|
Dieses Dokument wurde mithilfe automatisierter maschineller Übersetzungstechnologie übersetzt. Wir bemühen uns um korrekte Übersetzungen, übernehmen jedoch keine Gewähr für die Vollständigkeit, Richtigkeit oder Zuverlässigkeit der übersetzten Inhalte. Im Falle von Abweichungen ist die englische Originalversion maßgebend und stellt den verbindlichen Text dar. |
Upgrade von v1.2.2/v1.3.0 auf v1.3.1
Allgemeine Informationen
Ein Upgrade Button erscheint auf dem Dashboard Bildschirm, wann immer eine neue SUSE Virtualization Version verfügbar ist, auf die Sie upgraden können. Für weitere Informationen siehe Starten eines Upgrades.
Für Air-Gapped-Umgebungen siehe Vorbereiten eines Air-Gapped-Upgrades.
Bekannte Probleme
1. Cluster-Upgrade bleibt nach dem Upgrade des ersten Knotens hängen
|
Um zu verhindern, dass dieses Problem auftritt, kennzeichnen Sie das |
Beim Upgrade eines Harvester-Clusters von v1.2.2 oder v1.3.0 auf v1.3.1 bleibt der Upgrade-Prozess nach dem Upgrade des ersten Knotens hängen.
Beispiel:
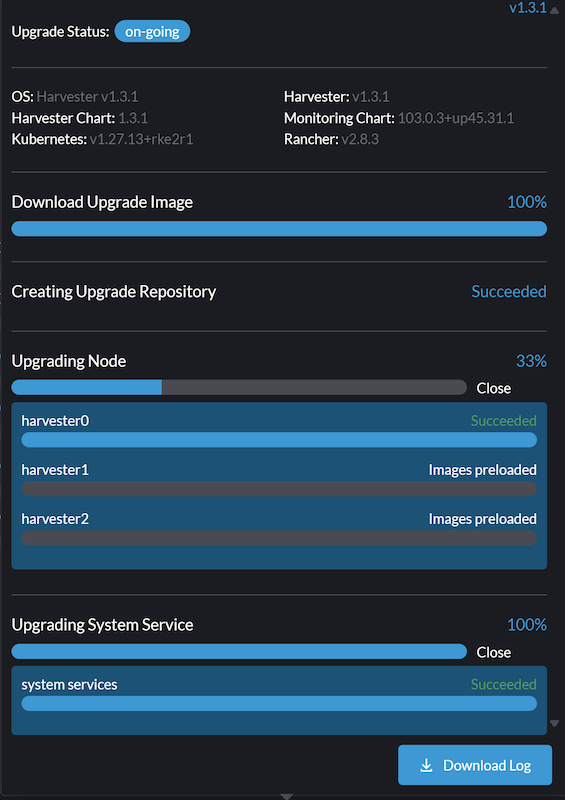
Gehen Sie wie folgt vor, um dieses Problem zu beheben:
-
Überprüfen Sie den Cluster-Status:
kubectl get clusters.provisioning.cattle.io local -n fleet-local -o yamlBeispiel für die Ausgabe:
... - lastUpdateTime: "2024-06-18T23:37:39Z" message: 'configuring bootstrap node(s) custom-9cb22ccf7984: waiting for kubelet to update' reason: Waiting status: Unknown type: Updated - lastUpdateTime: "2024-06-18T23:37:39Z" message: 'configuring bootstrap node(s) custom-9cb22ccf7984: waiting for kubelet to update' reason: Waiting status: Unknown type: ProvisionedWenn die Ausgabe die Nachricht
waiting for kubeletenthält, fahren Sie mit dem nächsten Schritt fort. -
Überprüfen Sie die Protokolle des capi-controller-manager Pods:
kubectl logs -n cattle-provisioning-capi-system deployment/capi-controller-managerWenn die Ausgabe dem folgenden Beispiel ähnelt, besteht das Problem wahrscheinlich im Cluster.
2024-06-19T08:54:22.407423986Z W0619 08:54:22.407257 1 reflector.go:424] k8s.io/client-go@v0.26.1/tools/cache/reflector.go:169: failed to list *v1.Node: Unauthorized 2024-06-19T08:54:22.407470069Z E0619 08:54:22.407283 1 reflector.go:140] k8s.io/client-go@v0.26.1/tools/cache/reflector.go:169: Failed to watch *v1.Node: failed to list *v1.Node: Unauthorized 2024-06-19T08:55:05.153396619Z W0619 08:55:05.153190 1 reflector.go:424] k8s.io/client-go@v0.26.1/tools/cache/reflector.go:169: failed to list *v1.Node: Unauthorized 2024-06-19T08:55:05.153438978Z E0619 08:55:05.153217 1 reflector.go:140] k8s.io/client-go@v0.26.1/tools/cache/reflector.go:169: Failed to watch *v1.Node: failed to list *v1.Node: Unauthorized -
Wenden Sie den folgenden Workaround an, um das Upgrade fortzusetzen:
Beenden und starten Sie den capi-controller-manager Pod neu.
Beispiel:
kubectl rollout restart deployment/capi-controller-manager -n cattle-provisioning-capi-system
Verwandtes Problem: #6041
2. Automatische Bildbereinigung funktioniert nicht
Da das veröffentlichte Harvester-ISO eine unvollständige Bildliste enthält, kann die automatische Bildbereinigung während eines Upgrades von v1.2.2 auf v1.3.1 nicht durchgeführt werden. Dieses Problem blockiert das Upgrade nicht, und Sie können dieses Skript verwenden, um nach Abschluss des Upgrades manuell Container-Images zu bereinigen. Für weitere Informationen siehe Issue #6620.