|
Dieses Dokument wurde mithilfe automatisierter maschineller Übersetzungstechnologie übersetzt. Wir bemühen uns um korrekte Übersetzungen, übernehmen jedoch keine Gewähr für die Vollständigkeit, Richtigkeit oder Zuverlässigkeit der übersetzten Inhalte. Im Falle von Abweichungen ist die englische Originalversion maßgebend und stellt den verbindlichen Text dar. |
Virtuelle Maschinenprobleme
Die folgenden Abschnitte enthalten Informationen, die bei der Fehlersuche zu SUSE Virtualization VM-Verwaltung hilfreich sind.
VM-Startschaltfläche ist nicht sichtbar
Problembeschreibung
In seltenen Fällen ist die Schaltfläche "Start" in der SUSE Virtualization Benutzeroberfläche für VMs, die Aus sind, nicht verfügbar. Ohne diese Schaltfläche können die Benutzer die VMs nicht starten.
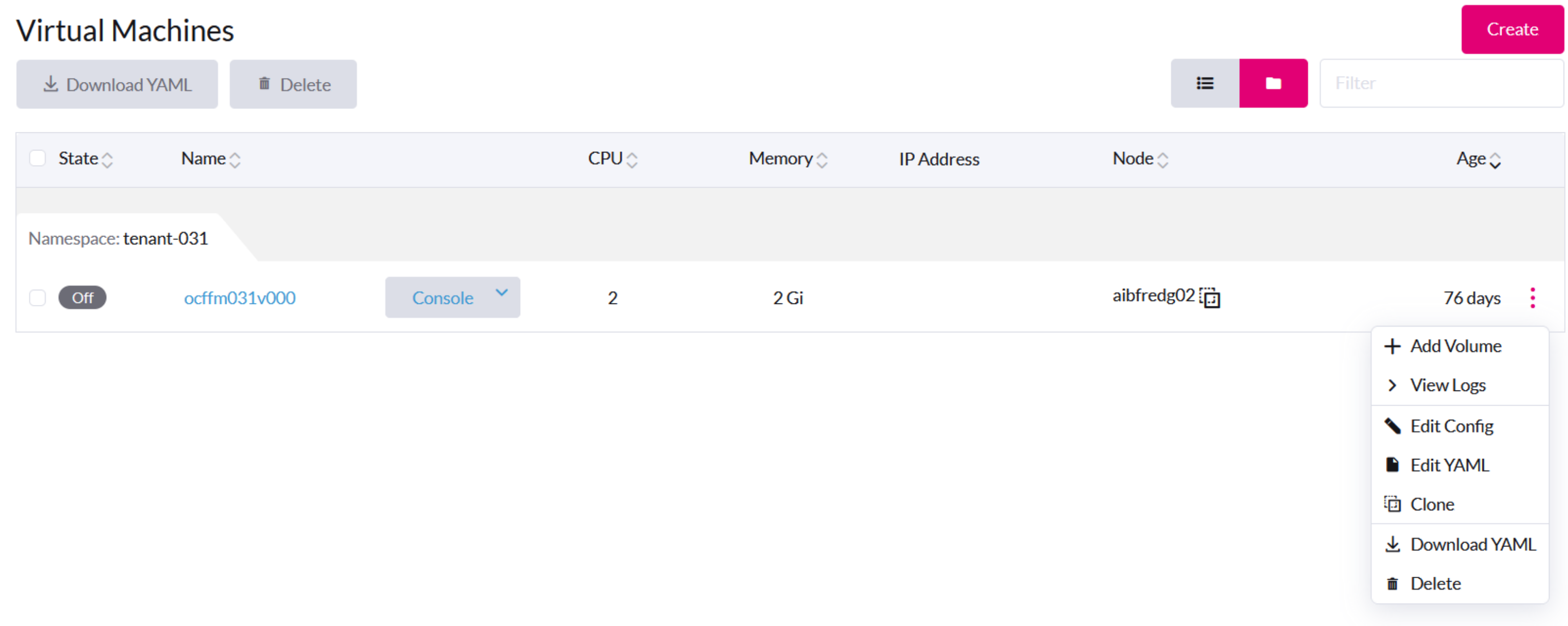
Allgemeine VM-Operationen
In der SUSE Virtualization Benutzeroberfläche ist die Schaltfläche "Stop" sichtbar, nachdem eine VM erstellt und gestartet wurde.
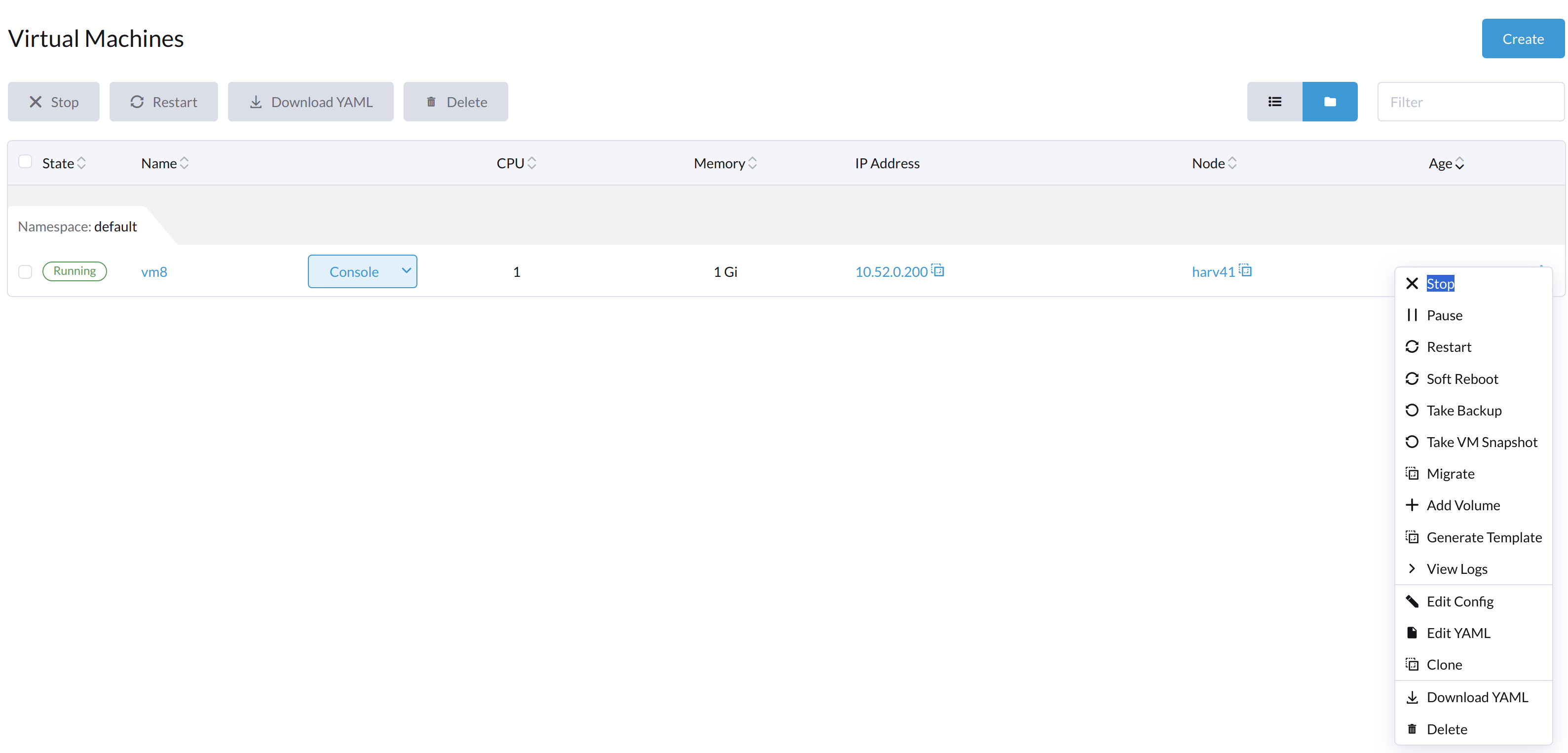
Die Schaltfläche "Start" ist sichtbar, nachdem die VM gestoppt wurde.
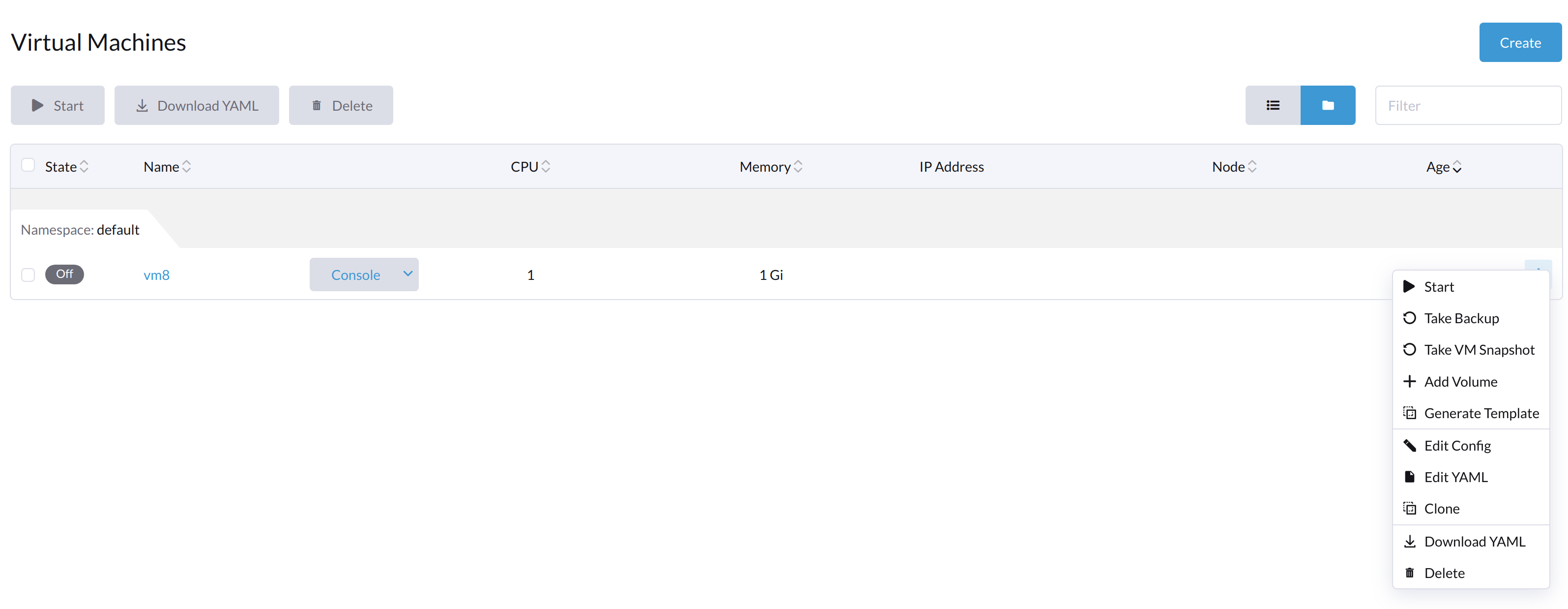
Wenn die VM von innerhalb der VM heruntergefahren wird, sind sowohl die Schaltfläche "Start" als auch die Schaltfläche "Neustart" sichtbar.
Allgemeine VM-bezogene Objekte
Eine laufende VM
Die Objekte vm, vmi und pod, die alle mit der VM verbunden sind, existieren. Der Status aller drei Objekte ist Running.
# kubectl get vm NAME AGE STATUS READY vm8 7m25s Running True # kubectl get vmi NAME AGE PHASE IP NODENAME READY vm8 78s Running 10.52.0.199 harv41 True # kubectl get pod NAME READY STATUS RESTARTS AGE virt-launcher-vm8-tl46h 1/1 Running 0 80s
Eine VM, die über die SUSE Virtualization Benutzeroberfläche gestoppt wurde
Nur das Objekt vm existiert und sein Status ist Stopped. Sowohl vmi als auch pod verschwinden.
# kubectl get vm NAME AGE STATUS READY vm8 123m Stopped False # kubectl get vmi No resources found in default namespace. # kubectl get pod No resources found in default namespace. #
Eine VM, die mit dem Poweroff-Befehl der VM gestoppt wurde
Die Objekte vm, vmi und pod, die alle mit der VM verbunden sind, existieren. Der Status von vm ist Stopped, während der Status von pod Completed ist.
# kubectl get vm NAME AGE STATUS READY vm8 134m Stopped False # kubectl get vmi NAME AGE PHASE IP NODENAME READY vm8 2m49s Succeeded 10.52.0.199 harv41 False # kubectl get pod NAME READY STATUS RESTARTS AGE virt-launcher-vm8-tl46h 0/1 Completed 0 2m54s
Problemanalyse
Wenn das Problem auftritt, existieren die Objekte vm, vmi und pod. Der Status der Objekte ist ähnlich dem von A VM wurde mit dem Poweroff-Befehl der VM gestoppt.
Beispiel:
Die VM ocffm031v000 ist nicht bereit (status: "False"), da der virt-launcher-Pod beendet wird (reason: "PodTerminating").
- apiVersion: kubevirt.io/v1
kind: VirtualMachine
...
status:
conditions:
- lastProbeTime: "2023-07-20T08:37:37Z"
lastTransitionTime: "2023-07-20T08:37:37Z"
message: virt-launcher pod is terminating
reason: PodTerminating
status: "False"
type: Ready
Ähnlich ist die VMI (virtuelle Maschineninstanz) ocffm031v000 nicht bereit (status: "False"), da der virt-launcher-Pod beendet wird (reason: "PodTerminating").
- apiVersion: kubevirt.io/v1
kind: VirtualMachineInstance
...
name: ocffm031v000
...
status:
activePods:
ec36a1eb-84a5-4421-b57b-2c14c1975018: aibfredg02
conditions:
- lastProbeTime: "2023-07-20T08:37:37Z"
lastTransitionTime: "2023-07-20T08:37:37Z"
message: virt-launcher pod is terminating
reason: PodTerminating
status: "False"
type: Ready
Andererseits ist der Pod virt-launcher-ocffm031v000-rrkss nicht bereit (status: "False"), da der Pod abgeschlossen ist (reason: "PodCompleted").
Der zugrunde liegende Container 0d7a0f64f91438cb78f026853e6bebf502df1bdeb64878d351fa5756edc98deb ist beendet, und die exitCode ist 0.
- apiVersion: v1
kind: Pod
...
name: virt-launcher-ocffm031v000-rrkss
...
ownerReferences:
- apiVersion: kubevirt.io/v1
...
kind: VirtualMachineInstance
name: ocffm031v000
uid: 8d2cf524-7e73-4713-86f7-89e7399f25db
uid: ec36a1eb-84a5-4421-b57b-2c14c1975018
...
status:
conditions:
- lastProbeTime: "2023-07-18T13:48:56Z"
lastTransitionTime: "2023-07-18T13:48:56Z"
message: the virtual machine is not paused
reason: NotPaused
status: "True"
type: kubevirt.io/virtual-machine-unpaused
- lastProbeTime: "null"
lastTransitionTime: "2023-07-18T13:48:55Z"
reason: PodCompleted
status: "True"
type: Initialized
- lastProbeTime: "null"
lastTransitionTime: "2023-07-20T08:38:56Z"
reason: PodCompleted
status: "False"
type: Ready
- lastProbeTime: "null"
lastTransitionTime: "2023-07-20T08:38:56Z"
reason: PodCompleted
status: "False"
type: ContainersReady
...
containerStatuses:
- containerID: containerd://0d7a0f64f91438cb78f026853e6bebf502df1bdeb64878d351fa5756edc98deb
image: registry.suse.com/suse/sles/15.4/virt-launcher:0.54.0-150400.3.3.2
imageID: sha256:43bb08efdabb90913534b70ec7868a2126fc128887fb5c3c1b505ee6644453a2
lastState: {}
name: compute
ready: false
restartCount: 0
started: false
state:
terminated:
containerID: containerd://0d7a0f64f91438cb78f026853e6bebf502df1bdeb64878d351fa5756edc98deb
exitCode: 0
finishedAt: "2023-07-20T08:38:55Z"
reason: Completed
startedAt: "2023-07-18T13:50:17Z"
Ein kritischer Unterschied ist, dass die Aktionen Stop und Start in der stateChangeRequests-Eigenschaft von vm erscheinen.
status:
conditions:
...
printableStatus: Stopped
stateChangeRequests:
- action: Stop
uid: 8d2cf524-7e73-4713-86f7-89e7399f25db
- action: Start
Hauptursache
Die Hauptursache dieses Problems wird untersucht.
Es ist bemerkenswert, dass der Quellcode den Status von vm überprüft und annimmt, dass das Objekt gestartet wird. Keine Start und Restart Operationen werden dem Objekt hinzugefügt.
func (vf *vmformatter) canStart(vm *kubevirtv1.VirtualMachine, vmi *kubevirtv1.VirtualMachineInstance) bool {
if vf.isVMStarting(vm) {
return false
}
..
}
func (vf *vmformatter) canRestart(vm *kubevirtv1.VirtualMachine, vmi *kubevirtv1.VirtualMachineInstance) bool {
if vf.isVMStarting(vm) {
return false
}
...
}
func (vf *vmformatter) isVMStarting(vm *kubevirtv1.VirtualMachine) bool {
for _, req := range vm.Status.StateChangeRequests {
if req.Action == kubevirtv1.StartRequest {
return true
}
}
return false
}
Umgehung des Problems
Um das Problem zu beheben, können Sie den Pod mit dem Befehl kubectl delete pod virt-launcher-ocffm031v000-rrkss -n namespace --force zwangsweise löschen.
Nachdem der Pod erfolgreich gelöscht wurde, wird die Schaltfläche Start wieder auf der SUSE Virtualization Benutzeroberfläche sichtbar.
VM bleibt im Startzustand mit Fehlermeldung not a device node
Betroffene Versionen: v1.3.0
Problembeschreibung
Einige VMs können möglicherweise nicht starten und reagieren dann nicht mehr, nachdem der Cluster oder einige Knoten neu gestartet wurden. Auf dem Dashboard-Bildschirm der SUSE Virtualization-Benutzeroberfläche bleibt der Status der betroffenen VMs bei Starten hängen.
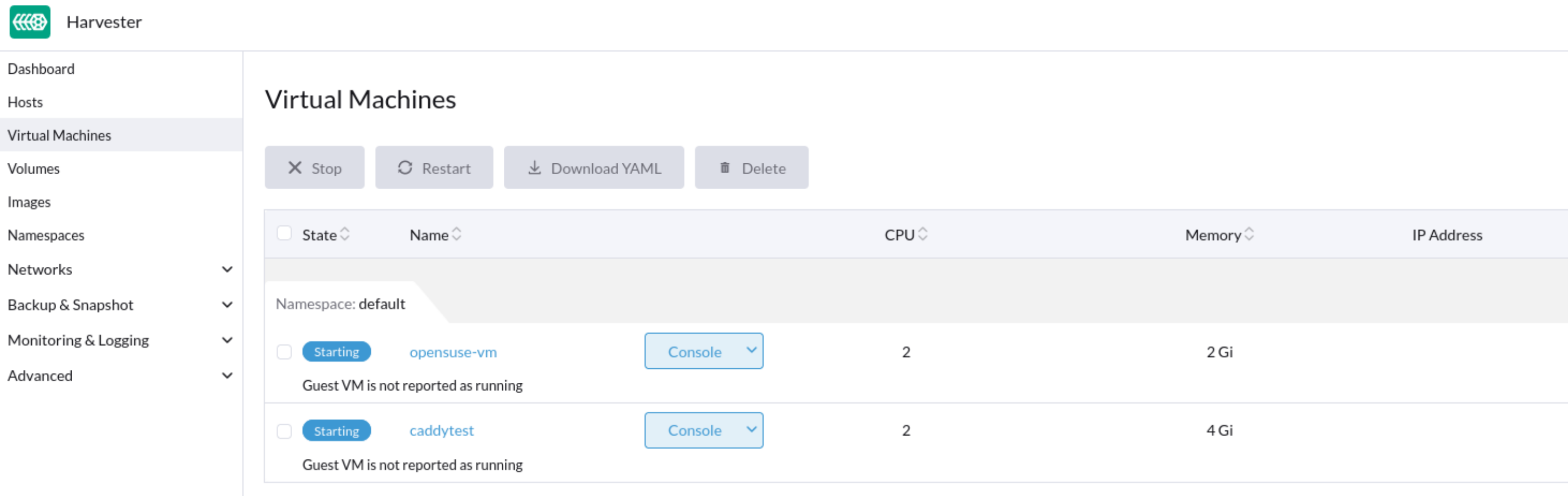
Problemanalyse
Der Status des Pods, der mit der betroffenen VM verbunden ist, ist CreateContainerError.
$ kubectl get pods NAME READY STATUS RESTARTS AGE virt-launcher-vm1-w9bqs 0/2 CreateContainerError 0 9m39s
Der Ausdruck failed to generate spec: not a device node ist in den folgenden zu finden:
$kubectl get pods -oyaml
apiVersion: v1
items:
apiVersion: v1
kind: Pod
metadata:
...
containerStatuses:
- image: registry.suse.com/suse/sles/15.5/virt-launcher:1.1.0-150500.8.6.1
imageID: ""
lastState: {}
name: compute
ready: false
restartCount: 0
started: false
state:
waiting:
message: 'failed to generate container "50f0ec402f6e266870eafb06611850a5a03b2a0a86fdd6e562959719ccc003b5"
spec: failed to generate spec: not a device node'
reason: CreateContainerError
kubelet.log Datei:
file path: /var/lib/rancher/rke2/agent/logs/kubelet.log E0205 20:44:31.683371 2837 pod_workers.go:1294] "Error syncing pod, skipping" err="failed to \"StartContainer\" for \"compute\" with CreateContainerError: \"failed t o generate container \\\"255d42ec2e01d45b4e2480d538ecc21865cf461dc7056bc159a80ee68c411349\\\" spec: failed to generate spec: not a device node\"" pod="default/virt-laun cher-caddytest-9tjzj" podUID=d512bf3e-f215-4128-960a-0658f7e63c7c
containerd.log Datei:
file path: /var/lib/rancher/rke2/agent/containerd/containerd.log
time="2024-02-21T11:24:00.140298800Z" level=error msg="CreateContainer within sandbox \"850958f388e63f14a683380b3c52e57db35f21c059c0d93666f4fdaafe337e56\" for &ContainerMetadata{Name:compute,Attempt:0,} failed" error="failed to generate container \"5ddad240be2731d5ea5210565729cca20e20694e364e72ba14b58127e231bc79\" spec: failed to generate spec: not a device node"
Nachdem Debug-Informationen zu containerd hinzugefügt wurden, identifiziert es die Fehlermeldung not a device node, die sich auf die Datei pvc-3c1b28fb-* bezieht.
time="2024-02-22T15:15:08.557487376Z" level=error msg="CreateContainer within sandbox \"d23af3219cb27228623cf8168ec27e64e836ed44f2b2f9cf784f0529a7f92e1e\" for &ContainerMetadata{Name:compute,Attempt:0,} failed" error="failed to generate container \"e4ed94fb5e9145e8716bcb87aae448300799f345197d52a617918d634d9ca3e1\" spec: failed to generate spec: get device path: /var/lib/kubelet/plugins/kubernetes.io/csi/volumeDevices/publish/pvc-3c1b28fb-683e-4bf5-9869-c9107a0f1732/20291c6b-62c3-4456-be8a-fbeac118ec19 containerPath: /dev/disk-0 error: not a device node"
Dies ist eine mit CSI verbundene Datei, aber es handelt sich um eine leere Datei anstelle der erwarteten Geräte-Datei. Dann hat der containerd die CreateContainer Anfrage abgelehnt.
$ ls /var/lib/kubelet/plugins/kubernetes.io/csi/volumeDevices/publish/pvc-3c1b28fb-683e-4bf5-9869-c9107a0f1732/ -alth
total 8.0K
drwxr-x--- 2 root root 4.0K Feb 22 15:10 .
-rw-r--r-- 1 root root 0 Feb 22 14:28 aa851da3-cee1-45be-a585-26ae766c16ca
-rw-r--r-- 1 root root 0 Feb 22 14:07 20291c6b-62c3-4456-be8a-fbeac118ec19
drwxr-x--- 4 root root 4.0K Feb 22 14:06 ..
-rw-r--r-- 1 root root 0 Feb 21 15:48 4333c9fd-c2c8-4da2-9b5a-1a310f80d9fd
-rw-r--r-- 1 root root 0 Feb 21 09:18 becc0687-b6f5-433e-bfb7-756b00deb61b
$file /var/lib/kubelet/plugins/kubernetes.io/csi/volumeDevices/publish/pvc-3c1b28fb-683e-4bf5-9869-c9107a0f1732/20291c6b-62c3-4456-be8a-fbeac118ec19
: emptyDie oben aufgeführte Ausgabe steht im direkten Gegensatz zu dem folgenden Beispiel, das die erwartete Geräte-Datei einer laufenden VM zeigt.
$ ls /var/lib/kubelet/plugins/kubernetes.io/csi/volumeDevices/publish/pvc-732f8496-103b-4a08-83af-8325e1c314b7/ -alth total 8.0K drwxr-x--- 2 root root 4.0K Feb 21 10:53 . drwxr-x--- 4 root root 4.0K Feb 21 10:53 .. brw-rw---- 1 root root 8, 16 Feb 21 10:53 4883af80-c202-4529-a2c6-4e7f15fe5a9b
Hauptursache
Nachdem der Cluster oder bestimmte Knoten neu gestartet wurden, ruft der kubelet NodePublishVolume für das neue Pod auf, ohne zuerst NodeStageVolume aufzurufen. Darüber hinaus bindet das Longhorn CSI-Plugin die reguläre Datei am Staging-Zielpfad (früher vom gelöschten Pod verwendet) an den Zielpfad, und der Vorgang wird als erfolgreich betrachtet.
Umgehung des Problems
Cluster-Ebene Operation:
-
Finden Sie die unterstützenden Pods der betroffenen VMs und die zugehörigen Longhorn-Volumes.
$ kubectl get pods NAME READY STATUS RESTARTS AGE virt-launcher-vm1-nxfm4 0/2 CreateContainerError 0 7m11s $ kubectl get pvc -A NAMESPACE NAME STATUS VOLUME CAPACITY ACCESS MODES STORAGECLASS AGE default vm1-disk-0-9gc6h Bound pvc-f1798969-5b72-4d76-9f0e-64854af7b59c 1Gi RWX longhorn-image-fxsqr 7d22h
-
Stop die betroffenen VMs über die SUSE Virtualization Benutzeroberfläche.
Die VM könnte in
Stoppinghängen bleiben, fahren Sie mit dem nächsten Schritt fort. -
Löschen Sie die unterstützenden Pods zwangsweise.
$ kubectl delete pod virt-launcher-vm1-nxfm4 --force Warning: Immediate deletion does not wait for confirmation that the running resource has been terminated. The resource may continue to run on the cluster indefinitely. pod "virt-launcher-vm1-nxfm4" force deleted
Die VM ist jetzt ausgeschaltet.
Knoten-Ebene Operation, Knoten für Knoten:
-
Cordon einen Knoten.
-
Hängen Sie alle betroffenen Longhorn-Volumes in diesem Knoten aus.
Sie müssen sich per SSH zu diesem Knoten verbinden und den
sudo -i umount pathBefehl ausführen.$ umount /var/lib/kubelet/plugins/kubernetes.io/csi/volumeDevices/pvc-f1798969-5b72-4d76-9f0e-64854af7b59c/dev/* umount: /var/lib/kubelet/plugins/kubernetes.io/csi/volumeDevices/pvc-f1798969-5b72-4d76-9f0e-64854af7b59c/dev/4b2ab666-27bd-4e3c-a218-fb3d48a72e69: not mounted. umount: /var/lib/kubelet/plugins/kubernetes.io/csi/volumeDevices/pvc-f1798969-5b72-4d76-9f0e-64854af7b59c/dev/6aaf2bbe-f688-4dcd-855a-f9e2afa18862: not mounted. umount: /var/lib/kubelet/plugins/kubernetes.io/csi/volumeDevices/pvc-f1798969-5b72-4d76-9f0e-64854af7b59c/dev/91488f09-ff22-45f4-afc0-ca97f67555e7: not mounted. umount: /var/lib/kubelet/plugins/kubernetes.io/csi/volumeDevices/pvc-f1798969-5b72-4d76-9f0e-64854af7b59c/dev/bb4d0a15-737d-41c0-946c-85f4a56f072f: not mounted. umount: /var/lib/kubelet/plugins/kubernetes.io/csi/volumeDevices/pvc-f1798969-5b72-4d76-9f0e-64854af7b59c/dev/d2a54e32-4edc-4ad8-a748-f7ef7a2cacab: not mounted.
-
Uncordon diesen Knoten.
-
Start die betroffenen VMs über die Harvester Benutzeroberfläche.
Warten Sie eine Weile, die VM wird erfolgreich laufen.
Die neu generierte CSI-Datei ist eine erwartete Geräte-Datei.
$ ls /var/lib/kubelet/plugins/kubernetes.io/csi/volumeDevices/publish/pvc-f1798969-5b72-4d76-9f0e-64854af7b59c/ -alth ... brw-rw---- 1 root root 8, 64 Mar 6 11:47 7beb531d-a781-4775-ba5e-8773773d77f1
IP-Adresse der virtuellen Maschine wird nicht angezeigt
Das qemu-guest-agent Paket ist nicht installiert
Beschreibung
Der Virtuelle Maschinen Bildschirm in der SUSE Virtualization Benutzeroberfläche zeigt die IP-Adresse einer neu erstellten oder importierten virtuellen Maschine nicht an.
Analyse
Dieses Problem tritt normalerweise auf, wenn das qemu-guest-agent Paket auf der virtuellen Maschine nicht installiert ist. Um festzustellen, ob dies die Ursache ist, überprüfen Sie den Status des VirtualMachineInstance Objekts.
$ kubectl get vmi -n <NAMESPACE> <NAME> -ojsonpath='{.status.interfaces[0].infoSource}'Die Ausgabe enthält nicht die Zeichenfolge guest-agent, wenn das qemu-guest-agent Paket nicht installiert ist.
Umgehung des Problems
Sie können den QEMU-Gastagenten installieren, indem Sie die Konfiguration der virtuellen Maschine bearbeiten.
-
Gehen Sie in der SUSE Virtualization Benutzeroberfläche zu Virtuelle Maschinen.
-
Suchen Sie die betroffene virtuelle Maschine und wählen Sie dann ⋮ → Konfiguration bearbeiten aus.
-
Gehen Sie auf die Registerkarte Erweiterte Optionen, und wählen Sie unter Cloud-Konfiguration Gastagenten installieren aus.
-
Klicken Sie auf Speichern.
Allerdings wird cloud-init nur einmal ausgeführt (wenn die virtuelle Maschine zum ersten Mal gestartet wird). Um neue Cloud Config-Einstellungen anzuwenden, müssen Sie das cloud-init-Verzeichnis in der virtuellen Maschine löschen.
$ sudo rm -rf /var/lib/cloud/*Nachdem Sie das Verzeichnis gelöscht haben, müssen Sie die virtuelle Maschine neu starten, damit cloud-init erneut ausgeführt wird und das qemu-guest-agent Paket installiert wird.
IPv6-Race-Condition zwischen virt-launcher Pod und Gastbetriebssystem
Beschreibung
Die SUSE Virtualization Benutzeroberfläche zeigt die IP-Adresse der virtuellen Maschine nicht an, wenn die Netzwerkschnittstelle des virt-launcher Pods eine IPv6-Link-Local-Adresse erhält.
Analyse
Der QEMU-Gastagent ist dafür verantwortlich, Informationen über das Gastbetriebssystem, einschließlich Schnittstellendetails, an die Instanz der virtuellen Maschine zu melden, um sie in der SUSE Virtualization Benutzeroberfläche anzuzeigen. Das Problem tritt auf, wenn die Pod-Schnittstelle der virtuellen Maschine eine IPv6-Link-Local-Adresse erhält und diese an die Instanz der virtuellen Maschine meldet, bevor der QEMU-Gastagent seine eigenen Informationen bereitstellen kann. Sobald dies geschieht, wird die IPv4-Adresse des QEMU-Gastagenten aufgrund eines Fehlers in KubeVirt niemals gemeldet.
Sie können die IP-Adresse der Pod-Schnittstelle und der Instanz der virtuellen Maschine mit den folgenden Schritten überprüfen:
-
Rufen Sie die IP-Adresse der virtuellen Maschineninstanz ab:
$ kubectl get vmi -n <NAMESPACE> <NAME> -ojsonpath='{.status.interfaces[0].ipAddress}'
Die Ausgabe zeigt nur die IPv6-Link-Local-Adresse an.
-
Rufen Sie die IP-Adresse des Pod-Interfaces ab:
$ kubectl exec -it -n <namespace> <pod-name> -- /bin/bash -c "ip a show label pod\*"
Die Ausgabe entspricht der IPv6-Adresse der virtuellen Maschineninstanz.
-
Um die zugewiesene IPv4-Adresse abzurufen, öffnen Sie die serielle Konsole der virtuellen Maschine und führen Sie
ip aim Gastbetriebssystem aus.
|
Dieses Problem hat in der Regel keine Auswirkungen auf den Betrieb und die Betriebszeit der virtuellen Maschine. Sie können weiterhin über SSH auf die virtuelle Maschine zugreifen, indem Sie die IPv4-Adresse der Netzwerkschnittstelle verwenden. In bestimmten Fällen kann dieses Problem die Rancher-Integration beeinträchtigen, was dazu führt, dass es bei der Bereitstellung und dem Beitreten von Knoten im Gastcluster zu Time-outs kommt. |
Umgehung des Problems
Die Lösung besteht darin, IPv6 in den Kernel-Parametern von SUSE Virtualization zu deaktivieren.
Fügen Sie im obigen Beispiel ipv6.disable=1 hinzu und starten Sie die Knoten neu, um zu verhindern, dass die Pod-Schnittstellen der virtuellen Maschine eine IPv6-Link-Local-Adresse erhalten.
IP-Adresse der virtuellen Maschine wird intermittierend nicht angezeigt
Beschreibung
Die IP-Adresse neuer virtueller Maschinen verschwindet intermittierend und erscheint wieder in der SUSE Virtualization Benutzeroberfläche.
Analyse
Der QEMU-Gastagent ist dafür verantwortlich, Informationen über das Gastbetriebssystem, einschließlich Schnittstellendetails, an die Instanz der virtuellen Maschine zu melden, um sie in der SUSE Virtualization Benutzeroberfläche anzuzeigen. Das Problem tritt auf, wenn die virtuelle Maschineninstanz mit Domänendaten aktualisiert wird, die leere Netzwerkschnittstellen enthalten, was durch ein Upstream-KubeVirt-Problem verursacht wird.
Dieses Verhalten wird häufiger in Alma Linux 9 und Rocky Linux 9 beobachtet, wobei der QEMU-Gastagent häufig Dateisysteminformationen an die virtuelle Maschineninstanz aktualisiert.
Um zu überprüfen, ob das Problem in Ihrer Umgebung besteht, führen Sie den folgenden Befehl zu verschiedenen Zeiten aus:
$ kubectl get vmi -n <NAMESPACE> <NAME> -ojsonpath='{.status.interfaces[0].ipAddress}'
Das ipAddress Feld kann leer sein, wenn Sie den Befehl ausführen.
Um die zugewiesene IPv4-Adresse abzurufen, öffnen Sie die serielle Konsole der virtuellen Maschine und führen Sie ip a im Gastbetriebssystem aus.
| Dieses Problem hat in der Regel keine Auswirkungen auf den Betrieb und die Betriebszeit der virtuellen Maschine. Sie können weiterhin über SSH auf die virtuelle Maschine zugreifen, indem Sie die IPv4-Adresse der Netzwerkschnittstelle verwenden. |
Umgehung des Problems
Während für dieses Problem keine direkte Lösung verfügbar ist, hat ein [upstream Fix](https://github.com/kubevirt/kubevirt/pull/13624) den Code optimiert, um unnötige Updates vom QEMU-Gastagenten zu reduzieren. Diese Verbesserung kann verhindern, dass das Problem auftritt.
Nicht planbare virtuelle Maschinen
Eine virtuelle Maschine kann als Unschedulable markiert werden, weil eine Affinitätsregel nicht erfüllt ist.
Konkret enthält das VirtualMachine Objekt eine Affinitätsregel, die der folgenden ähnlich ist:
apiVersion: kubevirt.io/v1
kind: VirtualMachine
metadata:
name: vm100
namespace: default
spec:
affinity:
nodeAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
nodeSelectorTerms:
- matchExpressions:
- key: network.harvesterhci.io/cn2
operator: In
values:
- 'true'Der Pod-Status ist Pending, und die Fehlermeldung zeigt an, dass kein Knoten die Kriterien der Affinitätsregel erfüllt.
Beispiel:
$ kubectl get pods
NAME READY STATUS RESTARTS AGE
virt-launcher-vm100-f4nh4 0/2 Pending 0 5m12s
$ kubectl get pods virt-launcher-vm100-f4nh4 -oyaml
apiVersion: v1
kind: Pod
metadata:
name: virt-launcher-vm100-f4nh4
namespace: default
spec:
affinity:
nodeAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
nodeSelectorTerms:
- matchExpressions:
- key: network.harvesterhci.io/cn2
operator: In
values:
- "true"
...
status:
conditions:
- lastProbeTime: null
lastTransitionTime: "2025-07-28T16:21:56Z"
message: '0/2 nodes are available: 1 node(s) didn''t match Pod''s node affinity/selector,
1 node(s) had untolerated taint {node.kubernetes.io/unreachable: }. preemption:
0/2 nodes are available: 2 Preemption is not helpful for scheduling.'
reason: Unschedulable
status: "False"
type: PodScheduled
...Hauptursache
SUSE Virtualization kann automatisch Affinitätsregeln anwenden basierend darauf, wie eine virtuelle Maschine konfiguriert ist. Im Beispiel verbindet sich die virtuelle Maschine vm100 mit dem Cluster-Netzwerk cn2, und SUSE Virtualization wendet die Affinitätsregel network.harvesterhci.io/cn2 an. Allerdings erfüllen keine Knoten die Kriterien der Regel, sodass die virtuelle Maschine nicht geplant werden kann.
Unabsichtliche Modifikation der virtuellen Maschinenvorlage über Cloud-Config-YAML
Wenn Sie eine Vorlage verwenden, um eine virtuelle Maschine zu erstellen, und dann die Benutzerdaten dieser virtuellen Maschine mit der Funktion Edit as YAML ändern, kann die Quellvorlage unabsichtlich geändert werden, sobald Sie die Änderungen speichern.
Dieses Problem tritt auf, weil das System die Konfigurationsvererbung nicht richtig trennt. Da die neue Konfiguration mit der Quellvorlage verknüpft bleibt, überschreibt das Speichern der Änderungen automatisch die Daten der Vorlage.
|
Vermeiden Sie die Verwendung der Funktion Edit as YAML, wenn Sie virtuelle Maschinen erstellen, insbesondere wenn Sie eine Vorlage verwenden. Verwenden Sie stattdessen die dedizierten Felder und Optionen auf der * Virtuellen Maschine: Erstellen * Bildschirm. |
Um das Problem zu mildern, führen Sie die folgenden Schritte aus:
-
Identifizieren Sie den Namen und den Namespace der betroffenen virtuellen Maschine.
-
Identifizieren Sie das Cloud Config-Geheimnis, das mit der betroffenen virtuellen Maschine verbunden ist.
# Get the current Secret name linked to the VM's cloudInitNoCloud volume source: VM_NAME=<VM_NAME> VM_NAMESPACE=<VM_NAMESPACE> SECRET=$(kubectl get vm $VM_NAME -n $VM_NAMESPACE -o jsonpath='{.spec.template.spec.volumes[?(@.cloudInitNoCloud)].cloudInitNoCloud.secretRef.name}') SECRET_NAMESPACE=$(kubectl get secret -A | grep $SECRET | awk '{print $1}') echo "Current Secret: $SECRET_NAMESPACE -> $SECRET" -
Erstellen Sie eine unabhängige Kopie des Geheimnisses.
Exportieren Sie das aktuelle Geheimnis, entfernen Sie die identifizierenden Metadaten, weisen Sie einen eindeutigen Namen zu und wenden Sie dann das Geheimnis an.
# Define a new, unique name for the secret NEW_SECRET="$VM_NAME-$(date +%s)" # Export, clean, rename, and create the new Secret kubectl get secret $SECRET -n $SECRET_NAMESPACE -o json | \ jq 'del(.metadata.creationTimestamp, .metadata.resourceVersion, .metadata.uid, .metadata.ownerReferences, .metadata.annotations["kubectl.kubernetes.io/last-applied-configuration"], .metadata.selfLink)' | \ jq '.metadata.name = "'"$NEW_SECRET"'"' | \ jq '.metadata.namespace = "'"$VM_NAMESPACE"'"' | \ kubectl apply -n $VM_NAMESPACE -f - -
Aktualisieren Sie die Konfiguration der virtuellen Maschine, um das neue Geheimnis zu verwenden.
Richten Sie die
cloudInitNoCloudVolumensquelle der virtuellen Maschine auf das neue Geheimnis aus.# Patch the VM to replace the secretRef name VOLUME_INDEX=$(kubectl get vm $VM_NAME -n $NAMESPACE -o json | jq '.spec.template.spec.volumes | to_entries[] | select(.value.cloudInitNoCloud != null) | .key') kubectl patch vm $VM_NAME -n $VM_NAMESPACE --type='json' \ -p='[{"op": "replace", "path": "/spec/template/spec/volumes/'$VOLUME_INDEX'/cloudInitNoCloud/secretRef/name", "value": "'"$NEW_SECRET"'"}, {"op": "replace", "path": "/spec/template/spec/volumes/'$VOLUME_INDEX'/cloudInitNoCloud/networkDataSecretRef/name", "value": "'"$NEW_SECRET"'"}]'
Sobald die Cloud Config durch ein einzigartiges Geheimnis gesichert ist, können Sie den YAML-Editor der SUSE Virtualization Benutzeroberfläche verwenden, um die Konfiguration der virtuellen Maschine zu bearbeiten, ohne die Quellvorlage zu beeinträchtigen.
Verwandtes Problem: #9207