|
Dieses Dokument wurde mithilfe automatisierter maschineller Übersetzungstechnologie übersetzt. Wir bemühen uns um korrekte Übersetzungen, übernehmen jedoch keine Gewähr für die Vollständigkeit, Richtigkeit oder Zuverlässigkeit der übersetzten Inhalte. Im Falle von Abweichungen ist die englische Originalversion maßgebend und stellt den verbindlichen Text dar. |
Probleme bei der Installation
Die folgenden Abschnitte enthalten Tipps zur Fehlersuche oder zur Unterstützung bei fehlgeschlagenen Installationen.
Anmeldung beim Installer (ein Live-Betriebssystem)
Benutzer können die Tastenkombination CTRL + ALT + F2 drücken, um zu einem anderen TTY zu wechseln und sich mit den folgenden Anmeldedaten einzuloggen:
-
Benutzer:
rancher -
Passwort:
rancher
Erfüllung der Hardwareanforderungen
-
Überprüfen Sie, ob Ihre Hardware die minimalen Anforderungen erfüllt, um die Installation abzuschließen.
Festgefahren in Loading images. This may take a few minutes…
Da das System keine Standardroute hat, kann Ihr Installer in diesem Zustand "festgefahren" sein. Sie können den Status Ihrer Route überprüfen, indem Sie den folgenden Befehl ausführen:
$ ip route
default via 10.10.0.10 dev mgmt-br proto dhcp <-- Does a default route exist?
10.10.0.0/24 dev mgmt-br proto kernel scope link src 10.10.0.15Überprüfen Sie, ob Ihr DHCP-Server eine Standardroutenoption anbietet. Das Anhängen von Inhalten von /run/cos/target/rke2.log ist ebenfalls hilfreich.
Für weitere Informationen siehe DHCP-Serverkonfiguration.
Ändern des Cluster-Tokens auf Agentenknoten
Wenn ein Agentenknoten nicht dem Cluster beitreten kann, kann dies daran liegen, dass das Cluster-Token nicht identisch mit dem Token des Serverknotens ist.
Um das Problem zu bestätigen, verbinden Sie sich mit Ihrem Agentenknoten (z. B. mit SSH) und überprüfen Sie das rancherd Dienstprotokoll mit dem folgenden Befehl:
sudo journalctl -b -u rancherdWenn das im Agentenknoten eingerichtete Cluster-Token nicht mit dem Token des Serverknotens übereinstimmt, finden Sie mehrere Einträge mit der folgenden Meldung:
msg="Bootstrapping Rancher (v2.7.5/v1.25.9+rke2r1)"
msg="failed to bootstrap system, will retry: generating plan: response 502: 502 Bad Gateway getting cacerts: <html>\r\n<head><title>502 Bad Gateway</title></head>\r\n<body>\r\n<center><h1>502 Bad Gateway</h1></center>\r\n<hr><center>nginx</center>\r\n</body>\r\n</html>\r\n"Beachten Sie, dass die Rancher Version und die IP-Adresse von Ihrer Umgebung abhängen und von der obigen Meldung abweichen können.
Um das Problem zu beheben, müssen Sie den Token-Wert in der rancherd Konfigurationsdatei /etc/rancher/rancherd/config.yaml aktualisieren.
Wenn das im Serverknoten eingerichtete Cluster-Token beispielsweise ThisIsTheCorrectOne ist, aktualisieren Sie den Token-Wert wie folgt:
token: 'ThisIsTheCorrectOne'Um sicherzustellen, dass die Änderung nach einem Neustart persistent bleibt, aktualisieren Sie den token Wert der Konfigurationsdatei des Betriebssystems /oem/90_custom.yaml:
name: Harvester Configuration
stages:
...
initramfs:
- commands:
- ...
files:
- path: /etc/rancher/rancherd/config.yaml
permissions: 384
owner: 0
group: 0
content: |
server: https://$cluster-vip:443
role: agent
token: "ThisIsTheCorrectOne"
kubernetesVersion: v1.25.9+rke2r1
rancherVersion: v2.7.5
rancherInstallerImage: rancher/system-agent-installer-rancher:v2.7.5
labels:
- harvesterhci.io/managed=true
extraConfig:
disable:
- rke2-snapshot-controller
- rke2-snapshot-controller-crd
- rke2-snapshot-validation-webhook
encoding: ""
ownerstring: ""|
Um den aktuellen Cluster-Token-Wert zu sehen, melden Sie sich an Ihrem Serverknoten an (z. B. mit SSH) und schauen Sie in die Datei |
Überprüfung des Status von Komponenten
Bevor Sie den Status der SUSE Virtualization Komponenten überprüfen, beschaffen Sie sich eine Kopie der Kubeconfig-Datei des Clusters, indem Sie eine der folgenden Methoden verwenden:
-
Gehen Sie im SUSE Virtualization UI zum Bildschirm Support und klicken Sie dann auf Download KubeConfig.
-
Führen Sie die folgenden Befehle auf einem der Verwaltungs-Knoten aus:
$ sudo su $ cat /etc/rancher/rke2/rke2.yaml
Nachdem Sie eine Kopie der Kubeconfig-Datei erhalten haben, führen Sie das folgende Skript gegen den Cluster aus, um die Einsatzbereitschaft jeder Komponente zu überprüfen.
-
SUSE Virtualization-Komponenten
#!/bin/bash cluster_ready() { namespaces=("cattle-system" "kube-system" "harvester-system" "longhorn-system") for ns in "${namespaces[@]}"; do pod_statuses=($(kubectl -n "${ns}" get pods \ --field-selector=status.phase!=Succeeded \ -ojsonpath='{range .items[*]}{.metadata.namespace}/{.metadata.name},{.status.conditions[?(@.type=="Ready")].status}{"\n"}{end}')) for status in "${pod_statuses[@]}"; do name=$(echo "${status}" | cut -d ',' -f1) ready=$(echo "${status}" | cut -d ',' -f2) if [ "${ready}" != "True" ]; then echo "pod ${name} is not ready" false return fi done done } if cluster_ready; then echo "cluster is ready" else echo "cluster is not ready" fi -
API
$ curl -fk https://<VIP>/versionSie müssen
<VIP>durch die aktuelle VIP ersetzen, die den Wert vonkube-vip.io/requestedIPdarstellt.
Sammlung von Informationen zur Fehlerbehebung
Bitte fügen Sie die folgenden Informationen in einen Fehlerbericht ein, wenn Sie eine fehlgeschlagene Installation melden:
-
Ein Screenshot der fehlgeschlagenen Installation.
-
Systeminformationen und Protokolle.
Bitte folgen Sie dem Leitfaden in [Logging into the Installer (a live OS)], um sich anzumelden. Und führen Sie den Befehl aus, um ein Tarball zu erstellen, das Informationen zur Fehlerbehebung enthält:
supportconfig -k -cDie Ausgabemeldungen des Befehls enthalten den Pfad des generierten Tarballs. Zum Beispiel ist der Pfad
/var/loq/scc_aaa_220520_1021 804d65d-c9ba-4c54-b12d-859631f892c5.txzim folgenden Beispiel: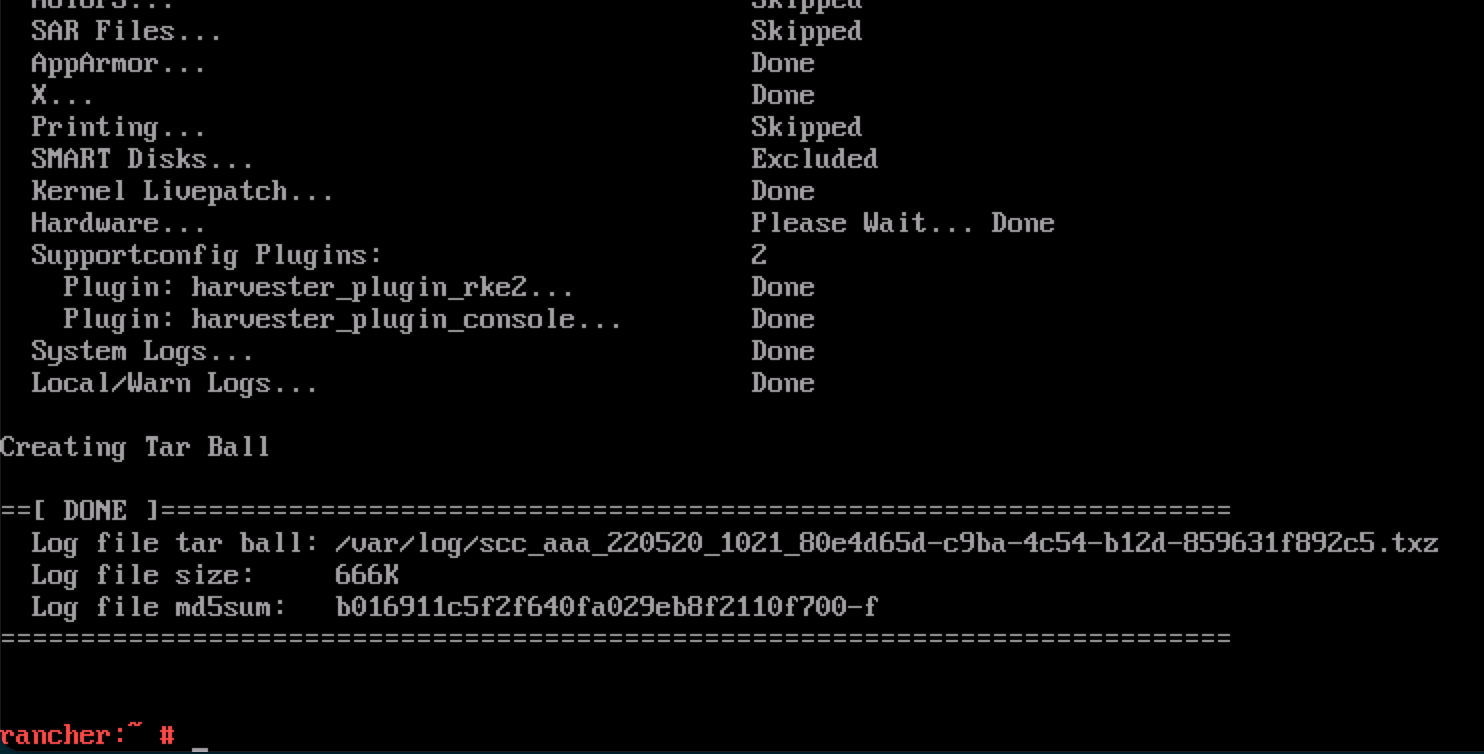
Eine fehlgeschlagene PXE-Boot-Installation generiert automatisch ein Tarball, wenn das
install.debugFeld in der Konfigurationsdatei auftruegesetzt ist.
Überprüfung des Chart-Status
SUSE Virtualization verwendet die folgenden Chart-CRDs:
-
HelmChart: Pflegt RKE2-Charts.-
rke2-runtimeclasses -
rke2-multus -
rke2-metrics-server -
rke2-ingress-nginx -
rke2-coredns -
rke2-cannal
-
-
ManagedChart: Verwaltet Rancher und SUSE Virtualization Charts.-
rancher-monitoring-crd -
rancher-logging-crd -
kubeovn-operator-crd -
harvester-crd -
harvester
-
Sie können den helm list -A Befehl verwenden, um eine Liste der installierten Charts abzurufen.
Beispiel für die Ausgabe:
NAME NAMESPACE REVISION UPDATED STATUS CHART APP VERSION
fleet cattle-fleet-system 4 2025-09-24 09:07:10.801764068 +0000 UTC deployed fleet-107.0.0+up0.13.0 0.13.0
fleet-agent-local cattle-fleet-local-system 1 2025-09-24 08:59:28.686781982 +0000 UTC deployed fleet-agent-local-v0.0.0+s-d4f65a6f642cca930c78e6e2f0d3f9bbb7d3ba47cf1cce34ac3d6b8770ce5
fleet-crd cattle-fleet-system 1 2025-09-24 08:58:28.396419747 +0000 UTC deployed fleet-crd-107.0.0+up0.13.0 0.13.0
harvester harvester-system 1 2025-09-24 08:59:37.718646669 +0000 UTC deployed harvester-0.0.0-master-ac070598 master-ac070598
harvester-crd harvester-system 1 2025-09-24 08:59:35.341316526 +0000 UTC deployed harvester-crd-0.0.0-master-ac070598 master-ac070598
kubeovn-operator-crd kube-system 1 2025-09-24 08:59:34.783356576 +0000 UTC deployed kubeovn-operator-crd-1.13.13 v1.13.13
mcc-local-managed-system-upgrade-controller cattle-system 1 2025-09-24 08:59:10.656784284 +0000 UTC deployed system-upgrade-controller-107.0.0 v0.16.0
rancher cattle-system 1 2025-09-24 08:57:20.690330683 +0000 UTC deployed rancher-2.12.0 8815e66-dirty
rancher-logging-crd cattle-logging-system 1 2025-09-24 08:59:36.262080367 +0000 UTC deployed rancher-logging-crd-107.0.1+up4.10.0-rancher.10
rancher-monitoring-crd cattle-monitoring-system 1 2025-09-24 08:59:35.287099045 +0000 UTC deployed rancher-monitoring-crd-107.1.0+up69.8.2-rancher.15
rancher-provisioning-capi cattle-provisioning-capi-system 1 2025-09-24 08:59:00.561162307 +0000 UTC deployed rancher-provisioning-capi-107.0.0+up0.8.0 1.10.2
rancher-webhook cattle-system 2 2025-09-24 09:02:38.774660489 +0000 UTC deployed rancher-webhook-107.0.0+up0.8.0 0.8.0
rke2-canal kube-system 1 2025-09-24 08:57:25.248839867 +0000 UTC deployed rke2-canal-v3.30.2-build2025071100 v3.30.2
rke2-coredns kube-system 1 2025-09-24 08:57:25.341016864 +0000 UTC deployed rke2-coredns-1.42.302 1.12.2
rke2-ingress-nginx kube-system 3 2025-09-24 09:01:31.331647555 +0000 UTC deployed rke2-ingress-nginx-4.12.401 1.12.4
rke2-metrics-server kube-system 1 2025-09-24 08:57:42.162046899 +0000 UTC deployed rke2-metrics-server-3.12.203 0.7.2
rke2-multus kube-system 1 2025-09-24 08:57:25.341560394 +0000 UTC deployed rke2-multus-v4.2.106 4.2.1
rke2-runtimeclasses kube-system 1 2025-09-24 08:57:40.137168056 +0000 UTC deployed rke2-runtimeclasses-0.1.000 0.1.0HelmChart CRD
HelmChart Elemente werden durch Jobs installiert. Sie können den Namen und den Status jedes Jobs ermitteln, indem Sie den folgenden Befehl auf dem SUSE Virtualization Knoten ausführen:
$ kubectl get helmcharts -A -o jsonpath='{range .items[*]}{"Namespace: "}{.metadata.namespace}{"\nName: "}{.metadata.name}{"\nStatus:\n"}{range .status.conditions[*]}{" - Type: "}{.type}{"\n Status: "}{.status}{"\n Reason: "}{.reason}{"\n Message: "}{.message}{"\n"}{end}{"JobName: "}{.status.jobName}{"\n\n"}{end}'Beispiel für die Ausgabe:
Namespace: kube-system
Name: rke2-canal
Status:
- Type: JobCreated
Status: True
Reason: Job created
Message: Applying HelmChart using Job kube-system/helm-install-rke2-canal
- Type: Failed
Status: False
Reason:
Message:
JobName: helm-install-rke2-canal
Namespace: kube-system
Name: rke2-coredns
Status:
- Type: JobCreated
Status: True
Reason: Job created
Message: Applying HelmChart using Job kube-system/helm-install-rke2-coredns
- Type: Failed
Status: False
Reason:
Message:
JobName: helm-install-rke2-coredns
Namespace: kube-system
Name: rke2-ingress-nginx
Status:
- Type: JobCreated
Status: True
Reason: Job created
Message: Applying HelmChart using Job kube-system/helm-install-rke2-ingress-nginx
- Type: Failed
Status: False
Reason:
Message:
JobName: helm-install-rke2-ingress-nginx
Namespace: kube-system
Name: rke2-metrics-server
Status:
- Type: JobCreated
Status: True
Reason: Job created
Message: Applying HelmChart using Job kube-system/helm-install-rke2-metrics-server
- Type: Failed
Status: False
Reason:
Message:
JobName: helm-install-rke2-metrics-server
Namespace: kube-system
Name: rke2-multus
Status:
- Type: JobCreated
Status: True
Reason: Job created
Message: Applying HelmChart using Job kube-system/helm-install-rke2-multus
- Type: Failed
Status: False
Reason:
Message:
JobName: helm-install-rke2-multus
Namespace: kube-system
Name: rke2-runtimeclasses
Status:
- Type: JobCreated
Status: True
Reason: Job created
Message: Applying HelmChart using Job kube-system/helm-install-rke2-runtimeclasses
- Type: Failed
Status: False
Reason:
Message:
JobName: helm-install-rke2-runtimeclassesSie können die Informationen auf folgende Weise verwenden:
-
Bestimmen Sie die Ursache eines fehlgeschlagenen Jobs: Überprüfen Sie die
ReasonundMessageWerte derFailedBedingung. -
Führen Sie einen Job erneut aus: Entfernen Sie das
StatusFeld für diesen speziellen Job aus derHelmChartCRD. Der Controller stellt einen neuen Job bereit.
ManagedChart CRD
Rancher verwendet SUSE® Rancher Prime: Continuous Delivery, um Charts auf Zielclustern zu installieren. SUSE Virtualization hat nur einen Zielcluster (fleet-local/local).
SUSE® Rancher Prime: Continuous Delivery setzt einen Agenten auf jedem Ziel-Cluster über helm install ein, sodass Sie das fleet-agent-local Chart mit dem helm list -A Befehl finden können. Die cluster.fleet.cattle.io CRD enthält den Status des Agenten.
apiVersion: fleet.cattle.io/v1alpha1
kind: Cluster
metadata:
name: local
namespace: fleet-local
spec:
agentAffinity:
nodeAffinity:
preferredDuringSchedulingIgnoredDuringExecution:
- preference:
matchExpressions:
- key: fleet.cattle.io/agent
operator: In
values:
- "true"
weight: 1
agentNamespace: cattle-fleet-local-system
clientID: xd8cgpm2gq5w25qf46r8ml6qxvhsg858g64s5k7wj5h947vs5sxbwd
kubeConfigSecret: local-kubeconfig
kubeConfigSecretNamespace: fleet-local
redeployAgentGeneration: 1
status:
agent:
lastSeen: "2025-09-01T07:09:28Z"
namespace: cattle-fleet-local-system
agentAffinityHash: f50425c0999a8e18c2d104cdb8cb063762763f232f538b5a7c8bdb61
agentDeployedGeneration: 1
agentMigrated: true
agentNamespaceMigrated: true
agentTLSMode: system-store
apiServerCAHash: 158866807fdf372a1f1946bb72d0fbcdd66e0e63c4799f9d4df0e18b
apiServerURL: https://10.53.0.1:443
cattleNamespaceMigrated: true
conditions:
- lastUpdateTime: "2025-08-28T04:43:02Z"
status: "True"
type: Processed
- lastUpdateTime: "2025-08-28T10:08:31Z"
status: "True"
type: Imported
- lastUpdateTime: "2025-08-28T10:08:30Z"
status: "True"
type: Reconciled
- lastUpdateTime: "2025-08-28T10:09:30Z"
status: "True"
type: ReadyRancher konvertiert die ManagedChart CRD in eine Bundle Ressource mit einem mcc- Präfix. Der SUSE® Rancher Prime: Continuous Delivery Agent überwacht Bundle Ressourcen und setzt sie im Ziel-Cluster ein. Die BundleDeployment Ressource enthält den Bereitstellungsstatus.
Der SUSE® Rancher Prime: Continuous Delivery Controller überträgt keine Daten an den Agenten. Stattdessen ruft der Agent Bundle Ressourcendaten vom Cluster ab, auf dem der SUSE® Rancher Prime: Continuous Delivery Controller installiert ist. In SUSE Virtualization befinden sich der SUSE® Rancher Prime: Continuous Delivery Controller und der Agent im selben Cluster, sodass Netzwerkprobleme keine Rolle spielen.
$ kubectl get bundledeployments -A -o jsonpath='{range .items[*]}{"Namespace: "}{.metadata.namespace}{"\nName: "}{.metadata.name}{"\nStatus:\n"}{range .status.conditions[*]}{" - Type: "}{.type}{"\n Status: "}{.status}{"\n Reason: "}{.reason}{"\n Message: "}{.message}{"\n"}{end}{"\n"}{end}'
Namespace: cluster-fleet-local-local-1a3d67d0a899
Name: fleet-agent-local
Status:
- Type: Installed
Status: True
Reason:
Message:
- Type: Deployed
Status: True
Reason:
Message:
- Type: Ready
Status: True
Reason:
Message:
- Type: Monitored
Status: True
Reason:
Message:
Namespace: cluster-fleet-local-local-1a3d67d0a899
Name: mcc-harvester
Status:
- Type: Installed
Status: True
Reason:
Message:
- Type: Deployed
Status: True
Reason:
Message:
- Type: Ready
Status: True
Reason:
Message:
- Type: Monitored
Status: True
Reason:
Message:
Namespace: cluster-fleet-local-local-1a3d67d0a899
Name: mcc-harvester-crd
Status:
- Type: Installed
Status: True
Reason:
Message:
- Type: Deployed
Status: True
Reason:
Message:
- Type: Ready
Status: True
Reason:
Message:
- Type: Monitored
Status: True
Reason:
Message:
Namespace: cluster-fleet-local-local-1a3d67d0a899
Name: mcc-kubeovn-operator-crd
Status:
- Type: Installed
Status: True
Reason:
Message:
- Type: Deployed
Status: True
Reason:
Message:
- Type: Ready
Status: True
Reason:
Message:
- Type: Monitored
Status: True
Reason:
Message:
Namespace: cluster-fleet-local-local-1a3d67d0a899
Name: mcc-rancher-logging-crd
Status:
- Type: Installed
Status: True
Reason:
Message:
- Type: Deployed
Status: True
Reason:
Message:
- Type: Ready
Status: True
Reason:
Message:
- Type: Monitored
Status: True
Reason:
Message:
Namespace: cluster-fleet-local-local-1a3d67d0a899
Name: mcc-rancher-monitoring-crd
Status:
- Type: Installed
Status: True
Reason:
Message:
- Type: Deployed
Status: True
Reason:
Message:
- Type: Ready
Status: True
Reason:
Message:
- Type: Monitored
Status: True
Reason:
Message:Wenn Sie das harvester-system/harvester Bereitstellungsimage ändern, erkennt der SUSE® Rancher Prime: Continuous Delivery Agent die Änderung und aktualisiert den entsprechenden Status in der BundleDeployment Ressource.
Beispiel:
status:
appliedDeploymentID: s-89f9ce3f33c069befb4ebdceaa103af7b71db0e70a39760cb6653366964e5:1cd9188211e318033f89b77acf7b996
e5bb3d9a25319528c47dc052528056f78
conditions:
- lastUpdateTime: "2025-08-28T04:44:18Z"
status: "True"
type: Installed
- lastUpdateTime: "2025-08-28T04:44:18Z"
status: "True"
type: Deployed
- lastUpdateTime: "2025-09-01T07:40:28Z"
message: deployment.apps harvester-system/harvester modified {"spec":{"template":{"spec":{"containers":[{"env":[{"
name":"HARVESTER_SERVER_HTTPS_PORT","value":"8443"},{"name":"HARVESTER_DEBUG","value":"false"},{"name":"HARVESTER_SERV
ER_HTTP_PORT","value":"0"},{"name":"HCI_MODE","value":"true"},{"name":"RANCHER_EMBEDDED","value":"true"},{"name":"HARV
ESTER_SUPPORT_BUNDLE_IMAGE_DEFAULT_VALUE","value":"{\"repository\":\"rancher/support-bundle-kit\",\"tag\":\"master-hea
d\",\"imagePullPolicy\":\"IfNotPresent\"}"},{"name":"NAMESPACE","valueFrom":{"fieldRef":{"apiVersion":"v1","fieldPath"
:"metadata.namespace"}}}],"image":"frankyang/harvester:fix-renovate-head","imagePullPolicy":"IfNotPresent","name":"api
server","ports":[{"containerPort":8443,"name":"https","protocol":"TCP"},{"containerPort":6060,"name":"profile","protoc
ol":"TCP"}],"resources":{"requests":{"cpu":"250m","memory":"256Mi"}},"securityContext":{"appArmorProfile":{"type":"Unc
onfined"},"capabilities":{"add":["SYS_ADMIN"]}},"terminationMessagePath":"/dev/termination-log","terminationMessagePol
icy":"File"}]}}}}Die Konsole zeigt Setting up Harvester nach der Installation am Tag 0 an.
Problembeschreibung
Nach einer erfolgreichen Installation zeigt die Konsole dauerhaft Setting up Harvester an. Während die meisten UI- und CLI-Operationen nicht betroffen sind, werden Versuche, ein Upgrade zu starten, blockiert.
Die folgende Information wird angezeigt, nachdem Sie den Befehl kubectl get managedchart -n fleet-local harvester -oyaml ausgeführt haben:
...
status:
conditions:
- lastUpdateTime: "2025-10-22T08:01:18Z"
message: 'NotReady(1) [Cluster fleet-local/local]; daemonset.apps harvester-system/harvester-network-controller
modified {"spec":{"template":{"spec":{"containers":[{"args":["agent"],"command":["harvester-network-controller"],
"env":[{"name":"NODENAME","valueFrom":{"fieldRef":{"apiVersion":"v1","fieldPath":"spec.nodeName"}}},
{"name":"NAMESPACE","valueFrom":{"fieldRef":{"apiVersion":"v1","fieldPath":"metadata.namespace"}}}],
"image":"rancher/harvester-network-controller:master-head","imagePullPolicy":"IfNotPresent","name":"harvester-network",
"resources":{"limits":{"cpu":"100m","memory":"128Mi"},"requests":{"cpu":"10m","memory":"64Mi"}},
"securityContext":{"privileged":true},"terminationMessagePath":"/dev/termination-log","terminationMessagePolicy":"File",
"volumeMounts":[{"mountPath":"/dev","name":"dev"},{"mountPath":"/lib/modules","name":"modules"}]}]}}}};'
status: "False"
type: ReadyHauptursache
Die Konsole führt den folgenden Befehl aus, um zu bestimmen, ob der Status des harvester ManagedChart (im fleet-local Namespace) Ready ist.
cmd := exec.Command("/bin/sh", "-c", kubectl -n fleet-local get ManagedChart harvester -o jsonpath='{.status.conditions}' |
jq 'map(select(.type == "Ready" and .status == "True")) | length')Die ManagedChart CRD wird von SUSE® Rancher Prime: Continuous Delivery verwendet, um Ressourcen über GitOps zu verwalten. Wenn eine dieser Ressourcen direkt geändert wird, zeichnet ManagedChart die Abweichungen auf und kennzeichnet sie. Im obigen Beispiel trat der Fehler auf, weil ein benutzerdefinierter Bild-Tag direkt auf das harvester-system/harvester-network-controller DaemonSet angewendet wurde.
Um die vollständige Liste der ManagedChart Ressourcen abzurufen, führen Sie den Befehl kubectl get bundle -n fleet-local mcc-harvester -oyaml aus.
apiVersion: fleet.cattle.io/v1alpha1
kind: Bundle
metadata:
name: mcc-harvester
namespace: fleet-local
spec:
resources:
- content: H4s...===
encoding: base64+gz
charts/harvester-network-controller/templates/daemonset.yaml
- content: ...Umgehung des Problems
Sie können eine der folgenden Aktionen durchführen:
-
Die direkten Änderungen an den betroffenen Ressourcen zurücksetzen.
-
Aktualisieren Sie die
ManagedChartCRD mit der gewünschten benutzerdefinierten Konfiguration mittelskubectl edit managedchart -n fleet-local harvester.