|
Dieses Dokument wurde mithilfe automatisierter maschineller Übersetzungstechnologie übersetzt. Wir bemühen uns um korrekte Übersetzungen, übernehmen jedoch keine Gewähr für die Vollständigkeit, Richtigkeit oder Zuverlässigkeit der übersetzten Inhalte. Im Falle von Abweichungen ist die englische Originalversion maßgebend und stellt den verbindlichen Text dar. |
Fehlerbehebung
Übersicht
Hier sind einige Tipps zur Fehlersuche bei einem fehlgeschlagenen Upgrade:
-
Überprüfen Sie die versionsspezifischen Upgrade-Hinweise. Sie können auf die Version in der Supportmatrix-Tabelle klicken, um zu sehen, ob es bekannte Probleme gibt.
-
Tauchen Sie in den Upgrade Entwurfsvorschlag ein. Der folgende Abschnitt beschreibt kurz die Phasen innerhalb eines Upgrades und mögliche Diagnosemethoden.
Upgrade-Flow
Der Upgrade-Prozess umfasst mehrere Phasen.
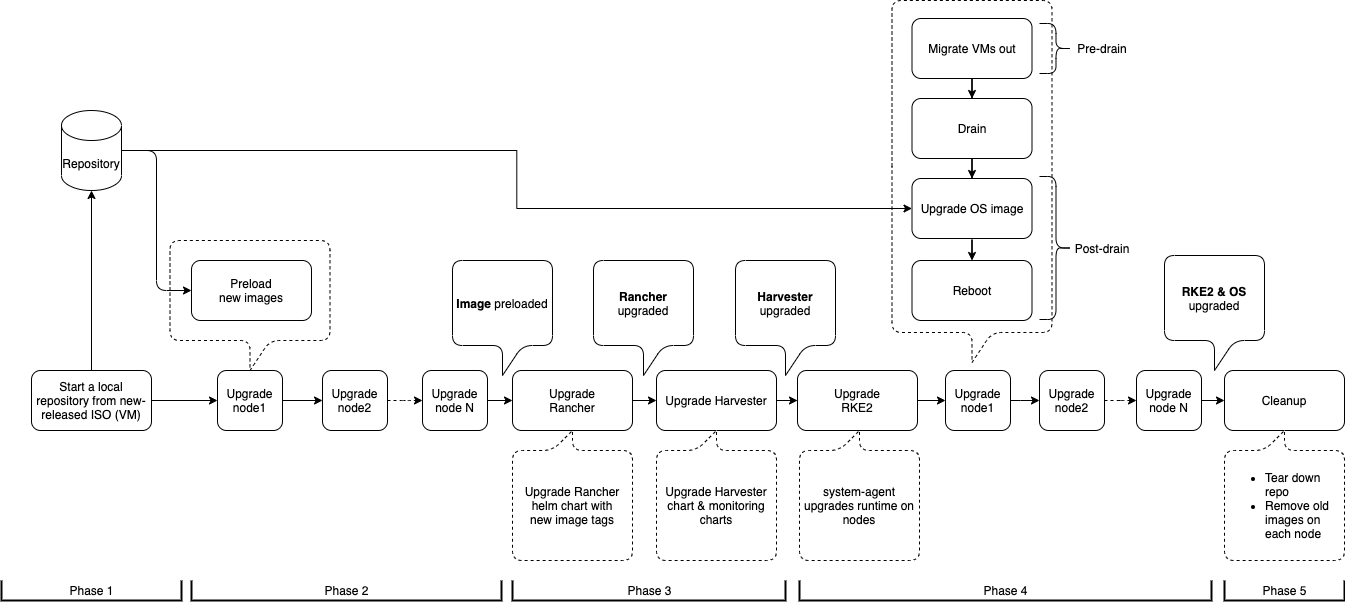
Phase 1: Bereitstellung der Upgrade-Repository-virtuellen Maschine
Der SUSE Virtualization Controller lädt eine Release-ISO-Datei herunter und verwendet sie zur Bereitstellung einer Repository-virtuellen Maschine. Der Name der virtuellen Maschine verwendet das Format upgrade-repo-hvst-xxxx.
Die Netzwerkgeschwindigkeit und die Ressourcennutzung des Clusters beeinflussen die benötigte Zeit, um diese Phase abzuschließen. Upgrades schlagen typischerweise aufgrund von Netzwerkgeschwindigkeitsproblemen fehl.
Wenn das Upgrade an diesem Punkt fehlschlägt, überprüfen Sie den Status der Repository-virtuellen Maschine und ihres entsprechenden Pods, bevor Sie das Upgrade neu starten. Sie können den Status mit dem Befehl kubectl get vm -n harvester-system überprüfen.
Beispiel:
$ kubectl get vm -n harvester-system
NAME AGE STATUS READY
upgrade-repo-hvst-upgrade-9gmg2 101s Starting False
$ kubectl get pods -n harvester-system | grep upgrade-repo-hvst
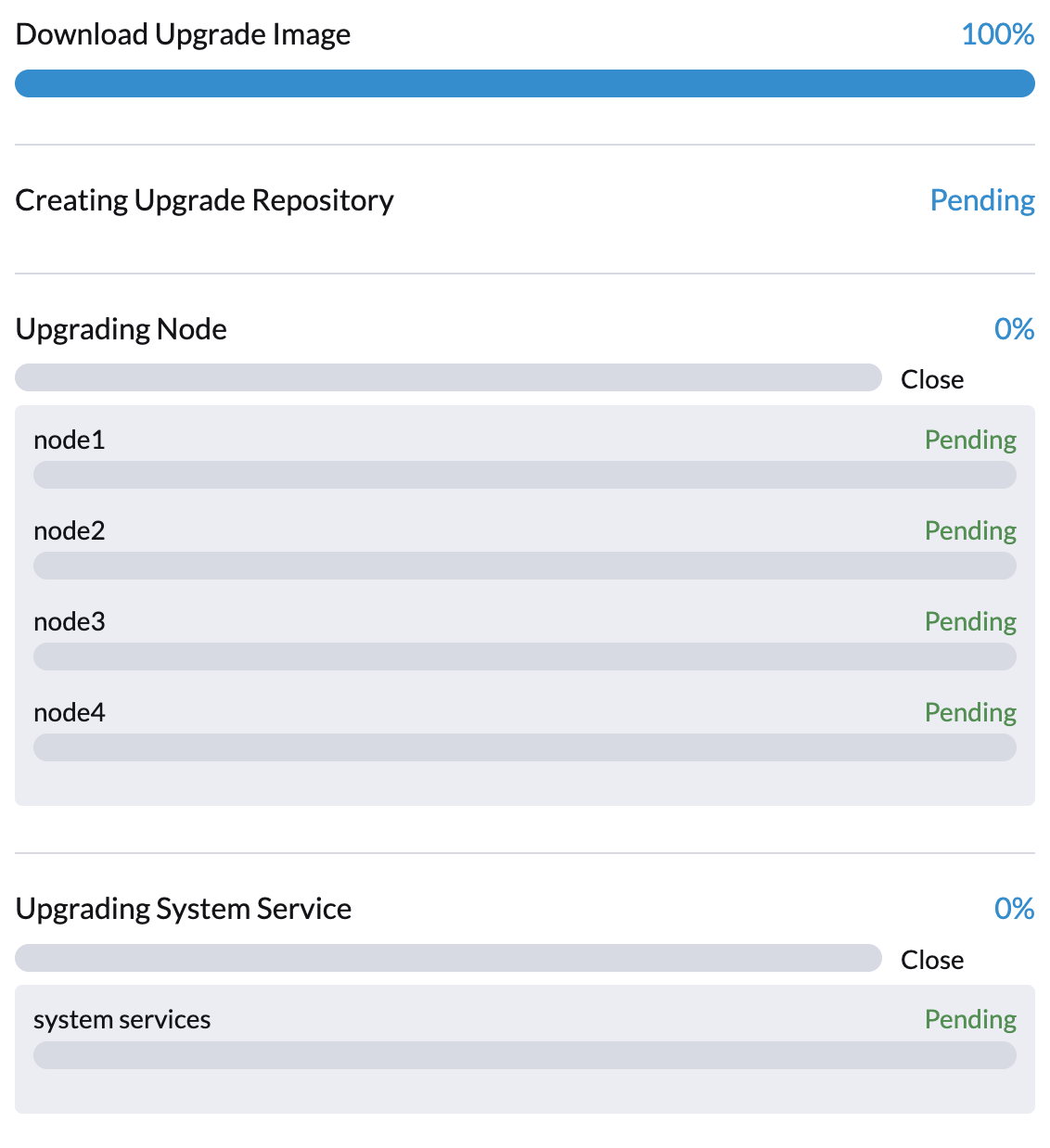
virt-launcher-upgrade-repo-hvst-upgrade-9gmg2-4mnmq 1/1 Running 0 4m44sPhase 2: Vorladen von Container-Images
Der SUSE Virtualization Controller erstellt Jobs, die Container-Images von der Repository-virtuellen Maschine herunterladen und vorladen. Diese Images sind für das nächste Release erforderlich.
Lassen Sie etwas Zeit, damit die Images auf allen Knoten heruntergeladen und vorgeladen werden.

Wenn das Upgrade an diesem Punkt fehlschlägt, überprüfen Sie die Jobprotokolle im cattle-system Namespace, bevor Sie das Upgrade neu starten. Sie können die Protokolle mit dem Befehl kubectl get jobs -n cattle-system | grep prepare überprüfen.
Beispiel:
$ kubectl get jobs -n cattle-system | grep prepare
apply-hvst-upgrade-9gmg2-prepare-on-node1-with-2bbea1599a-f0e86 0/1 47s 47s
apply-hvst-upgrade-9gmg2-prepare-on-node4-with-2bbea1599a-041e4 1/1 2m3s 2m50s
$ kubectl logs jobs/apply-hvst-upgrade-9gmg2-prepare-on-node1-with-2bbea1599a-f0e86 -n cattle-system
...Phase 3: Systemdienste aktualisieren
Der SUSE Virtualization Controller erstellt einen Job, der die Helm-Charts der Komponenten aktualisiert.
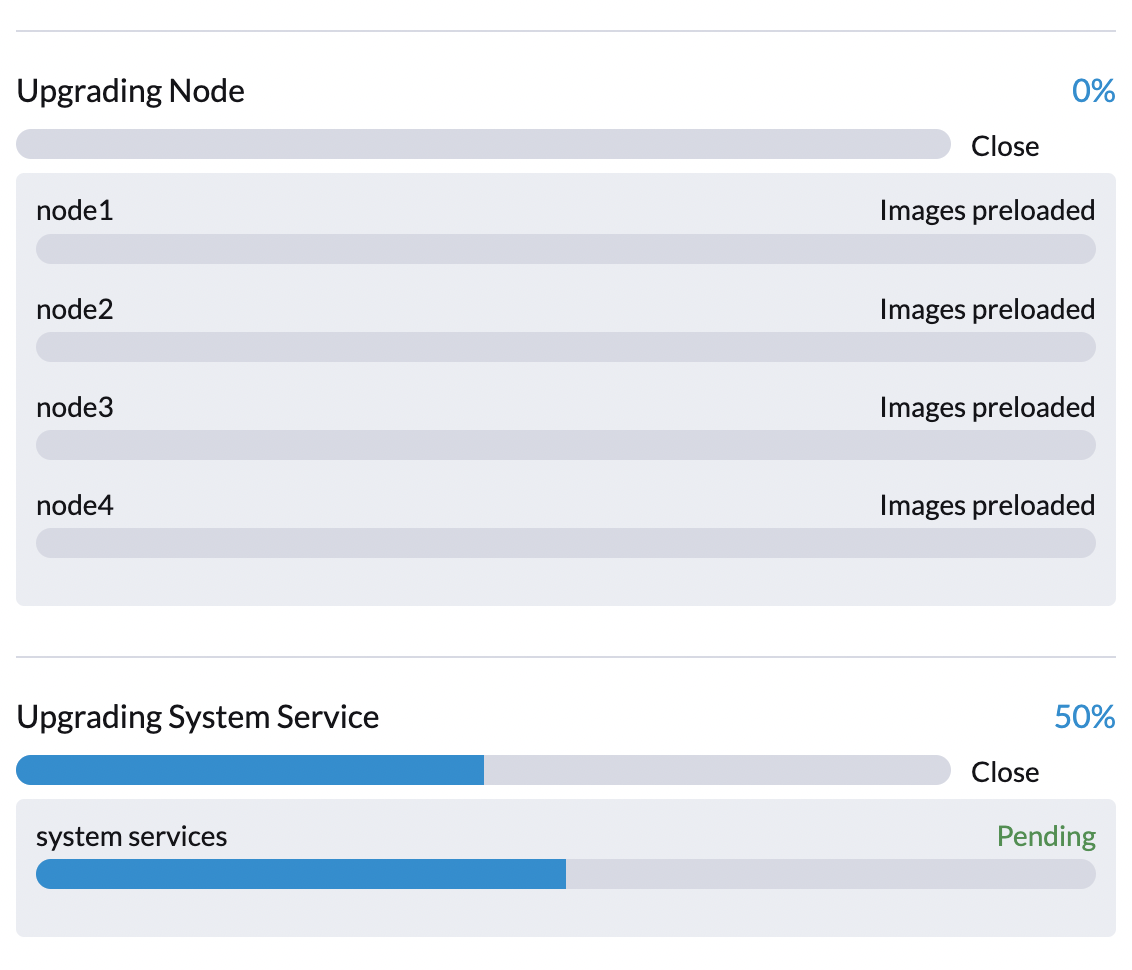
Sie können den apply-manifest Job mit dem Befehl $ kubectl get jobs -n harvester-system -l harvesterhci.io/upgradeComponent=manifest überprüfen.
Beispiel:
$ kubectl get jobs -n harvester-system -l harvesterhci.io/upgradeComponent=manifest
NAME COMPLETIONS DURATION AGE
hvst-upgrade-9gmg2-apply-manifests 0/1 46s 46s
$ kubectl logs jobs/hvst-upgrade-9gmg2-apply-manifests -n harvester-system
...|
Wenn das Upgrade an diesem Punkt fehlschlägt, müssen Sie ein Support-Bundle erstellen, bevor Sie das Upgrade neu starten. Das Support-Bundle enthält Protokolle und Ressourcenmanifeste, die helfen können, die Ursache des Fehlers zu identifizieren. |
Phase 4: Knoten aktualisieren
Der SUSE Virtualization Controller erstellt die folgenden Jobs auf jedem Knoten:
-
Cluster mit mehreren Knoten:
-
pre-drainJob: Migriert virtuelle Maschinen auf dem Knoten live oder fährt sie herunter. Sobald dies abgeschlossen ist, aktualisiert der eingebettete Rancher Dienst die RKE2 Laufzeit auf dem Knoten. -
post-drainAuftrag: Aktualisiert und startet das Betriebssystem neu.
-
-
Cluster mit einem Knoten:
-
single-node-upgradeAuftrag: Aktualisiert das Betriebssystem und die RKE2 Laufzeit. Der Name des Jobs verwendet das Formathvst-upgrade-xxx-single-node-upgrade-<hostname>.
-

Sie können die auf jedem Knoten laufenden Jobs überprüfen, indem Sie den Befehl kubectl get jobs -n harvester-system -l harvesterhci.io/upgradeComponent=node ausführen.
Beispiel:
$ kubectl get jobs -n harvester-system -l harvesterhci.io/upgradeComponent=node
NAME COMPLETIONS DURATION AGE
hvst-upgrade-9gmg2-post-drain-node1 1/1 118s 6m34s
hvst-upgrade-9gmg2-post-drain-node2 0/1 9s 9s
hvst-upgrade-9gmg2-pre-drain-node1 1/1 3s 8m14s
hvst-upgrade-9gmg2-pre-drain-node2 1/1 7s 85s
$ kubectl logs -n harvester-system jobs/hvst-upgrade-9gmg2-post-drain-node2
...|
Wenn das Upgrade an diesem Punkt fehlschlägt, starten Sie das Upgrade nicht neu, es sei denn, Sie werden von SUSE Support dazu aufgefordert. |
Häufige Vorgänge
Starten Sie das Upgrade neu
|
Wenn das laufende Upgrade bei [Phase 4: Upgrade nodes] fehlschlägt oder hängen bleibt, starten Sie das Upgrade nicht neu, es sei denn, Sie werden von SUSE Support dazu aufgefordert. |
-
Erzeugen Sie ein Support-Bundle.
-
Klicken Sie auf die Schaltfläche Upgrade auf dem Dashboard Bildschirm.
Wenn Sie die Version angepasst haben, müssen Sie möglicherweise das Versionsobjekt erneut erstellen.
Beenden Sie das laufende Upgrade
|
Wenn ein laufendes Upgrade bei [Phase 4: Upgrade nodes] fehlschlägt oder hängen bleibt, identifizieren Sie zuerst die Ursache. |
Sie können das Upgrade beenden, indem Sie die folgenden Schritte ausführen:
-
Melden Sie sich an einem Steuerungsknoten an.
-
Rufen Sie eine Liste von
UpgradeCRs im Cluster ab.# become root $ sudo -i # list the on-going upgrade $ kubectl get upgrade.harvesterhci.io -n harvester-system -l harvesterhci.io/latestUpgrade=true NAME AGE hvst-upgrade-9gmg2 10m -
Löschen Sie den
UpgradeCR.$ kubectl delete upgrade.harvesterhci.io/hvst-upgrade-9gmg2 -n harvester-system -
Setzen Sie die pausierten ManagedCharts fort.
ManagedCharts werden pausiert, um ein Datenrennen zwischen dem Upgrade und anderen Prozessen zu vermeiden. Sie müssen alle pausierten ManagedCharts manuell fortsetzen.
cat > resumeallcharts.sh << 'FOE' resume_all_charts() { local patchfile="/tmp/charttmp.yaml" cat >"$patchfile" << 'EOF' spec: paused: false EOF echo "the to-be-patched file" cat "$patchfile" local charts="harvester harvester-crd rancher-monitoring-crd rancher-logging-crd" for chart in $charts; do echo "unapuse managedchart $chart" kubectl patch managedcharts.management.cattle.io $chart -n fleet-local --patch-file "$patchfile" --type merge || echo "failed, check reason" done rm "$patchfile" } resume_all_charts FOE chmod +x ./resumeallcharts.sh ./resumeallcharts.sh
Laden Sie die Upgrade-Protokolle herunter
SUSE Virtualization sammelt automatisch alle upgradebezogenen Protokolle und zeigt den Upgrade-Vorgang an. Standardmäßig ist dies aktiviert. Sie können auch wählen, sich von einem solchen Verhalten abzumelden.
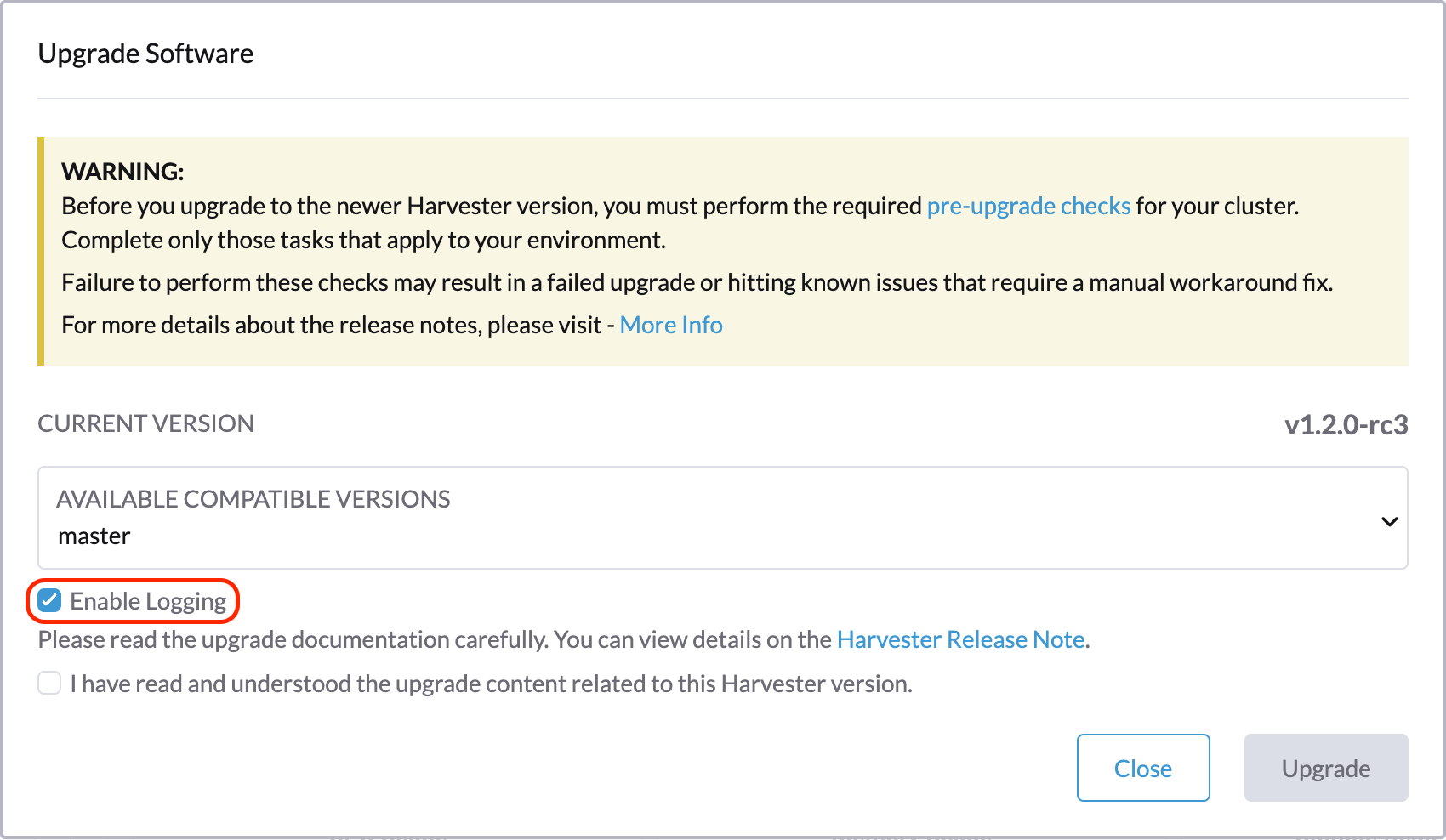
Sie können auf die Schaltfläche Protokoll herunterladen klicken, um das Protokollarchiv während eines Upgrades herunterzuladen.
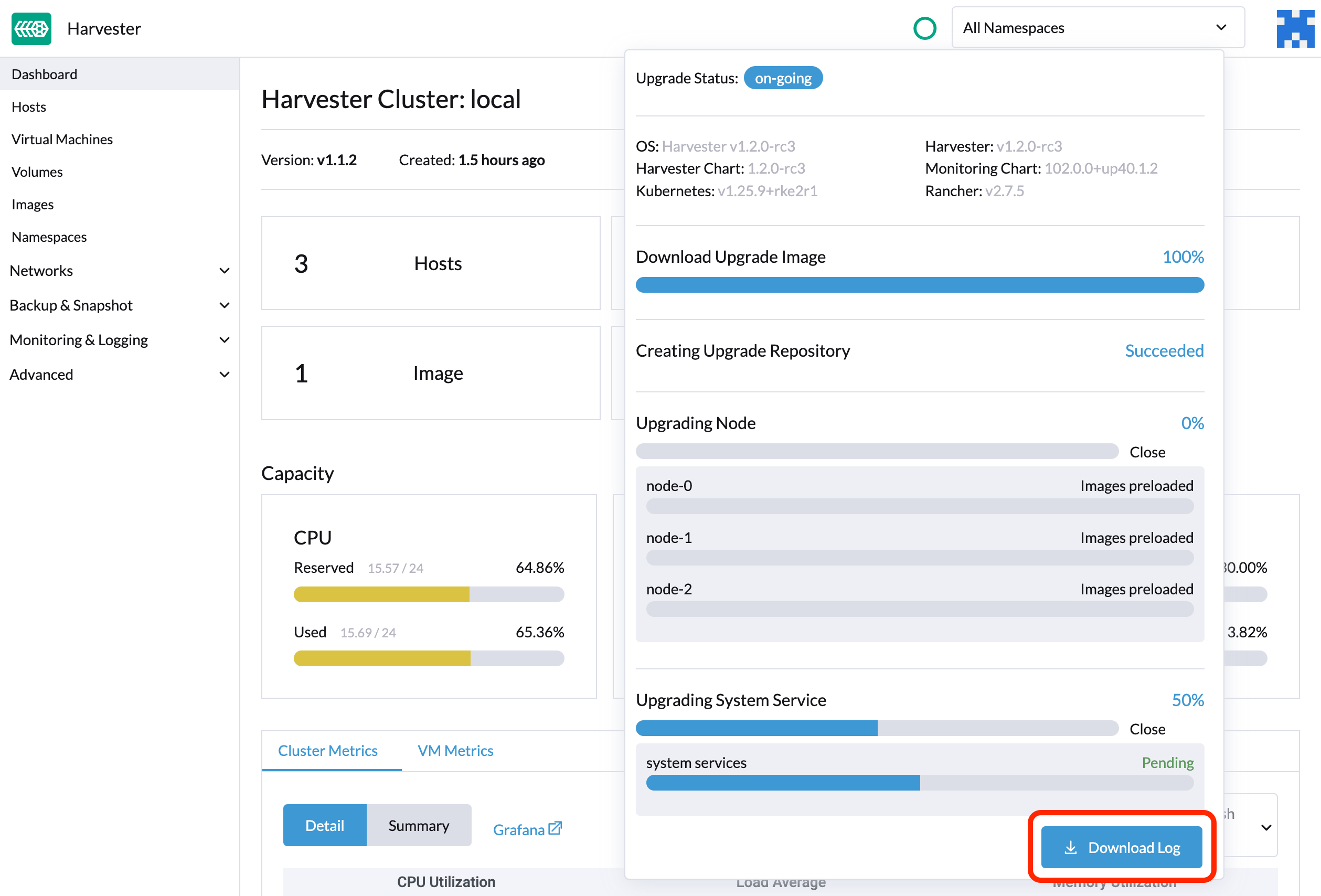
Protokolleinträge werden als Dateien für jedes Upgrade-bezogene Pod gesammelt, auch für Zwischen-Pods. Das Support-Bundle bietet einen Snapshot des aktuellen Zustands des Clusters, einschließlich Protokollen und Ressourcen-Manifests, während das Upgrade-Protokoll alle während eines Upgrades generierten Protokolle bewahrt. Durch die Kombination dieser beiden können Sie die Probleme während der Upgrades weiter untersuchen.
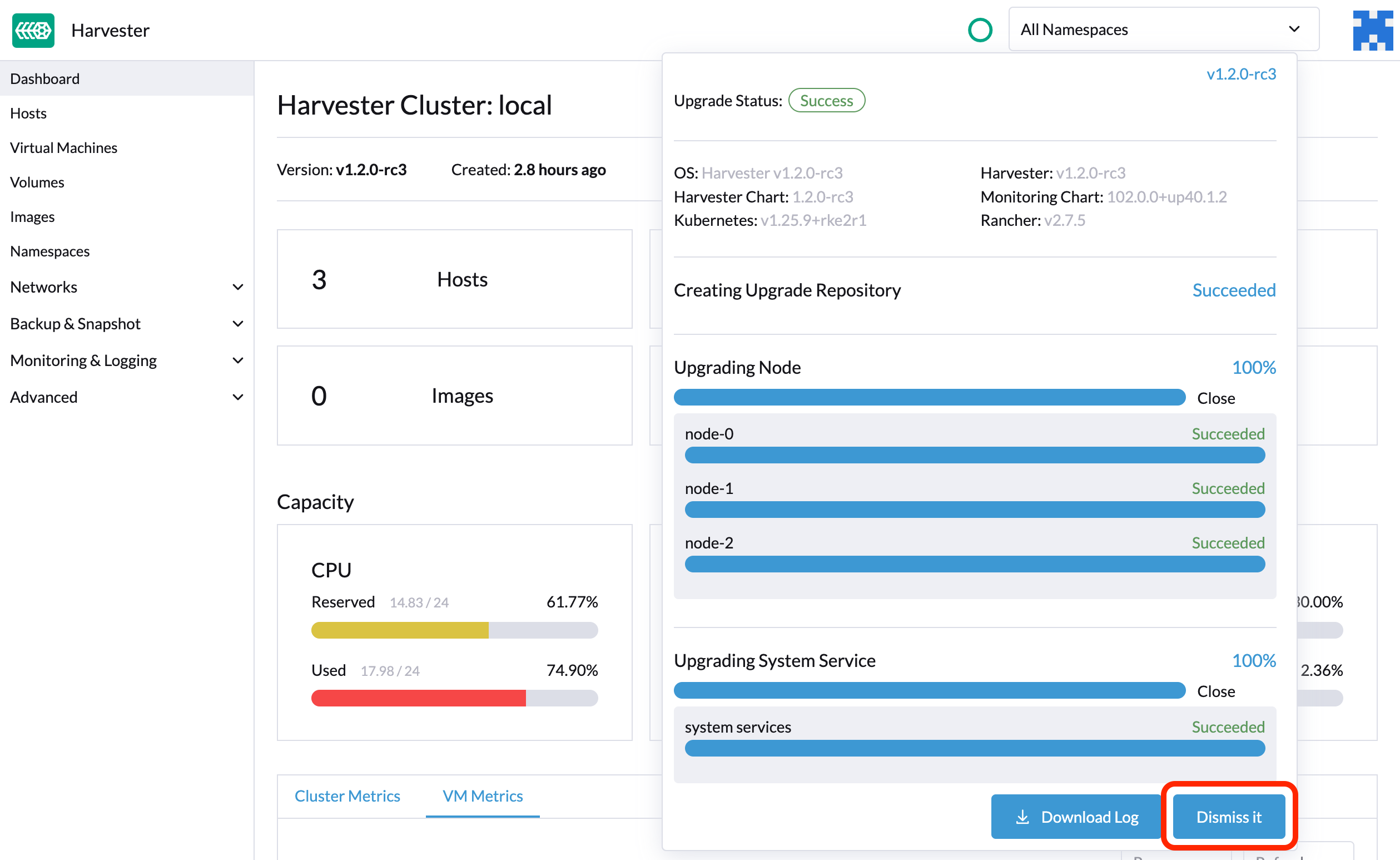
Nachdem das Upgrade beendet ist, hört SUSE Virtualization auf, die Upgrade-Protokolle zu sammeln, um zu vermeiden, dass der Speicherplatz belegt wird. Darüber hinaus können Sie auf die Schaltfläche Schließen klicken, um die Upgrade-Protokolle zu löschen.
|
Die Diese Komponenten verbrauchen jedoch weiterhin Cluster-Ressourcen und können bestimmte Operationen blockieren, wie z.B. das Aktualisieren der Netzwerkeinstellungen für den Speicher (siehe Problem #9599). Um Ressourcen freizugeben und Operationen zu entsperren, führen Sie eine der folgenden Aktionen aus:
|
Für weitere Details verweisen Sie bitte auf das Upgrade-Protokoll HEP.
|
Die Standardgröße des Volumens, das upgradebezogene Protokolle speichert, beträgt 1 GB. Wenn Fehler auftreten, können diese Protokolle den verfügbaren Speicherplatz des Volumens vollständig aufbrauchen. Um dieses Problem zu umgehen, können Sie die folgenden Schritte ausführen:
|
Bereinigen Sie ungenutzte Images.
Der Standardwert von imageGCHighThresholdPercent in KubeletConfiguration ist 85. Wenn die Speichernutzung 85 % überschreitet, versucht der Kubelet, ungenutzte Images zu entfernen.
Neue Images werden während der Upgrades auf jeden SUSE Virtualization Knoten geladen. Wenn die Speichernutzung 85 % überschreitet, können diese neuen Images zur Bereinigung markiert werden, da sie von keinen Containern verwendet werden. In Air-Gapped-Umgebungen kann das Entfernen neuer Images aus dem Cluster den Upgrade-Prozess unterbrechen.
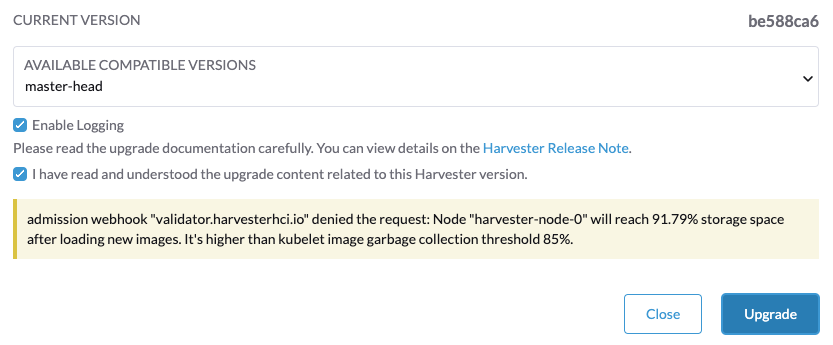
Wenn Sie die Fehlermeldung Node xxx will reach xx.xx% storage space after loading new images. It’s higher than kubelet image garbage collection threshold 85%. erhalten, führen Sie crictl rmi --prune aus, um ungenutzte Images zu bereinigen, bevor Sie ein neues Upgrade starten.
Überprüfen Sie den Status eines festgefahrenen Upgrades.
Wenn das Upgrade feststeckt und die SUSE Virtualization Benutzeroberfläche keine Fehlermeldungen anzeigt, führen Sie die folgenden Schritte aus:
-
Überprüfen Sie die Pods, die während des Upgrade-Prozesses mit dem Befehl
kubectl get pods -n harvester-system | grep upgradeerstellt wurden.Das Hauptskript befindet sich im
hvst-upgrade-xxxxx-apply-manifests-xxxxxPod. Wenn die Protokolle die folgenden Nachrichten enthalten, könnte dermanagedChartCR Probleme verursachen.Current version: x.x.x, Current state: WaitApplied, Current generation: x Sleep for 5 seconds to retry -
Rufen Sie Informationen über den
bundleCR mit dem Befehlkubectl get bundles -Aab.Beispiel:
NAMESPACE NAME BUNDLEDEPLOYMENTS-READY STATUS fleet-local fleet-agent-local 1/1 fleet-local local-managed-system-agent 1/1 fleet-local mcc-harvester 0/1 Modified(1) [Cluster fleet-local/local]; kubevirt.kubevirt.io harvester-system/kubevirt modified {"spec":{"configuration":{"vmStateStorageClass":"vmstate-persistence"}}} fleet-local mcc-harvester-crd 1/1 fleet-local mcc-local-managed-system-upgrade-controller 1/1 fleet-local mcc-rancher-logging-crd 1/1 fleet-local mcc-rancher-monitoring-crd 1/1