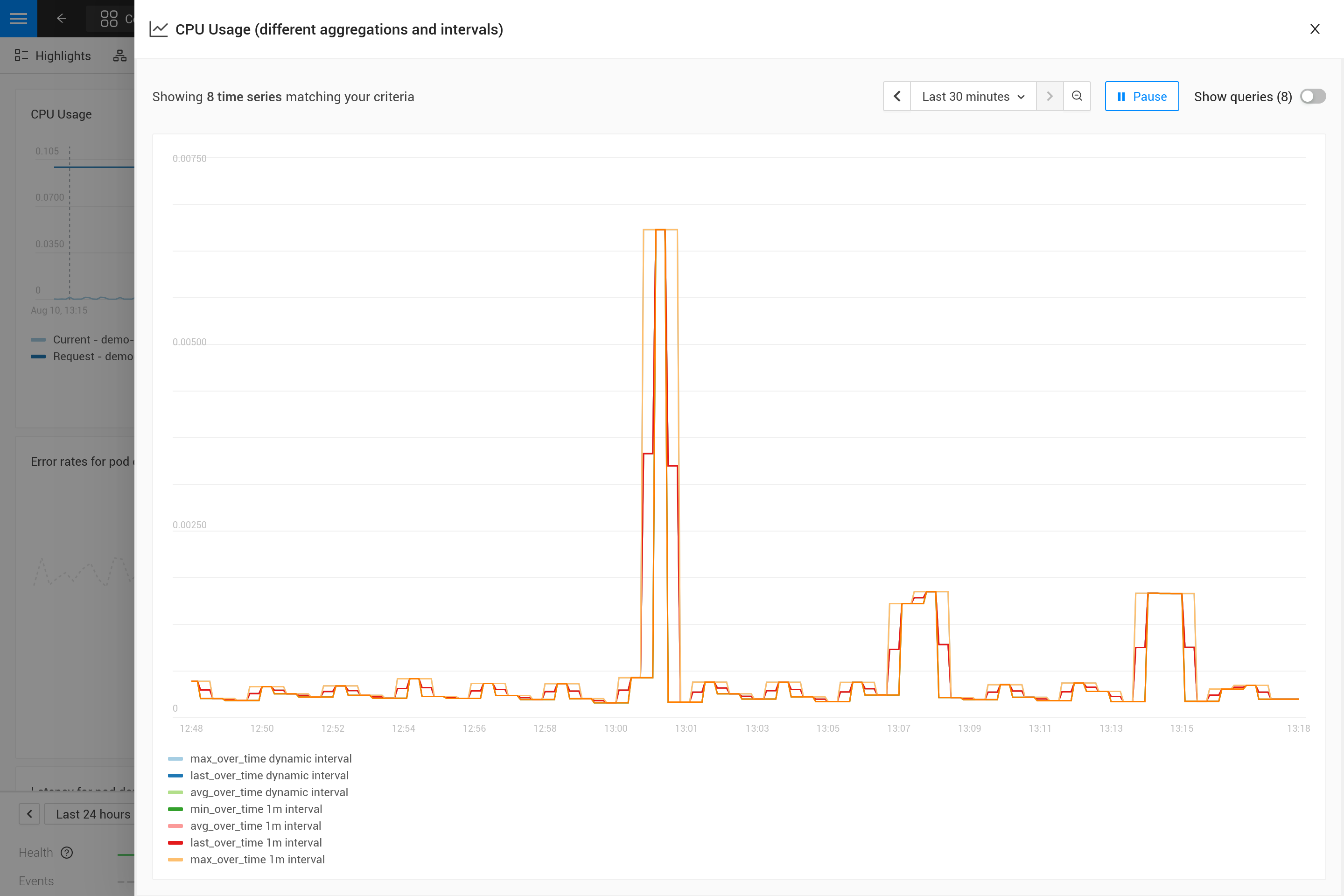
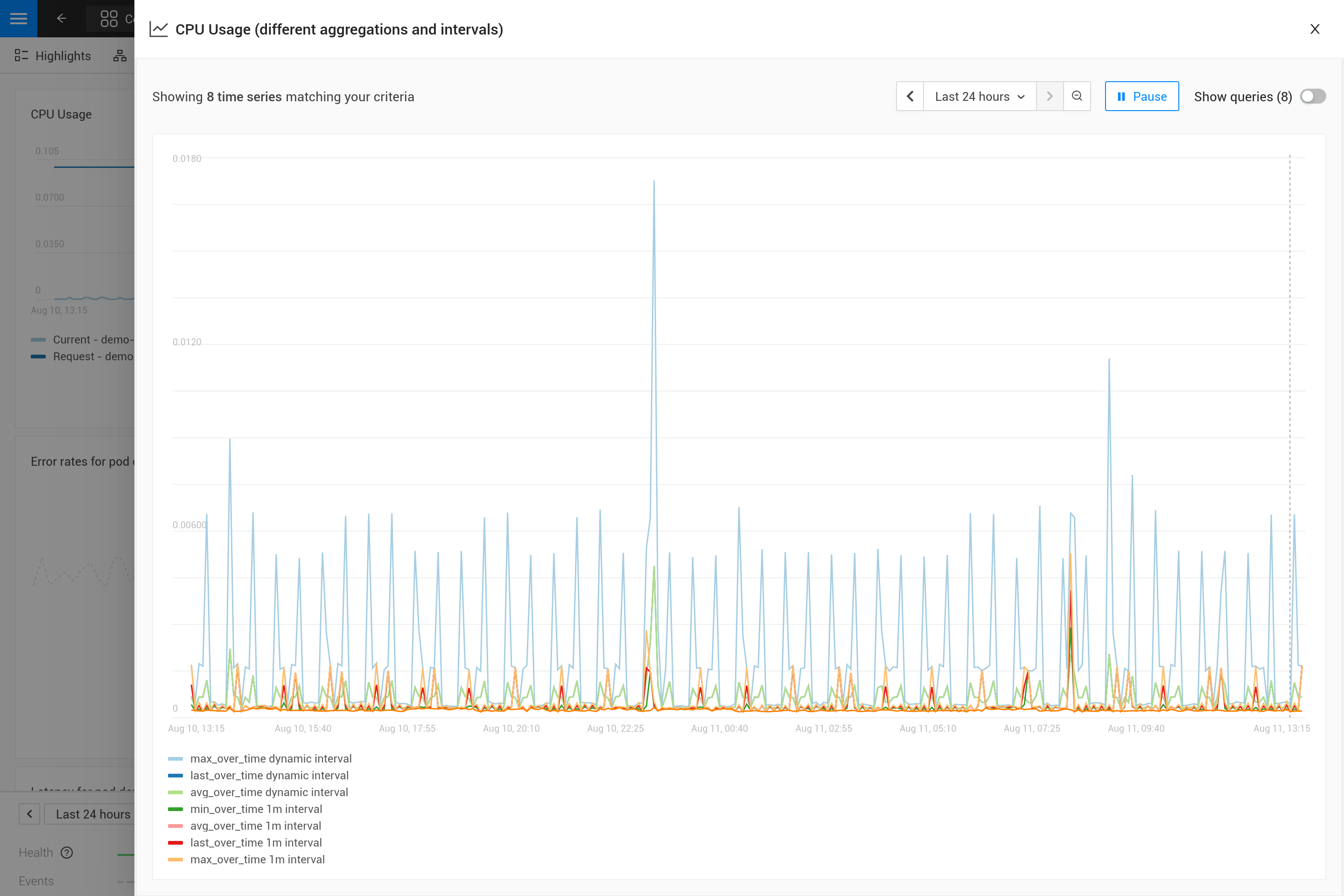
Die Anwendung einer Aggregation bedeutet oft, dass ein Kompromiss eingegangen wird, um bestimmte Muster in den Metriken mehr als andere zu betonen. Zum Beispiel zeigt max_over_time bei großen Zeitfenstern alle Spitzen, aber nicht alle Täler. Während min_over_time das genaue Gegenteil tut und avg_over_time sowohl Spitzen als auch Täler glätten wird. Um dieses Verhalten zu zeigen, hier ist ein Beispiel für eine Metrikbindung unter Verwendung der CPU-Nutzung von Pods. Um es selbst auszuprobieren, kopiere es in eine YAML-Datei und verwende die Kommandozeilenschnittstelle, um es anzuwenden in deinem eigenen SUSE® Observability (du kannst es später entfernen).
Das Projektieren potenziell mehrerer Zeitreihen auf eine Teilmenge ihrer Labels fasst Zeitreihen zusammen, die sich in einem irrelevanten Detail unterscheiden. Beim Erstellen einer Metrikbindung sind nur die Labels relevant, die in der Legende verwendet werden. Ähnlich sollten beim Erstellen von Monitoren nur die Labels zurückgegeben werden, die für die Zuordnung zu einem (Monitorstatus auf einer) Komponente benötigt werden.
- _type: MetricBinding
chartType: line
enabled: true
tags: {}
unit: short
name: CPU Usage (different aggregations and intervals)
priority: HIGH
identifier: urn:stackpack:my-stackpack:metric-binding:pod-cpu-usage-a
queries:
- expression: sum(max_over_time(container_cpu_usage{cluster_name="${tags.cluster-name}", namespace="${tags.namespace}", pod_name="${name}"}[${__interval}])) by (cluster_name, namespace, pod_name) /1000000000
alias: max_over_time dynamic interval
- expression: sum(min_over_time(container_cpu_usage{cluster_name="${tags.cluster-name}", namespace="${tags.namespace}", pod_name="${name}"}[${__interval}])) by (cluster_name, namespace, pod_name) /1000000000
alias: min_over_time dynamic interval
- expression: sum(avg_over_time(container_cpu_usage{cluster_name="${tags.cluster-name}", namespace="${tags.namespace}", pod_name="${name}"}[${__interval}])) by (cluster_name, namespace, pod_name) /1000000000
alias: avg_over_time dynamic interval
- expression: sum(last_over_time(container_cpu_usage{cluster_name="${tags.cluster-name}", namespace="${tags.namespace}", pod_name="${name}"}[${__interval}])) by (cluster_name, namespace, pod_name) /1000000000
alias: last_over_time dynamic interval
- expression: sum(max_over_time(container_cpu_usage{cluster_name="${tags.cluster-name}", namespace="${tags.namespace}", pod_name="${name}"}[1m])) by (cluster_name, namespace, pod_name) /1000000000
alias: max_over_time 1m interval
- expression: sum(min_over_time(container_cpu_usage{cluster_name="${tags.cluster-name}", namespace="${tags.namespace}", pod_name="${name}"}[1m])) by (cluster_name, namespace, pod_name) /1000000000
alias: min_over_time 1m interval
- expression: sum(avg_over_time(container_cpu_usage{cluster_name="${tags.cluster-name}", namespace="${tags.namespace}", pod_name="${name}"}[1m])) by (cluster_name, namespace, pod_name) /1000000000
alias: avg_over_time 1m interval
- expression: sum(last_over_time(container_cpu_usage{cluster_name="${tags.cluster-name}", namespace="${tags.namespace}", pod_name="${name}"}[1m])) by (cluster_name, namespace, pod_name) /1000000000
alias: last_over_time 1m interval
scope: (label = "stackpack:kubernetes" and type = "pod")
Nach der Anwendung öffne die Metrikperspektive für einen Pod in SUSE® Observability (vorzugsweise einen Pod mit einigen Spitzen und Tälern in der CPU-Nutzung). Vergrößern Sie das Diagramm mit dem Symbol in der oberen rechten Ecke, um eine bessere Ansicht zu erhalten. Jetzt können Sie auch das Zeitfenster ändern, um zu sehen, welche Auswirkungen die verschiedenen Aggregationen haben (30 Minuten vs. 24 Stunden zum Beispiel).
|
Wenn die Metrikbindung keine Aggregation angibt, wird SUSE® Observability automatisch die |
Warum ist Aggregation notwendig?
Zunächst einmal, warum sollten Sie eine Aggregation verwenden? Es macht keinen Sinn, mehr Datenpunkte aus dem Metrik-Speicher abzurufen, als im Diagramm Platz finden. Daher bestimmt SUSE® Observability automatisch den benötigten Schritt zwischen zwei Datenpunkten, um ein gutes Ergebnis zu erzielen. Für kurze Zeitfenster (zum Beispiel ein Diagramm, das nur eine Stunde Daten anzeigt) ergibt sich ein kleiner Schritt (etwa 10 Sekunden). Metriken werden oft nur alle 30 Sekunden erfasst, sodass bei 10-Sekunden-Schritten der gleiche Wert für drei Schritte wiederholt wird, bevor er zum nächsten Wert wechselt. Wenn man auf ein Zeitfenster von einer Woche herauszoomt, ist ein viel größerer Schritt erforderlich (etwa eine Stunde, abhängig von der genauen Größe des Diagramms auf dem Bildschirm).
Wenn die Schritte größer werden als die Auflösung der erfassten Datenpunkte, muss eine Entscheidung getroffen werden, wie die Datenpunkte des einstündigen Zeitraums in einen einzelnen Wert zusammengefasst werden. Wenn in der Abfrage bereits eine Aggregation über die Zeit angegeben ist, wird diese verwendet, um dies zu tun. Wenn jedoch keine Aggregation angegeben ist oder wenn das Aggregationsintervall kleiner ist als der Schritt, wird die last_over_time Aggregation verwendet, mit der step Größe als Intervall. Das Ergebnis ist, dass nur der letzte Datenpunkt für jede Stunde verwendet wird, um alle Datenpunkte in dieser Stunde zusammenzufassen.
Zusammenfassend lässt sich sagen, dass bei der Ausführung einer PromQL-Abfrage für einen Zeitraum von einer Woche mit einem Schritt von einer Stunde diese Abfrage:
container_cpu_usage /1000000000
automatisch in Folgendes umgewandelt wird:
last_over_time(container_cpu_usage[1h]) /1000000000
Probiere es selbst auf dem SUSE® Observability Spielplatz aus.
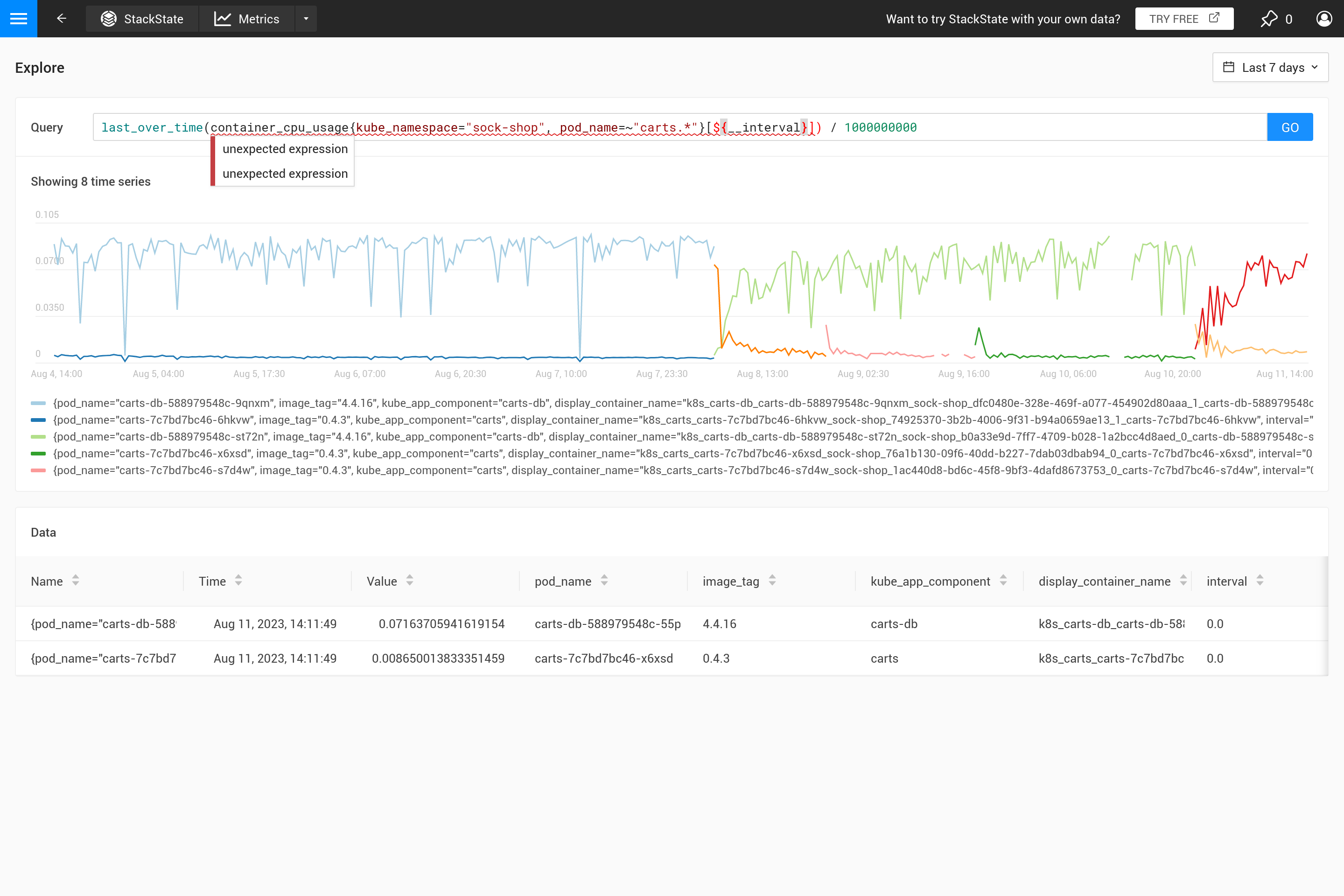
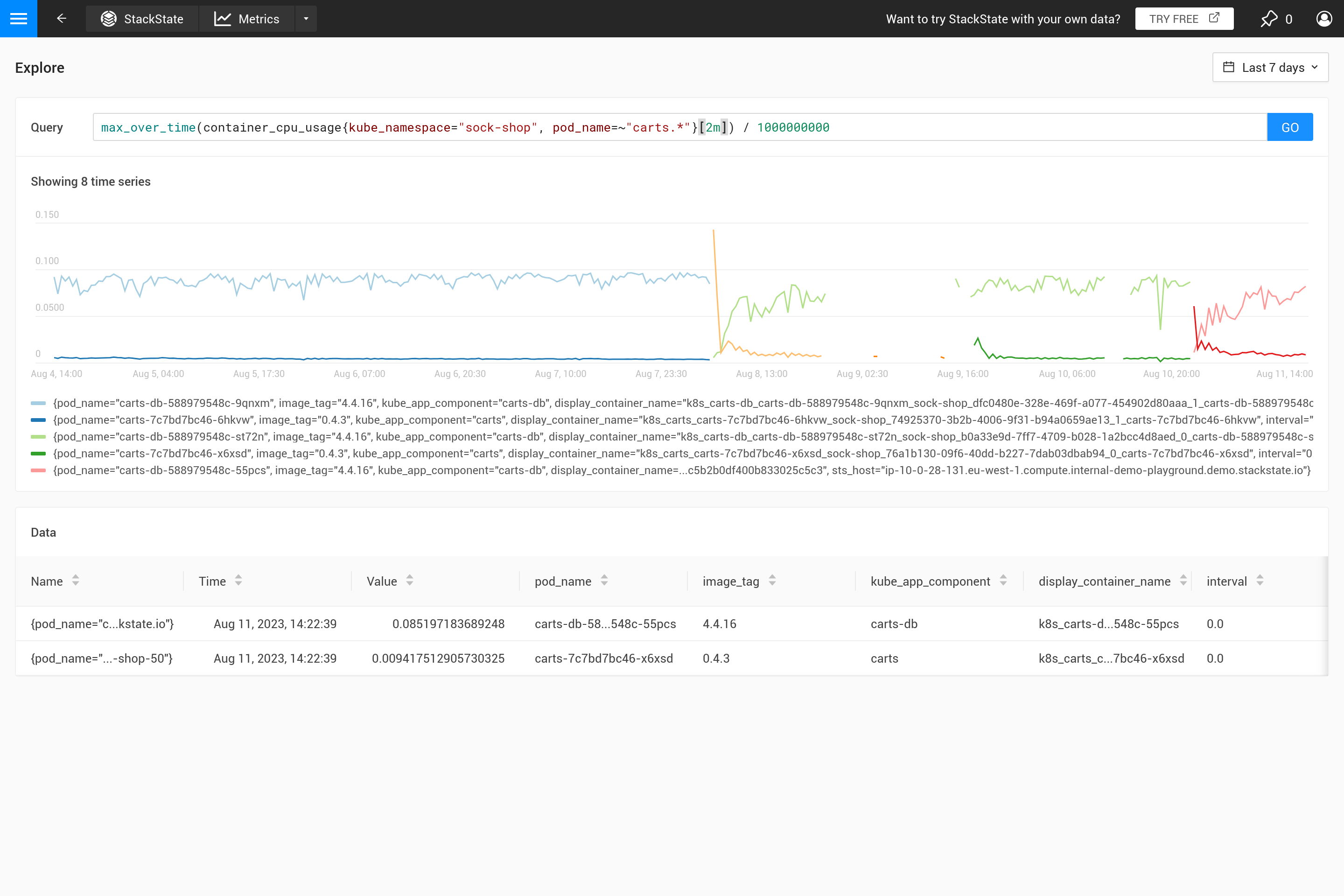
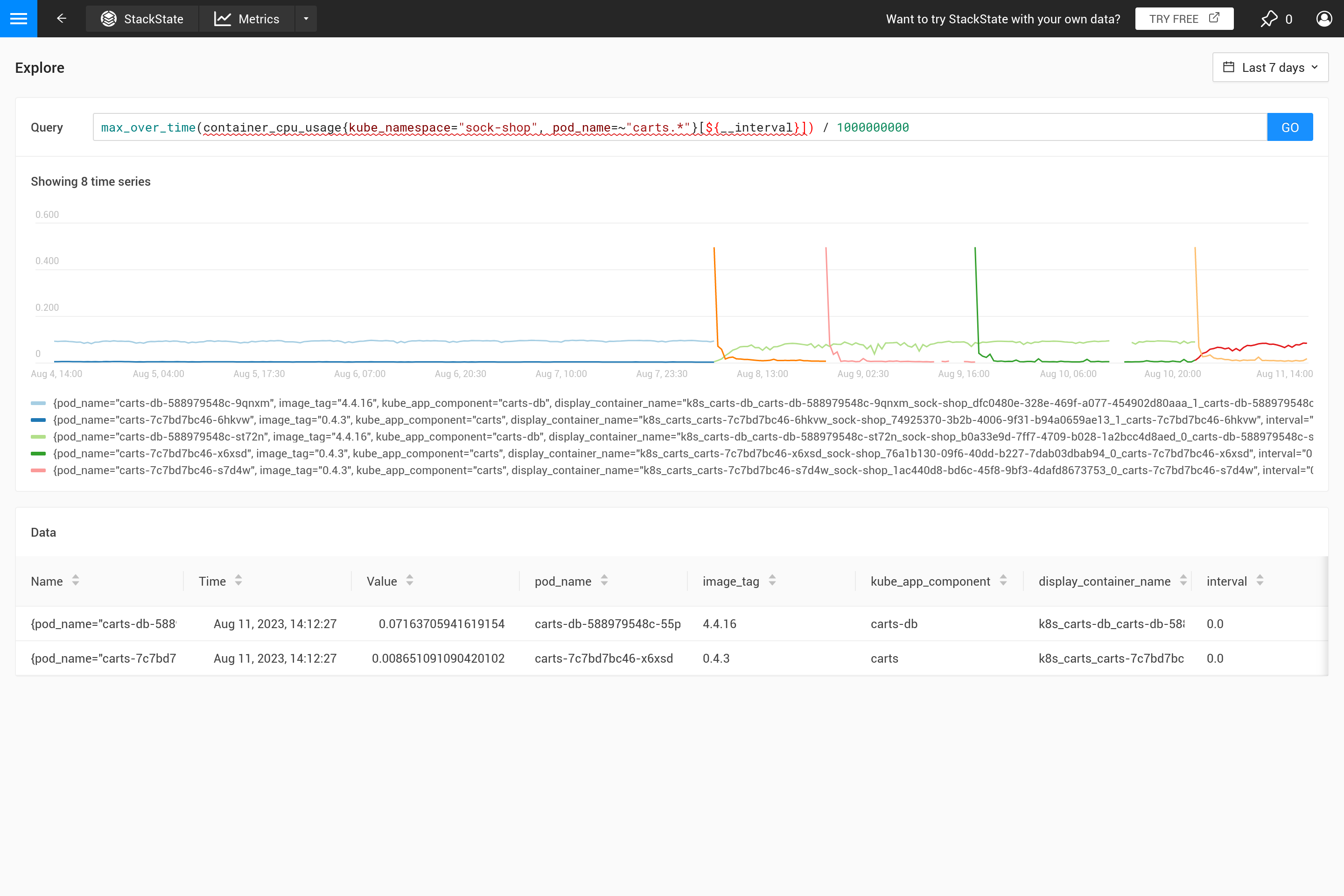
Oft ist dieses Verhalten nicht beabsichtigt, und es ist besser, selbst zu entscheiden, welche Art von Aggregation benötigt wird. Mit verschiedenen Aggregationsfunktionen ist es möglich, bestimmtes Verhalten zu betonen (auf Kosten, anderes Verhalten zu verbergen). Ist es wichtiger, Spitzen, Täler, ein glattes Diagramm usw. zu sehen? Verwenden Sie dann den ${__interval} Parameter für den Bereich, da er automatisch durch die step Größe ersetzt wird, die für die Abfrage verwendet wird. Das Ergebnis ist, dass alle Datenpunkte im Schritt verwendet werden.
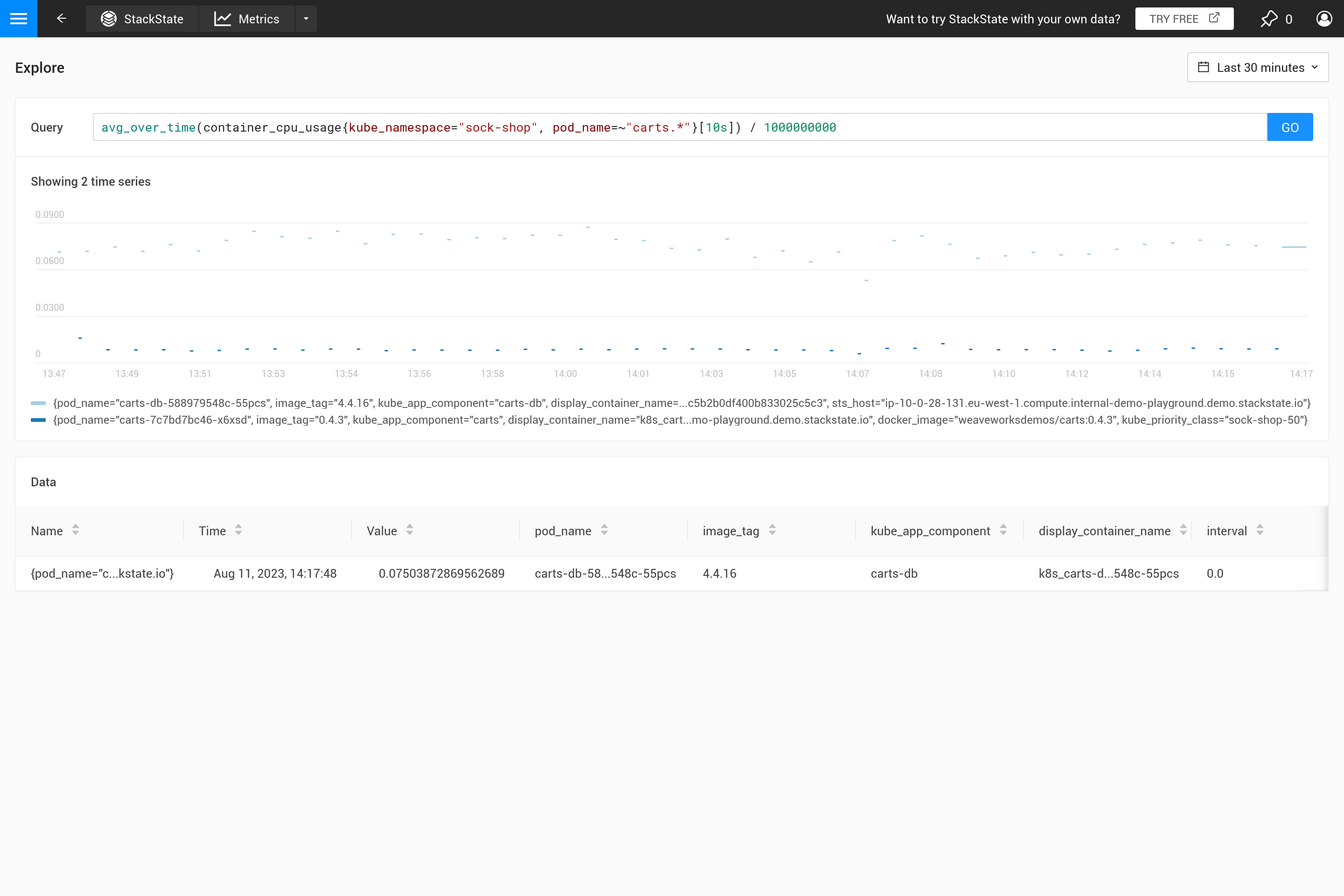
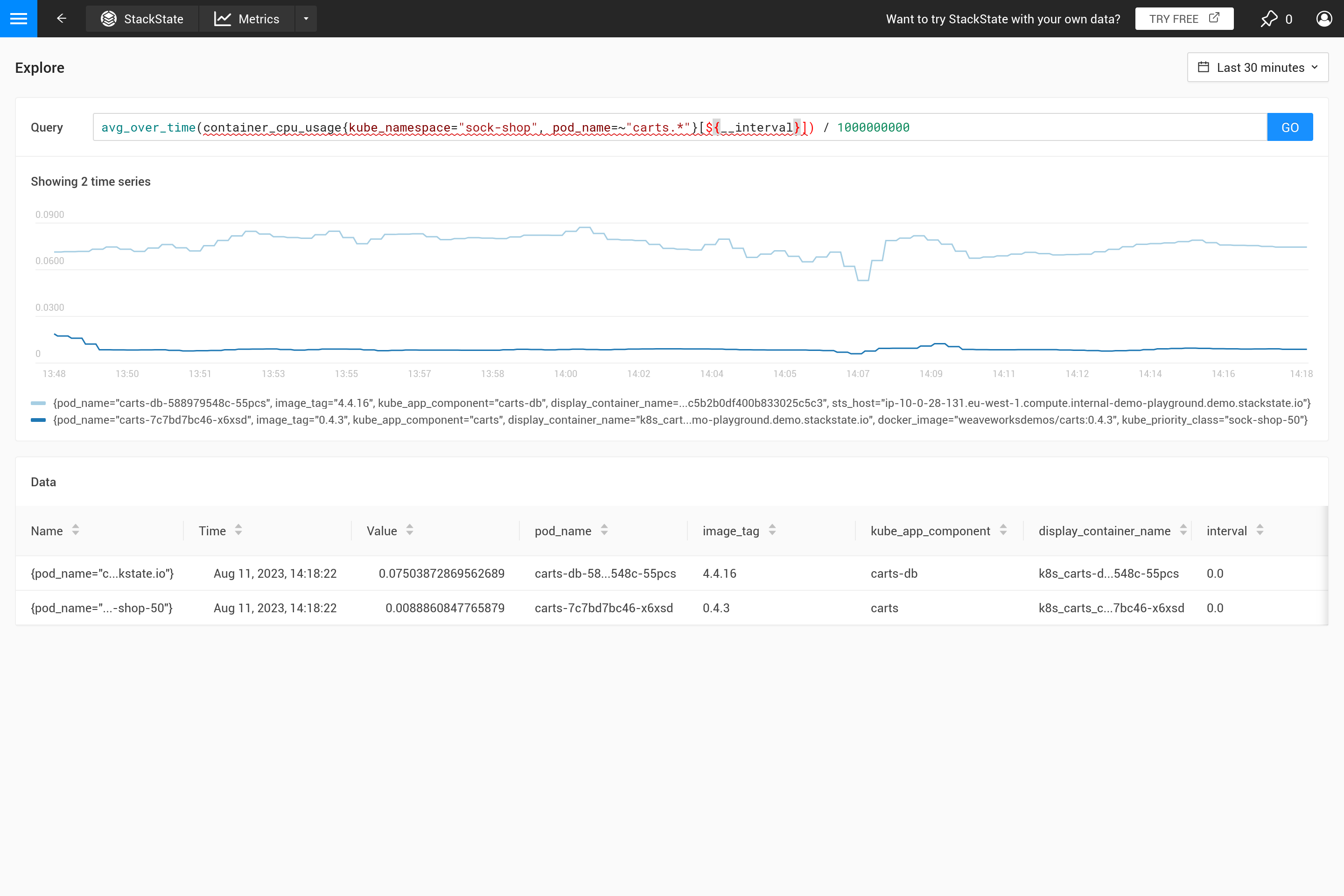
Der ${interval} Parameter verhindert ein weiteres Problem. Wenn die step Größe und damit der ${interval} Wert auf eine kleinere Größe als die Auflösung der gespeicherten Metrikdaten schrumpfen würde, würde dies zu Lücken im Diagramm führen.
Daher wird ${__interval} niemals kleiner als das Zweifache des standardmäßigen Abfrageintervalls (das standardmäßige Abfrageintervall beträgt 30 Sekunden) des SUSE® Observability Agenten.
Schließlich benötigt die rate() Funktion mindestens zwei Datenpunkte im Intervall, um überhaupt eine Rate zu berechnen. Mit weniger als zwei Datenpunkten wird die Rate keinen Wert haben. Daher ist ${__rate_interval} garantiert immer mindestens das 4-fache des Abfrageintervalls. Dies garantiert, dass es keine unerwarteten Lücken oder andere seltsame Verhaltensweisen in den Raten-Diagrammen gibt, es sei denn, Daten fehlen.
Es gibt einige ausgezeichnete Blogbeiträge im Internet, die dies ausführlicher erklären: