|
この文書は自動機械翻訳技術を使用して翻訳されています。 正確な翻訳を提供するように努めておりますが、翻訳された内容の完全性、正確性、信頼性については一切保証いたしません。 相違がある場合は、元の英語版 英語 が優先され、正式なテキストとなります。 |
代表的なチャート用のPromQLクエリ作成
ガイドライン
SUSE® Observabilityがチャートにデータを表示する際には、ほぼ常に保存されたデータの解像度を変更して、チャートの利用可能なスペースに収める必要があります。できるだけ代表的なチャートを得るためには、以下のガイドラインに従ってください。
-
生のメトリックをクエリするのではなく、常に時間で集約してください(`*_over_time`または`rate`関数を使用)。
-
時間での集約の範囲として`${__interval}`パラメータを使用してください。これはチャートの解像度に応じて自動的に調整されます。
-
rate`集約の範囲として${__rate_interval}`パラメータを使用してください。これもチャートの解像度に応じて自動的に調整されますが、`rate`の特定の動作を考慮に入れます。 -
異なる時間系列を集約し、使用されるラベルのみを抽出する形でメトリックを投影します。
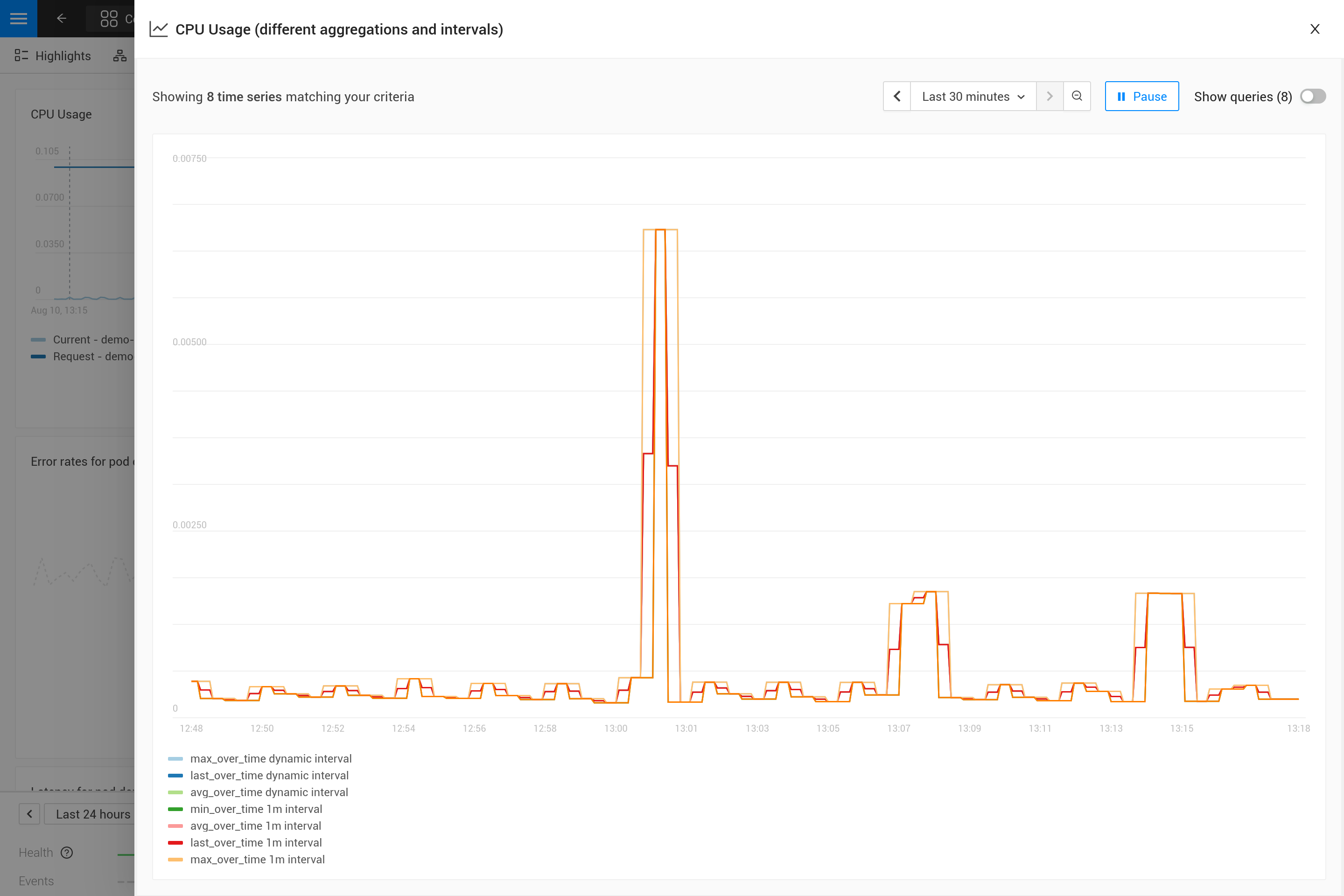
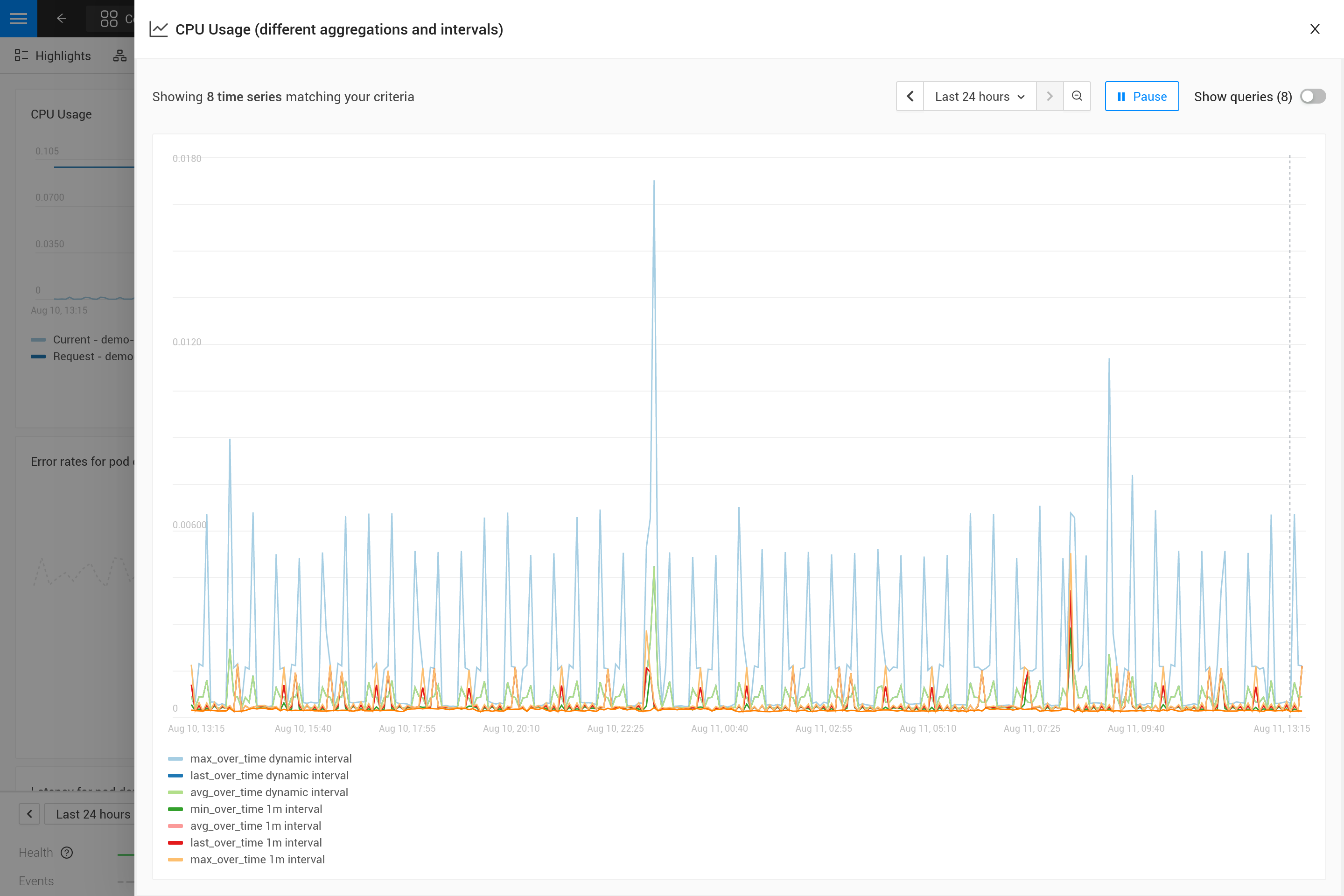
集約を適用することは、メトリックの特定のパターンを他のパターンよりも強調するためにトレードオフが行われることを意味します。例えば、大きな時間ウィンドウでは`max_over_time`がすべてのピークを表示しますが、すべての谷は表示しません。一方、`min_over_time`は正反対のことを行い、`avg_over_time`はピークと谷の両方を滑らかにします。この動作を示すために、ポッドのCPU使用率を使用したメトリックバインディングの例を示します。自分で試すには、これをYAMLファイルにコピーし、CLIを使用して自分のSUSE® Observabilityに適用してください(後で削除することもできます)。
複数の時間系列をそのラベルのサブセットに投影することは、無関係な詳細が異なる時間系列をまとめることを意味します。 メトリックバインディングを作成する際には、凡例で使用されるラベルのみが関連します。 同様に、モニターを作成する際には、コンポーネントの(モニターステータスに)マッピングに必要なラベルのみがクエリによって返されるべきです。
- _type: MetricBinding
chartType: line
enabled: true
tags: {}
unit: short
name: CPU Usage (different aggregations and intervals)
priority: HIGH
identifier: urn:stackpack:my-stackpack:metric-binding:pod-cpu-usage-a
queries:
- expression: sum(max_over_time(container_cpu_usage{cluster_name="${tags.cluster-name}", namespace="${tags.namespace}", pod_name="${name}"}[${__interval}])) by (cluster_name, namespace, pod_name) /1000000000
alias: max_over_time dynamic interval
- expression: sum(min_over_time(container_cpu_usage{cluster_name="${tags.cluster-name}", namespace="${tags.namespace}", pod_name="${name}"}[${__interval}])) by (cluster_name, namespace, pod_name) /1000000000
alias: min_over_time dynamic interval
- expression: sum(avg_over_time(container_cpu_usage{cluster_name="${tags.cluster-name}", namespace="${tags.namespace}", pod_name="${name}"}[${__interval}])) by (cluster_name, namespace, pod_name) /1000000000
alias: avg_over_time dynamic interval
- expression: sum(last_over_time(container_cpu_usage{cluster_name="${tags.cluster-name}", namespace="${tags.namespace}", pod_name="${name}"}[${__interval}])) by (cluster_name, namespace, pod_name) /1000000000
alias: last_over_time dynamic interval
- expression: sum(max_over_time(container_cpu_usage{cluster_name="${tags.cluster-name}", namespace="${tags.namespace}", pod_name="${name}"}[1m])) by (cluster_name, namespace, pod_name) /1000000000
alias: max_over_time 1m interval
- expression: sum(min_over_time(container_cpu_usage{cluster_name="${tags.cluster-name}", namespace="${tags.namespace}", pod_name="${name}"}[1m])) by (cluster_name, namespace, pod_name) /1000000000
alias: min_over_time 1m interval
- expression: sum(avg_over_time(container_cpu_usage{cluster_name="${tags.cluster-name}", namespace="${tags.namespace}", pod_name="${name}"}[1m])) by (cluster_name, namespace, pod_name) /1000000000
alias: avg_over_time 1m interval
- expression: sum(last_over_time(container_cpu_usage{cluster_name="${tags.cluster-name}", namespace="${tags.namespace}", pod_name="${name}"}[1m])) by (cluster_name, namespace, pod_name) /1000000000
alias: last_over_time 1m interval
scope: (label = "stackpack:kubernetes" and type = "pod")
適用後、SUSE® Observability内のポッドのメトリクス表示を開いてください(できれば、CPU使用率にスパイクと谷が見られるポッドを使用してください)。右上隅のアイコンを使用してチャートを拡大すると、より見やすくなります。今、異なる集約の影響を確認するために時間ウィンドウを変更することもできます(例えば、30分と24時間の場合)。
|
メトリックバインディングで集約が指定されていない場合、SUSE® Observabilityはチャートのデータポイント数を減らすために自動的に`last_over_time`による集約を使用します。説明については、なぜ集約が必要なのか?も参照してください。 |
なぜ集約が必要なのか?
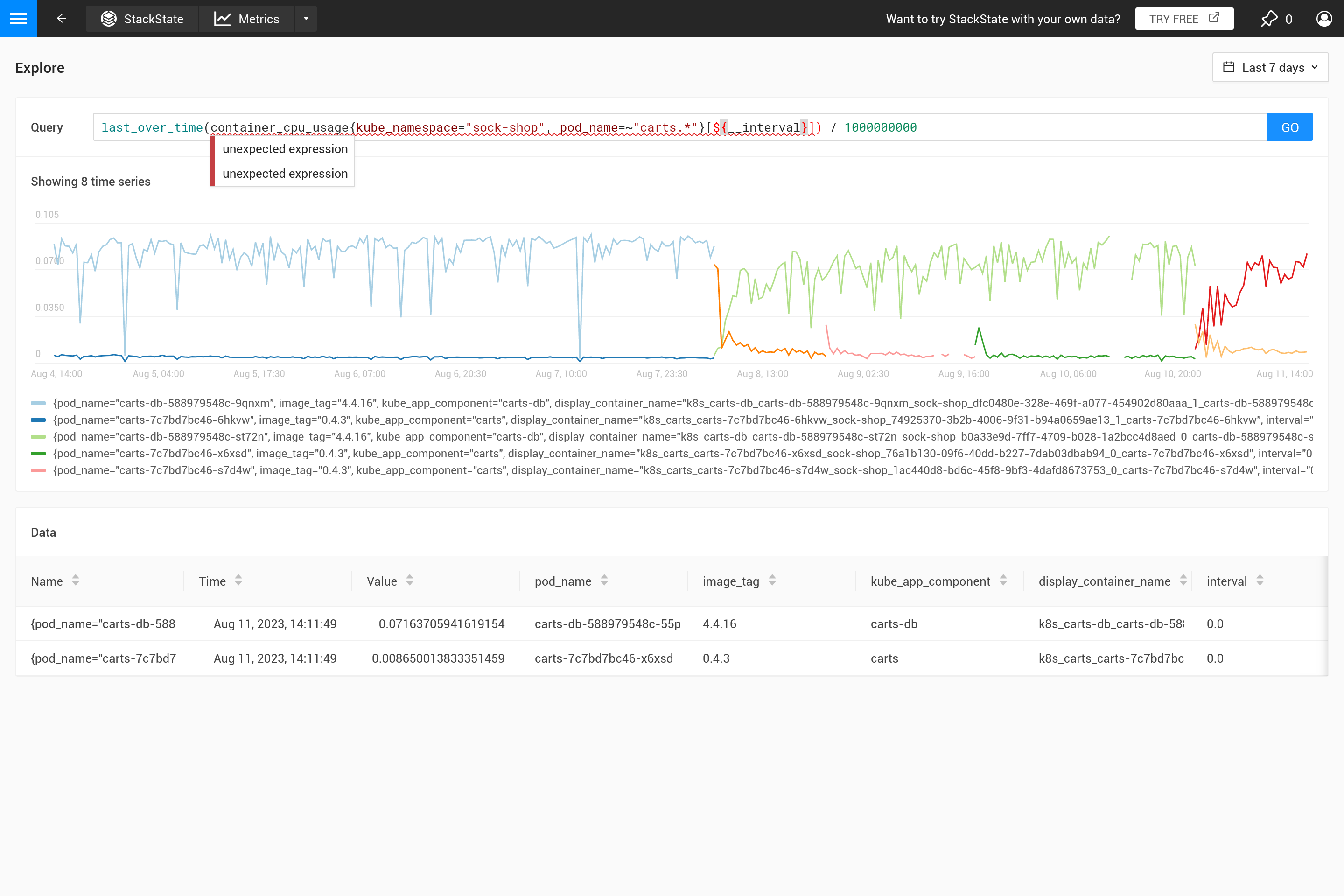
まず第一に、なぜ集約を使用する必要があるのですか?メトリックストアからチャートに収まる以上のデータポイントを取得することは意味がありません。したがって、SUSE® Observabilityは良好な結果を得るために2つのデータポイント間の必要なステップを自動的に決定します。短い時間ウィンドウ(例えば、1時間のデータのみを表示するチャート)の場合、これは小さなステップ(約10秒)になります。メトリックは通常30秒ごとにのみ収集されるため、10秒のステップでは、次の値に変わる前に同じ値が3ステップ繰り返されます。1週間の時間ウィンドウにズームアウトすると、はるかに大きなステップ(約1時間、画面上のチャートの正確なサイズに依存)を必要とします。
ステップが収集されたデータポイントの解像度よりも大きくなると、1時間の時間範囲のデータポイントを単一の値に要約する方法を決定する必要があります。クエリにすでに時間に対する集約が指定されている場合、それが使用されます。ただし、集約が指定されていない場合、または集約間隔がステップよりも小さい場合は、`last_over_time`集約が使用され、`step`サイズが間隔として使用されます。その結果、各時間の最後のデータポイントのみが、その時間内のすべてのデータポイントを「要約」するために使用されます。
要約すると、1週間の時間範囲で1時間のステップのPromQLクエリを実行すると、このクエリ:
container_cpu_usage /1000000000
は自動的に次のように変換されます:
last_over_time(container_cpu_usage[1h]) /1000000000
SUSE® Observabilityプレイグラウンドで自分で試してみてください。
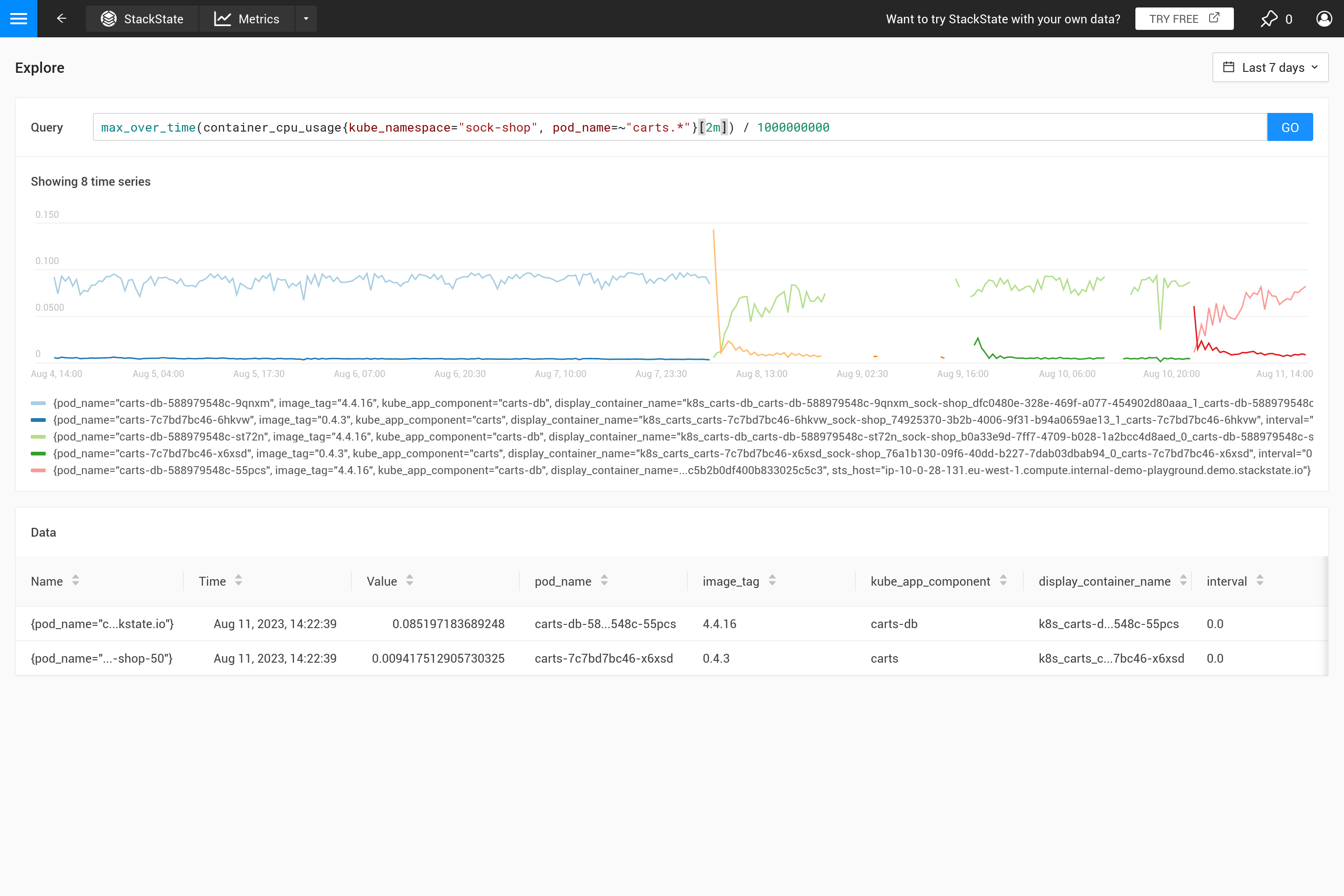
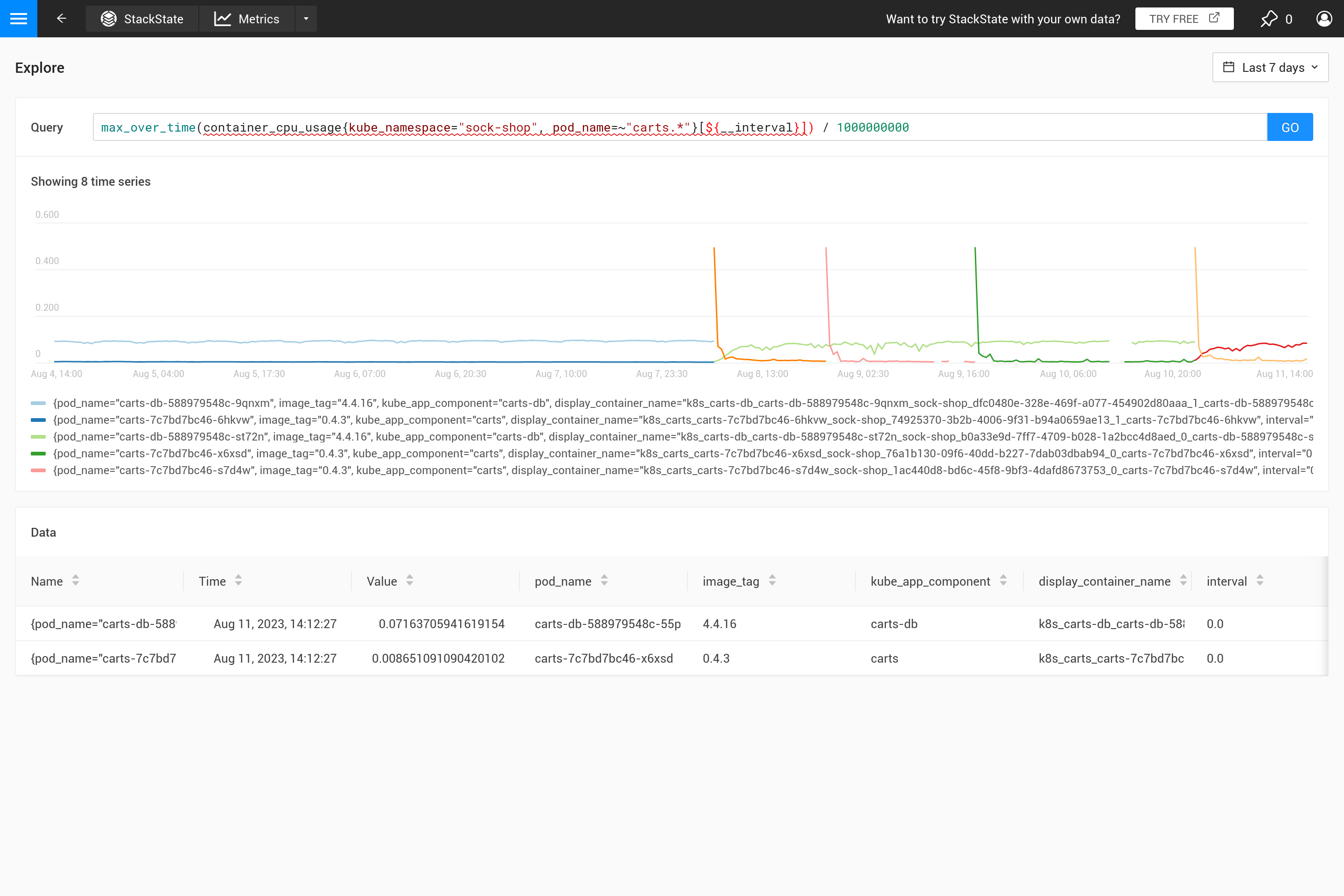
この動作はしばしば意図されていないものであり、どのような集約が必要かを自分で決定する方が良いです。異なる集約関数を使用することで、特定の動作を強調することが可能ですが、その代わりに他の動作が隠れてしまう場合があります。ピーク、谷、滑らかなチャートなどを見ることがより重要ですか?その場合、クエリに使用される`step`サイズで自動的に置き換えられるため、範囲の`${__interval}`パラメータを使用してください。その結果、ステップ内のすべてのデータポイントが使用されます。
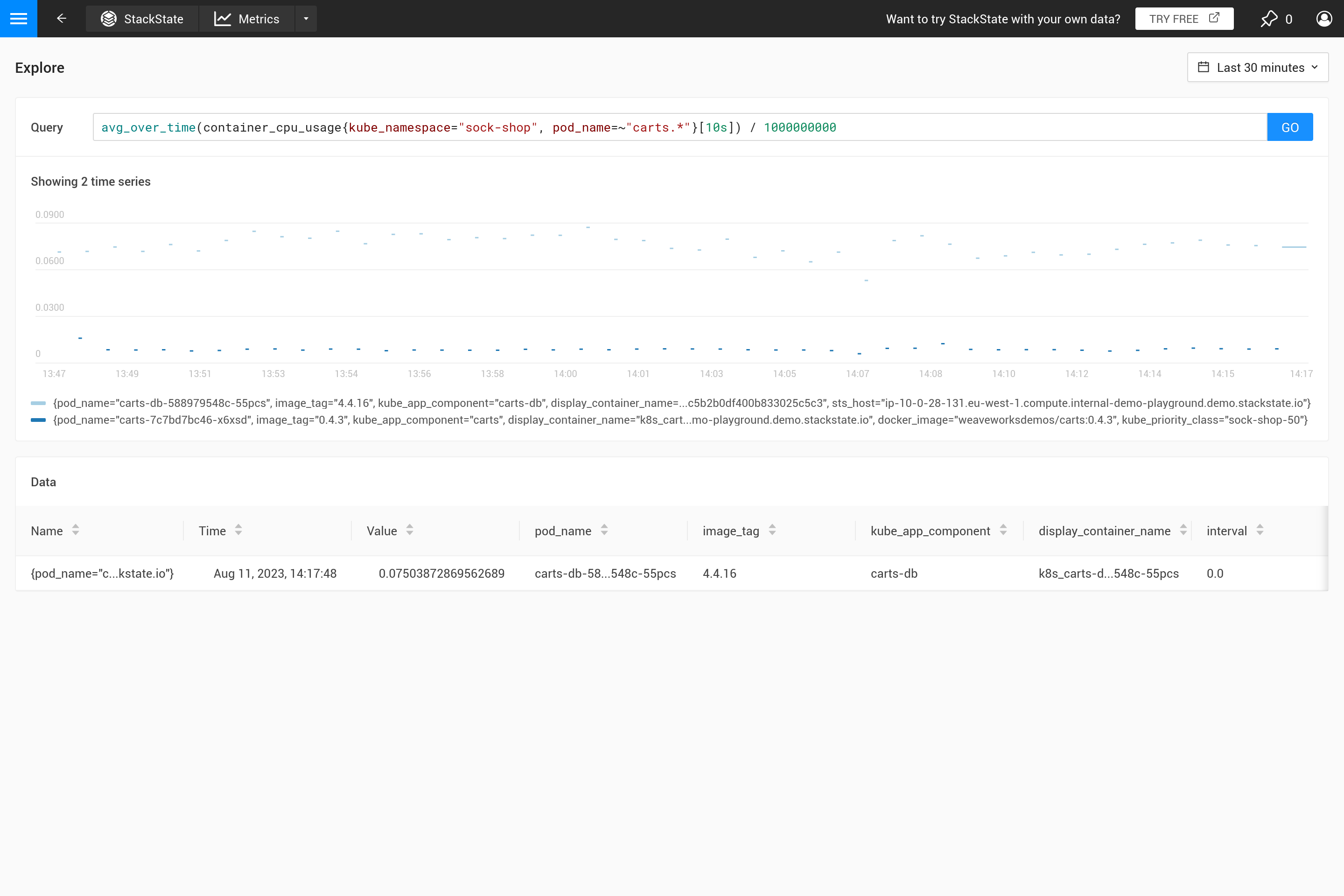
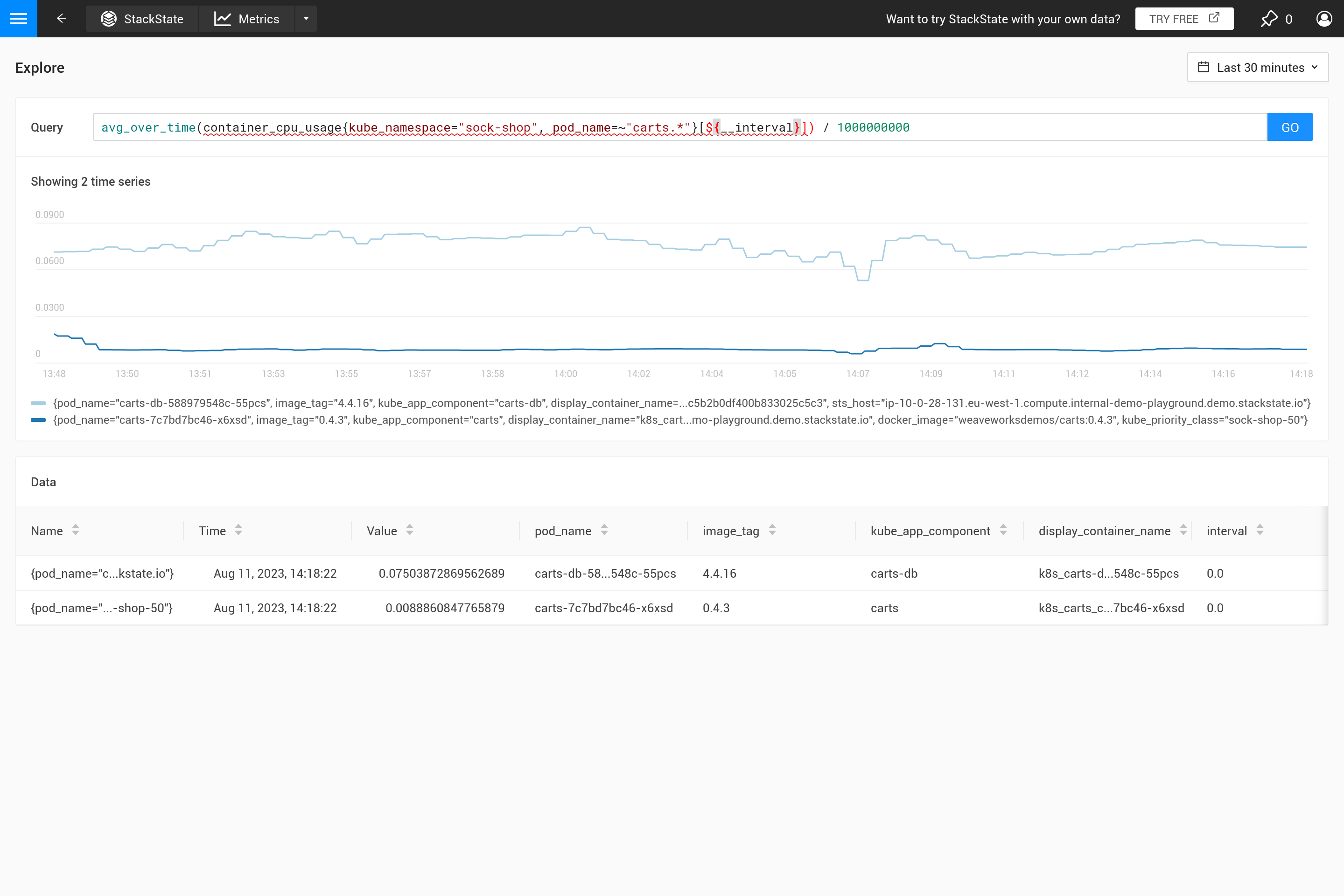
${interval}`パラメータは別の問題を防ぎます。`step`のサイズが縮小し、${interval}`保存されたメトリックデータの解像度よりも小さくなると、チャートにギャップが生じます。
したがって、`${__interval}`はSUSE® Observabilityエージェントのデフォルトのスクレイプ間隔(デフォルトのスクレイプ間隔は30秒)の2倍よりも小さくなることはありません。
最後に、rate()`関数は、レートを計算するために、少なくとも2つのデータポイントがその間隔に存在する必要があります。2つ未満のデータポイントでは、レートの値は計算できません。したがって、${__rate_interval}`は常にスクレイプ間隔の4倍以上であることが保証されています。これにより、データが欠落していない限り、レートチャートに予期しないギャップやその他の奇妙な動作が発生しないことが保証されます。
このことをより詳しく説明している優れたブログ記事がインターネット上にいくつかあります: