Erweiterte Fehlersuche
Wenn Sie ein Premiumkunde sind, wenden Sie sich an den SUSE Observability-Support unter https://scc.suse.com/, um Hilfe bei der Einrichtung von SUSE Observability in Ihrem lokalen Cluster zu erhalten. Verwenden Sie Support-Paket (Protokolle), um Informationen über Ihre Instanz für das Support-Team zu sammeln.
Diese Seite bietet detaillierte Informationen zu den Teilsystemen der SUSE Observability-Plattform, um Bereitstellungs- und Betriebsprobleme zu beheben. Diese Seite sollte nur konsultiert werden, wenn die Schritte in der Fehlerbehebung keine Lösung ergeben.
Allgemeiner Ansatz zur Fehlersuche
Der allgemeine Ansatz zur Fehlersuche bei Betriebsproblemen der SUSE Observability-Plattform ist folgender:
-
Verschaffen Sie sich einen Überblick darüber, wie sich die Pods über
kubectl get podsverhalten. -
Verwenden Sie die detaillierten Teilsysteminformationen in diesem Dokument zusammen mit den Symptomen des Problems, um zu bestimmen, welche Pods/Teilsysteme die Ursache sein könnten.
-
Überprüfen Sie die Protokolle/Metadaten der verdächtigen Pods über:
-
kubectl logs <pod-name> --all-containers=true -
kubectl describe pod <pod-name> -
Ein schneller Weg, um alle relevanten Protokolle/Beschreibungen zu SUSE Observability zu erhalten, ist über das Support-Paket (Protokolle).
-
-
Es könnte sein, dass die Protokolle auf eine fehlerhafte Abhängigkeit hinweisen; in diesem Fall untersuchen Sie die Abhängigkeit.
Überblick über Teilsysteme
Datenbanken
SUSE Observability wird von verschiedenen Datenbanken unterstützt; wenn eine Datenbank fehlerhaft ist, sollte dies zuerst untersucht werden, da alle anderen Dienste davon abhängen.
-
Zookeeper: Zookeeper wird für die Dienstentdeckung, Orchestrierung und Failover verwendet. Zookeeper wird mit 1 oder mehr Pods mit dem Namen bereitgestellt:-
suse-observability-zookeeper-<n>
-
-
Kafka: Kafka wird für die Nachrichtenübertragung zwischen fast allen Diensten verwendet: Kafka wird durch die folgenden Pods bereitgestellt:-
suse-observability-kafka-<n>: Haupt-Kafka-Bereitstellung -
<release-name>-kafkaup-operator-kafkaup-*: Hilfsoperator, der Kafka-Upgrades durchführt
-
-
StackGraph: StackGraph speichert (Benutzer-)Einstellungen und die Topologie. StackGraph besteht aus mehreren Komponenten und hat 2 Bereitstellungsmodi. HA und nonHA.-
Tephra: Verwaltet den Beginn, die Bestätigungen und Konflikte von Datenbanktransaktionen. Wird von Pod<release-name>-hbase-tephra-<n>bereitgestellt-
<release-name>-hbase-tephra-<n>: Tephra-Transaktionsserver-Pod. Verfolgt Transaktionen und Konflikte.
-
-
HBase-HA: Speichert die StackGraph-Daten, verteilt über mehrere Pods mit unterschiedlichen Verantwortlichkeiten:-
<release-name>-hbase-hdfs-nn-0: Name-Node für HDFS, verfolgt den Dateiindex -
<release-name>-hbase-hdfs-snn-0: Sekundärer Name-Node, führt Aufräumarbeiten nach dem Name-Node durch -
<release-name>-hbase-hdfs-dn-<n>: HDFS-Datenknoten, speichert die tatsächlichen Daten -
<release-name>-hbase-hbase-master-<n>: HBase-Master, koordiniert Tabellen und Regionen -
<release-name>-hbase-hbase-rs-<n>: HBase-Region-Server, bedient Tabellen und Regionen, speichert seine Daten auf HDFS
-
-
HBase-non-HA:-
<release-name>-hbase-stackgraph-0: Alle StackGraph-Komponenten werden als ein einzelner Pod imnon-HA-Setup bereitgestellt. Dies umfasst auch seine eigene Zookeeper-Instanz.
-
-
-
VictoriaMetrics: Speichert Metriken. Wird von den Pods bereitgestellt.-
suse-observability-victoria-metrics-<n>-0: Haupt-VictoriaMetrics-Datenspeicher/Abfrageknoten -
suse-observability-vmagent-0: Ingestionsagent für VictoriaMetrics. Daten werden an vmagent gesendet, bevor sie weitergeleitet und gespeichert werden.
-
-
ClickHouse: Speichert Trace-Daten. Bereitgestellt durch die folgenden Pods:-
suse-observability-clickhouse-shard0-<n>: Haupt-Clickhouse-Speicher
-
-
ElasticSearch: Speichert Ereignisse und Protokolle. Bereitgestellt durch die folgenden Pods:-
suse-observability-elasticsearch-master-<n>: Haupt-Elasticsearch-Speicher -
<release-name>-prometheus-elasticsearch-exporter-*: Exportiert Leistungsmetriken der Elasticsearch-Instanzen.
-
Ingestionsdienste
Die SUSE Observability-Plattform erhält Daten, die vom Agenten und dem OpenTelemetry (OTEL) Agenten gesendet werden. Die Ingestionsdienste führen die erste Verarbeitung durch und bringen die Daten zur Speicherung.
-
Receiver: Der Empfänger implementiert die API auf der Sammelseite für den SUSE Observability-Agenten. Er akzeptiert und autorisiert Telemetriedaten (Protokolle, Ereignisse, Kennzahlen oder Topologie) und leitet sie an den entsprechenden Datenspeicher oder Kafka weiter. Er kann im Einzel- oder Split-Modus bereitgestellt werden:-
Receiver-Split:-
<release-name>-suse-observability-receiver-logs-*: Empfängt Protokolle und legt sie in Elasticsearch ab. -
<release-name>-suse-observability-receiver-process-agent-*: Empfängt Informationen zur Prozess- und Netzwerkverbindung und leitet sie an Kafka-Themen weiter. -
<release-name>-suse-observability-receiver-base-*: Alle anderen Daten des SUSE Observability Agenten kommen hierher.
-
-
Receiver-NonSplit:-
<release-name>-suse-observability-receiver-*: Alle Daten des SUSE Observability Agenten kommen hierher.
-
-
-
OpenTelemetry Collector: Stellt einen Endpunkt bereit, an den OpenTelemetry-Agenten OpenTelemetry-Daten senden können, und erzeugt Traces, Kennzahlen und Topologie basierend auf den gesendeten Daten.-
suse-observability-otel-collector-0: Ein einzelner Pod, der den OTEL-Collector implementiert
-
Verarbeitung und Bereitstellung
Die SUSE Observability-Plattform führt Korrelation und Überwachung der empfangenen Telemetrie durch. Die Ergebnisse davon werden dem Kunden auf Anfrage über die API bereitgestellt. Die Kernelplattform kann im verteilten und nicht verteilten Modus betrieben werden. Der verteilte Modus ermöglicht eine höhere Durchsatzrate.
-
Correlator: Korreliert TCP-Verbindungsinformationen, um sie in eine Topologie umzuwandeln. Implementiert durch Pod:-
<release-name>-suse-observability-correlate-*
-
-
Events2Elasticsearch: Verarbeitet Ereignisse und speichert sie in Elasticsearch: Implementiert durch Pod:-
<release-name>-suse-observability-e2es-*
-
-
Anomaly Detection: Die SUSE Observability-Plattform führt eine Anomalieerkennung (standardmäßig deaktiviert) auf Metriken durch und erzeugt Gesundheitsverstöße:-
<release-name>-anomaly-detection-spotlight-manager-*: Verteilte Anomalieerkennung funktioniert -
<release-name>-anomaly-detection-spotlight-worker-*: Führt Anomalieerkennung auf Metrikdatenströmen durch.
-
-
Platform-Distributed: Die Plattform enthält die Hauptverarbeitungskomponenten und die API zur Bereitstellung. Im verteilten Modus werden funktionale Einheiten aufgeteilt. Die Pods, die zur Plattform gehören:-
<release-name>-suse-observability-api-*: Stellt alle Daten dem Benutzer zur Verfügung und verwaltet die Installation/Deinstallation von StackPacks. -
<release-name>-suse-observability-checks-*: Führt die Überwachungen aus -
<release-name>-suse-observability-health-sync-*: Verarbeitet Gesundheitsverstöße von den Monitoren und dem SUSE Observability-Agenten und fügt sie der Topologie hinzu. -
<release-name>-suse-observability-initializer-*: Koordiniert die Initialisierung der Datenspeicher und Migrationen -
<release-name>-suse-observability-notification-*: Leitet Benachrichtigungen basierend auf Gesundheitsverstöße und Benutzereinstellungen an Downstream-Systeme wie Slack/Opsgenie weiter. -
<release-name>-suse-observability-slicing-*: Optimiert kontinuierlich den Topologieverlauf für eine schnelle Abfrage. -
<release-name>-suse-observability-state-*: Verarbeitet Gesundheitsverstöße und fasst sie zur Komponenten-Gesundheit zusammen. -
<release-name>-suse-observability-sync-*: Verarbeitet Topologiedaten in Kombination mit Benutzereinstellungen und wandelt sie in das Topologiediagramm um.
-
-
Platform-Mono:-
<release-name>-suse-observability-server-*: Enthält alle Funktionen desPlatform-Distributed-Setups, jedoch in einem einzigen Pod.
-
Sonstige
-
Routing: Akzeptiert Verbindungen und leitet sie an den richtigen Backend-Service weiter:-
<release-name>-suse-observability-router-: Router basierend auf Envoy.
-
-
UI: React-basierte Benutzeroberfläche.-
<release-name>-suse-observability-ui: Dient nur dem statischen UI-Code und den Assets, alle dynamischen Verhaltensweisen werden vomapidurchgeführt.
-
-
Backup/Restore: Führt regelmäßig Jobs aus, um die verschiedenen Datenspeicher zu sichern. Hat einen kontinuierlich laufenden Pod:-
suse-observability-minio-*: Bietet eine abstrakte Schnittstelle zur Interaktion mit dem Backup-Speicher.
-
Beziehungen zwischen Teilsystemen.
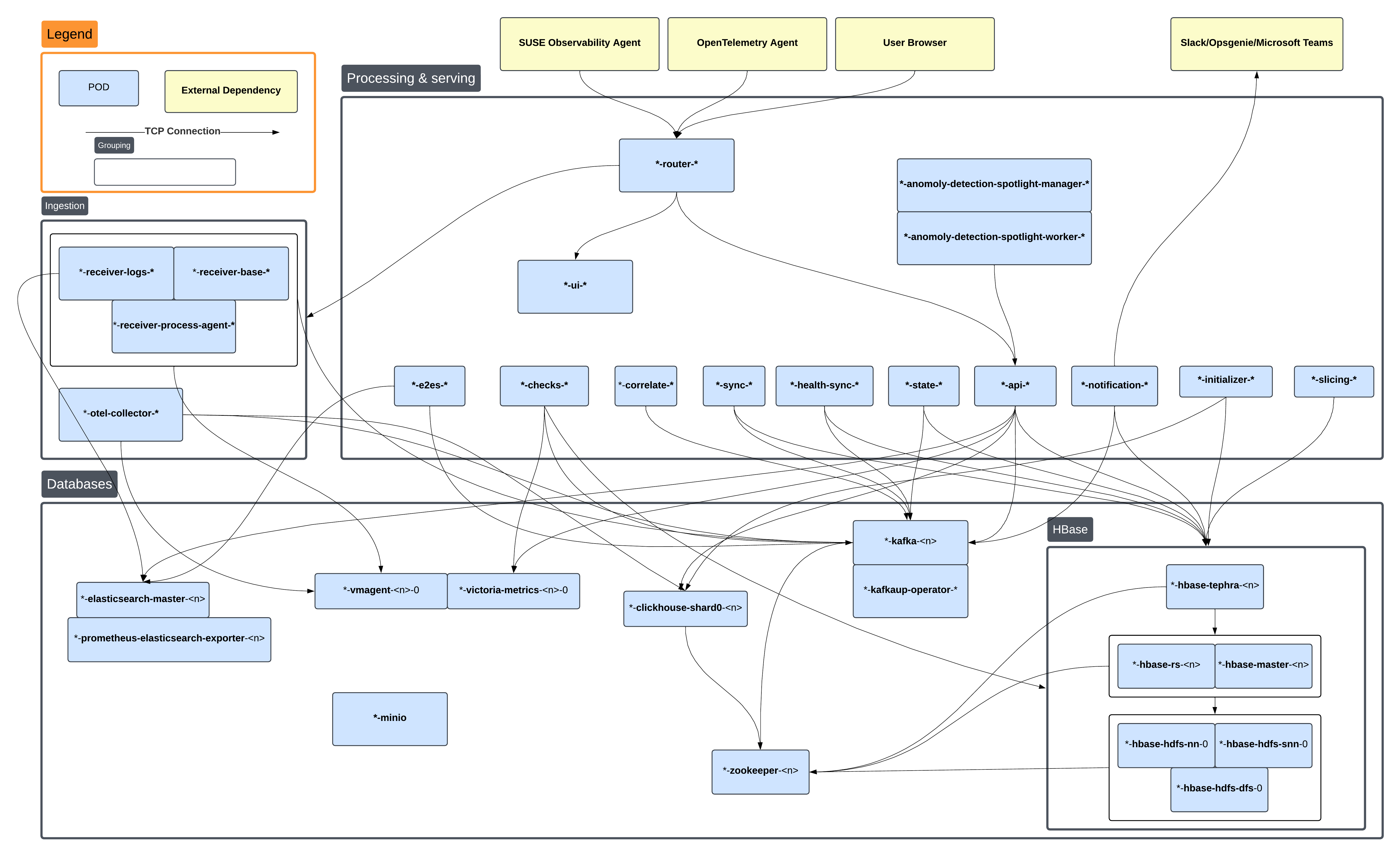
Um die Ursache eines Problems effektiv zu finden, ist es wichtig zu verstehen, welche Pods von anderen abhängen, wenn sie bereitgestellt werden. Das folgende Diagramm zeigt einen Überblick über die Pods mit TCP-Verbindungen, die zwischen ihnen bestehen können. Wenn man nach einer Ursache sucht, macht es Sinn, den Pod zu betrachten, der in dieser Abhängigkeitskette am 'niedrigsten' ist.
Die Pod-Namen in diesem Diagramm sind der Kürze halber abgekürzt.