|
Dieses Dokument wurde mithilfe automatisierter maschineller Übersetzungstechnologie übersetzt. Wir bemühen uns um korrekte Übersetzungen, übernehmen jedoch keine Gewähr für die Vollständigkeit, Richtigkeit oder Zuverlässigkeit der übersetzten Inhalte. Im Falle von Abweichungen ist die englische Originalversion maßgebend und stellt den verbindlichen Text dar. |
Aufrüstungen
SUSE Virtualization führt eine neue Lebenszyklusstrategie ein, die das Versionsmanagement und die Upgrades vereinfacht. Diese Strategie umfasst Folgendes:
-
Viermonatiger Rhythmus für kleinere Releases
-
Zweimonatiger Rhythmus für Patch-Releases
-
Richtlinie zur Übernahme von Komponenten
|
SUSE Virtualization unterstützt keine Downgrades. Diese Einschränkung hilft, unerwartetes Systemverhalten und Probleme im Zusammenhang mit Funktionsinkompatibilität, Auslaufen und Entfernung zu verhindern. |
Upgrade-Möglichkeiten
Die folgende Tabelle skizziert die unterstützten Upgrade-Pfade.
| Installierte Version | Unterstützte Upgrade-Versionen |
|---|---|
v1.6.x |
|
v1.6.x |
v1.6.y (y ist größer als x) |
v1.5.x |
|
v1.5.0 und v1.5.1 |
|
v1.5.0 |
|
v1.4.2 und v1.4.3 |
|
v1.4.2 und v1.4.3 |
|
v1.4.1 und v1.4.2 |
|
v1.4.1 |
|
v1.4.0 |
|
v1.3.1 |
|
v1.2.2 und v1.3.0 |
|
v1.2.1 |
|
v1.1.2, v1.1.3 und v1.2.0 |
Die neuesten SUSE Virtualization-Versionen ermöglichen Folgendes:
-
Upgrade von einer Minor-Version zur nächsten (zum Beispiel von v1.5.2 auf v1.6.1), ohne die dazwischen veröffentlichten Patches installieren zu müssen. Dies ist möglich, weil SUSE Virtualization maximal ein Minor-Version-Upgrade für zugrunde liegende Komponenten erlaubt.
-
Upgrade auf eine spätere Patch-Version (zum Beispiel von v1.6.0 auf v1.6.1), vorausgesetzt, dass die gleichen Komponenten-Versionen in den Releases für eine gegebene Minor-Version verwendet werden.
Die folgende Tabelle zeigt die in diesen Versionen verwendeten Komponenten auf:
| Komponente | SUSE Virtualization v1.5.x | SUSE Virtualization v1.6.x | SUSE Virtualization v1.7.x |
|---|---|---|---|
KubeVirt |
v1.4 |
v1.5 |
v1.6 |
SUSE Storage |
v1.8 |
v1.9 |
v1.10 |
SUSE Rancher Prime |
v2.11 |
v2.12 |
v2.13 |
RKE2 |
v1.32 |
v1.33 |
v1.34 |
SUSE Linux Micro |
5.5 |
5.5 |
6.1 |
|
Das Überspringen mehrerer Kubernetes-Minor-Versionen wird Upstream nicht unterstützt und ist ein wesentlicher Grund für die begrenzten Upgrade-Pfade. Für weitere Informationen siehe Version Skew Policy in der Kubernetes-Dokumentation. |
Rancher Upgrade
Wenn Sie Rancher verwenden, um Ihren SUSE Virtualization Cluster zu verwalten, müssen Sie Upgrade Rancher vor dem Upgrade von SUSE Virtualization.
|
Die Upgrade-Prozesse von SUSE Virtualization und Rancher sind unabhängig voneinander. Während eines Rancher Upgrades können Sie weiterhin auf Ihren SUSE Virtualization Cluster über seine virtuelle IP zugreifen. SUSE Virtualization wird nicht automatisch aktualisiert. |
Wenn eine Rancher Version ihr End of Maintenance (EOM) Datum erreicht, bietet SUSE Virtualization nur Fixes für kritische sicherheitsrelevante Probleme, die die Integrationsfunktionen (Virtualisierungsmanagement) betreffen. Für weitere Informationen siehe die Support Matrix.
Virtuelle Maschinenverwaltung durch das Upgrade
Live-migrierbare virtuelle Maschinen
Live-migrierbare virtuelle Maschinen werden automatisch vor dem Upgrade des aktuellen Knotens über Batch-Migration auf andere Knoten migriert. Diese virtuellen Maschinen haben während der Migration keine Ausfallzeit.
Nicht-migrierbare virtuelle Maschinen
Wenn ein Upgrade ausgelöst wird, führt SUSE Virtualization bestimmte Aktionen abhängig vom Wert der upgrade-config Einstellung und der restoreVM Option aus.
-
false: SUSE Virtualization führt das Upgrade nicht durch, wenn nicht-migrierbare virtuelle Maschinen noch laufen. Sie müssen die virtuellen Maschinen manuell ausschalten. -
true: SUSE Virtualization schaltet nicht migrierbare virtuelle Maschinen automatisch aus, wenn der Knoten aktualisiert wird, und stellt sie nach dem Neustart des Knotens wieder her.
|
Nicht migrierbare virtuelle Maschinen haben während der Migration Ausfallzeit. |
Weitere Informationen finden Sie in Phase 4: Knoten aktualisieren.
Bevor Sie ein Upgrade starten
Überprüfen Sie die verfügbare upgrade-config Einstellung, um die Upgrade-Strategien und das Verhalten anzupassen, die am besten zu Ihrer Cluster-Umgebung passen.
Ein Upgrade starten
|
|
|
NICs, die mit einem PCI-Bridge verbunden sind, könnten nach einem Upgrade umbenannt werden. Bitte überprüfen Sie den Artikel in der Wissensdatenbank für weitere Informationen. |
|
Beginnend mit v1.7.0 verwendet SUSE Virtualization ein implementierungsbasiertes Upgrade-Repository anstelle eines virtuellen Maschinen-basierten Ansatzes, um die Leistung und Zuverlässigkeit zu verbessern. Für weitere Informationen siehe Problem #7101. |
-
Klicken Sie im SUSE Virtualization UI Dashboard Bildschirm auf Upgrade.
Die Upgrade Schaltfläche erscheint, wann immer eine neue Version, auf die Sie upgraden können, verfügbar wird.
Wenn Ihre Umgebung keinen direkten Internetzugang hat, folgen Sie den Anweisungen in [Prepare an air-gapped upgrade], die einen effizienten Ansatz zum Herunterladen der ISO bieten.
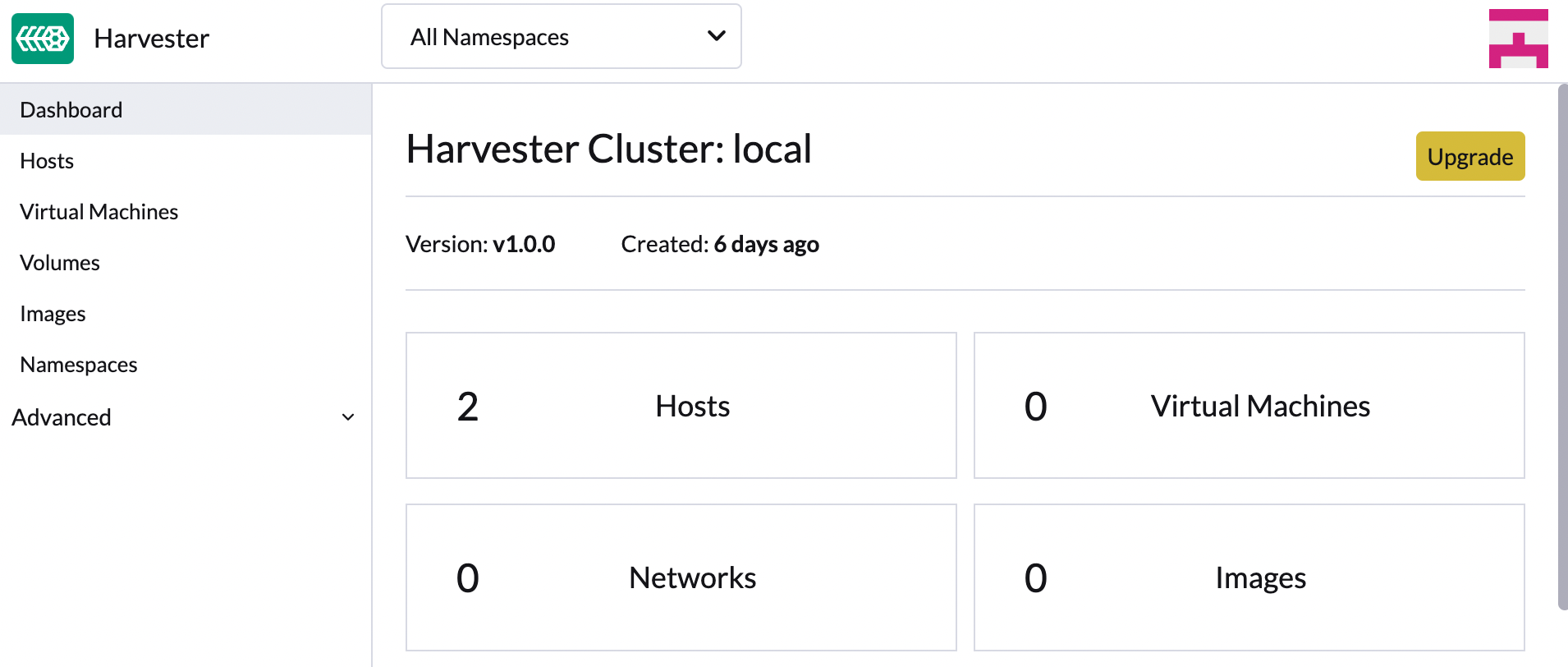
-
Wählen Sie die Version aus, auf die Sie upgraden möchten.
Wenn Sie Anpassungen benötigen, siehe [Customize the version].
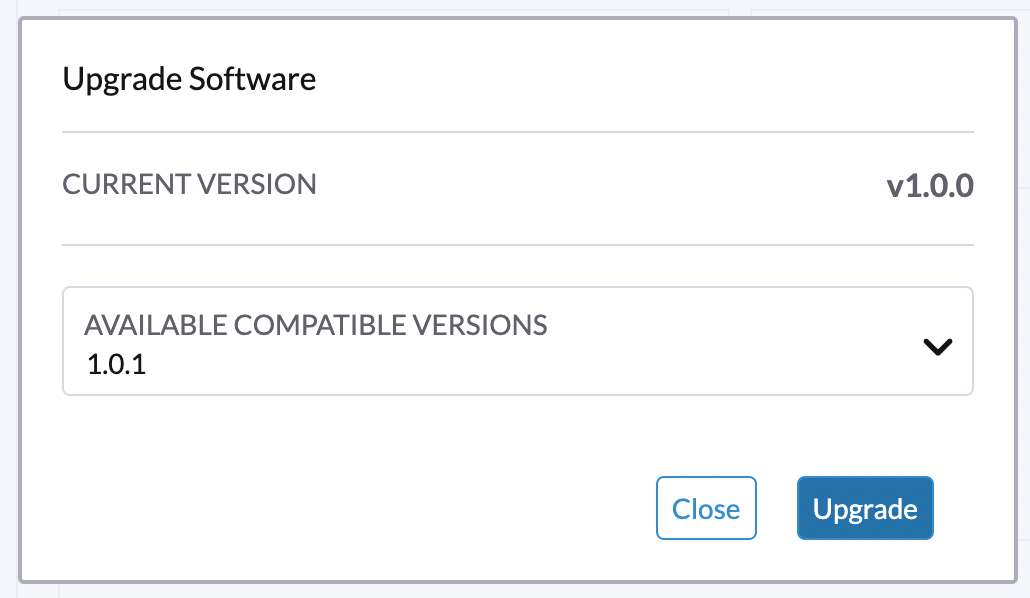
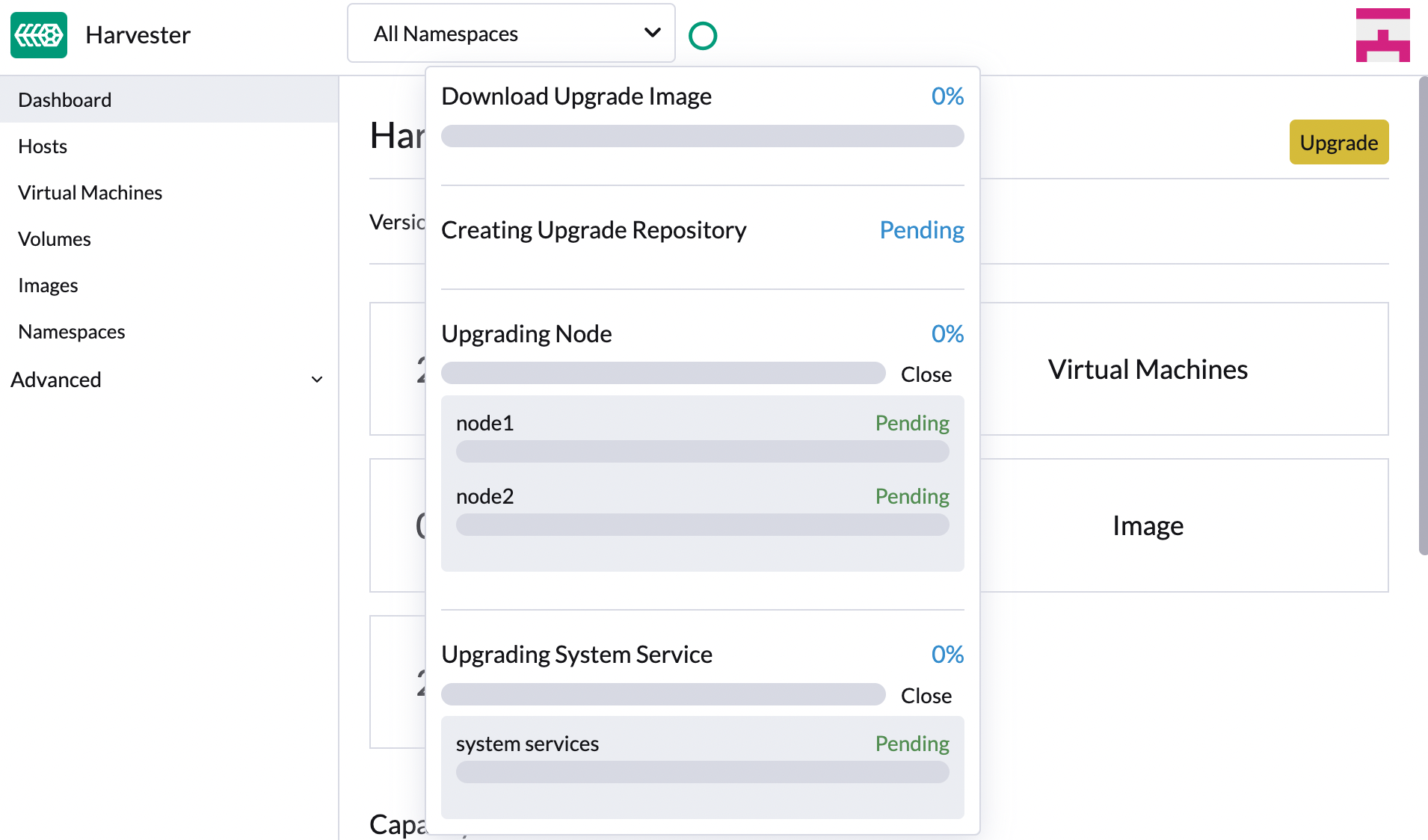
-
Klicken Sie auf den Fortschrittsindikator (kreisförmiges Symbol), um den Status jedes verwandten Prozesses anzuzeigen.
Passen Sie die Version an
-
Laden Sie die Versionsdatei (
https://releases.rancher.com/harvester/{version}/version.yaml) herunter.Beispiel:
Die Versionsdatei v1.5.0 wird als
v1.5.0.yamlheruntergeladen.apiVersion: harvesterhci.io/v1beta1 kind: Version metadata: name: v1.5.0-customized # Changed, to avoid duplicated with the official version name namespace: harvester-system spec: isoChecksum: 'df28e9bf8dc561c5c26dee535046117906581296d633eb2988e4f68390a281b6856a5a0bd2e4b5b988c695a53d0fc86e4e3965f19957682b74317109b1d2fe32' # Don't change isoURL: https://releases.rancher.com/harvester/v1.5.0/harvester-v1.5.0-amd64.iso # Official ISO path by default releaseDate: '20250425' -
Erstellen Sie die Version mit dem Befehl
kubectl create -f v1.5.0.yaml.
Bereiten Sie ein Air-Gapped-Upgrade vor.
|
Stellen Sie sicher, dass Sie zuerst den Abschnitt [Upgrade paths] über Upgrade-Versionen überprüfen. |
Bereiten Sie die ISO-Datei vor.
-
Laden Sie eine ISO-Datei von der Releases Seite herunter.
-
Speichern Sie die ISO auf einem lokalen HTTP-Server.
Gehen Sie davon aus, dass die Datei unter
http://10.10.0.1/harvester.isogehostet wird.
Bereiten Sie die Version vor
-
Laden Sie die Versionsdatei (
https://releases.rancher.com/harvester/{version}/version.yaml) herunter. -
Ersetzen Sie den
isoURLWert in der Datei.apiVersion: harvesterhci.io/v1beta1 kind: Version metadata: name: v1.5.0 namespace: harvester-system spec: isoChecksum: <SHA-512 checksum of the ISO> isoURL: http://10.10.0.1/harvester.iso # change to local ISO URL releaseDate: '20250425'Gehen Sie davon aus, dass die Datei unter
http://10.10.0.1/version.yamlgehostet wird. Wenn Sie Anpassungen benötigen, siehe [Customize the version]. -
Greifen Sie über SSH auf einen der Steuerungsknoten zu und melden Sie sich mit dem Root-Konto an.
-
Erstellen Sie ein Versionsobjekt.
rancher@node1:~> sudo -i rancher@node1:~> kubectl create -f http://10.10.0.1/version.yaml
Starten Sie manuell ein Upgrade, bevor das offizielle Upgrade verfügbar wird
Die Upgrade-Schaltfläche erscheint nicht sofort nach der Veröffentlichung einer neuen Version in der Benutzeroberfläche. Wenn Sie Ihr Cluster upgraden möchten, bevor die Option in der Benutzeroberfläche verfügbar wird, folgen Sie den Schritten in [Prepare an air-gapped upgrade].
|
In Produktionsumgebungen wird empfohlen, Cluster über die Benutzeroberfläche zu upgraden. |
Passen Sie die Knoten-Upgrades an
SUSE Virtualization Upgrades umfassen mehrere definierte Phasen. Eine wichtige Phase sind die Knoten-Upgrades, während der das Betriebssystem und die zugrunde liegende Kubernetes-Distribution (RKE2) nacheinander und autonom auf jedem Knoten aktualisiert werden.
Sie haben die Möglichkeit, automatische Upgrades auf bestimmten Knoten zu pausieren, was nützlich für manuelle Wartungs- oder Verifizierungsaufgaben ist. Nach Abschluss dieser Aufgaben müssen Sie SUSE Virtualization ausdrücklich anweisen, das Upgrade auf den Zielknoten fortzusetzen.
Pausieren von Knoten-Upgrades
Sie können die nodeUpgradeOption Option in der upgrade-config Einstellung verwenden, um Knoten-Upgrades zu pausieren.
-
Pause für alle Knoten im Cluster: Ändern Sie den Wert des
modeFeldes aufmanual. -
Pause für bestimmte Knoten: Listen Sie die Knotennamen im
pauseNodesFeld auf. Knoten, die nicht in der Liste enthalten sind, werden automatisch upgegradet.
|
SUSE Virtualization wendet die |
|
Sie können die |
Die SUSE Virtualization Benutzeroberfläche bietet visuelle Bestätigung für pausierte Knoten-Upgrades. Im folgenden Beispiel ist das Upgrade des Knotens charlie-1-tink-system derzeit pausiert.
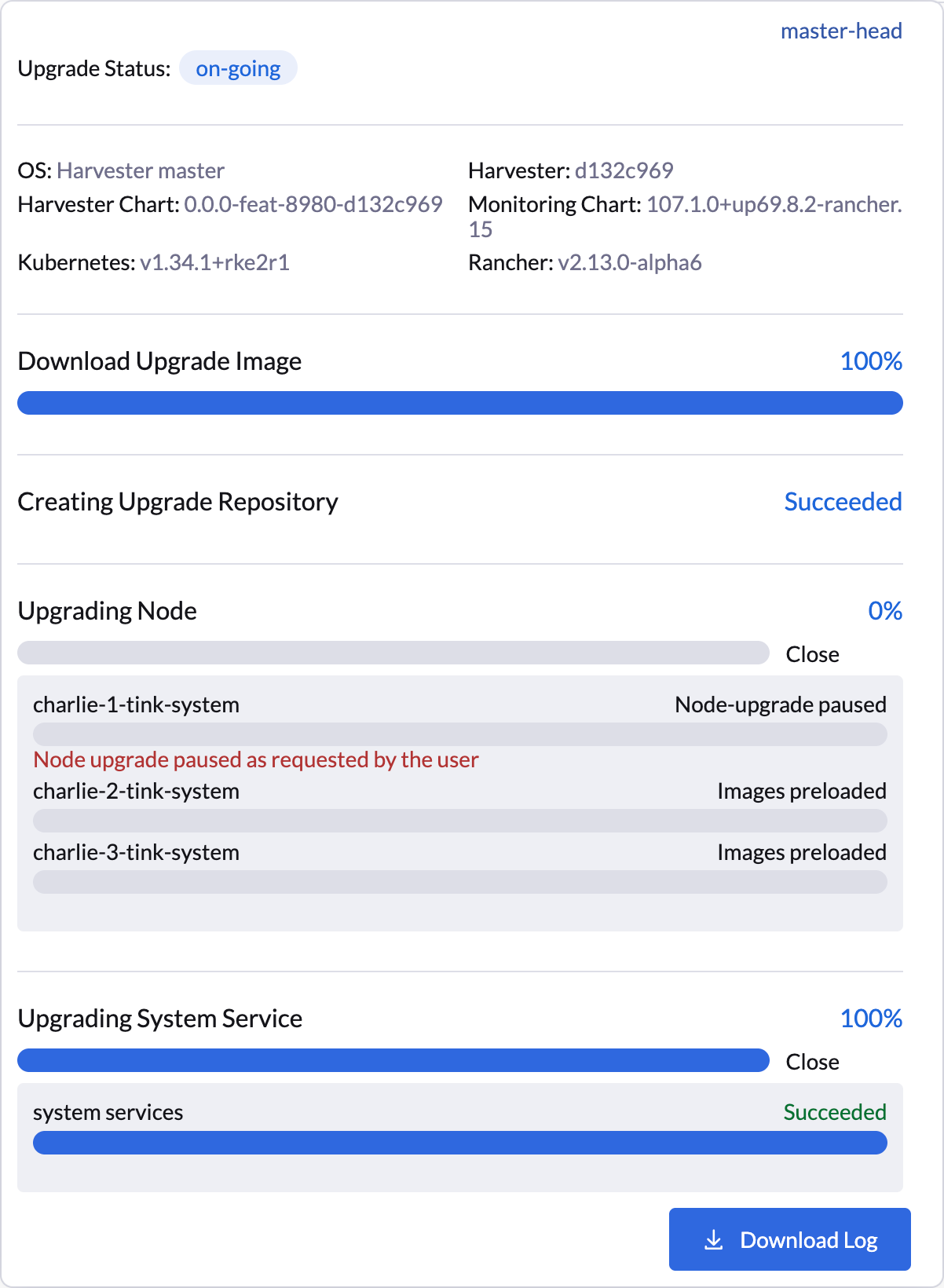
Sie können auch den folgenden kubectl Befehl verwenden, um nach pausierten Knoten-Upgrades zu suchen.
$ kubectl -n harvester-system get upgrades -l harvesterhci.io/latestUpgrade=true -o yaml
...
annotations:
harvesterhci.io/node-upgrade-pause-map: '{"charlie-1-tink-system":"pause","charlie-2-tink-system":"pause","charlie-3-tink-system":"pause"}'
...
nodeStatuses:
charlie-1-tink-system:
message: Node upgrade paused as requested by the user
reason: AdministrativelyPaused
state: Node-upgrade paused
charlie-2-tink-system:
state: Images preloaded
charlie-3-tink-system:
state: Images preloaded
...|
Die Pre-Drain-Jobs für Knoten mit pausierten Upgrades wurden nicht erstellt. Diese Knoten sind jedoch weiterhin abgeriegelt, und Sie können keine neuen Arbeitslasten auf ihnen ausführen. Nur Wartungsaufgaben, wie das manuelle Herunterfahren von virtuellen Maschinen, sollten auf Knoten mit pausierten Upgrades durchgeführt werden. |
Fortsetzen eines pausierten Knoten-Upgrades
Sie können ein pausiertes Knoten-Upgrade fortsetzen, indem Sie die harvesterhci.io/node-upgrade-pause-map Annotation auf der Upgrade benutzerdefinierten Ressource aktualisieren.
Beispiel:
# Find out the latest Upgrade custom resource
$ kubectl -n harvester-system get upgrades -l harvesterhci.io/latestUpgrade=true
NAME AGE
hvst-upgrade-6mcwv 4h16m
# Update the annotation to unpause the node
$ kubectl -n harvester-system annotate --overwrite upgrades hvst-upgrade-6mcwv harvesterhci.io/node-upgrade-pause-map='{"charlie-1-tink-system":"unpause","charlie-2-tink-system":"pause","charlie-3-tink-system":"pause"}'Sobald der Zielknoten im Upgrade benutzerdefinierten Ressource annotiert ist, setzt SUSE Virtualization das Upgrade sofort fort, wobei die Benutzeroberfläche visuelle Fortschrittsaktualisierungen anzeigt.
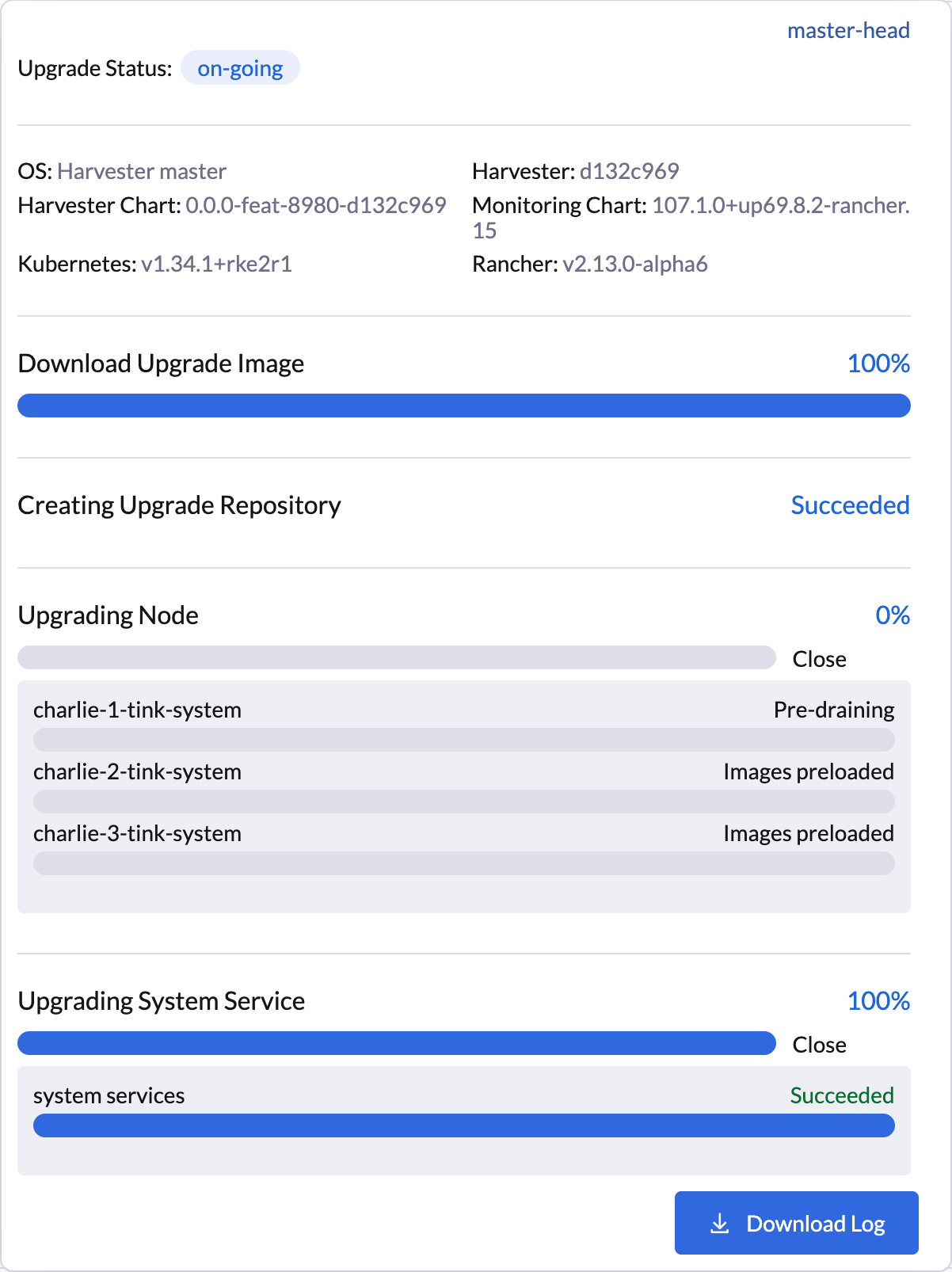
Sie können auch den folgenden kubectl Befehl verwenden, um den Status des Zielknotens zu überprüfen:
$ kubectl -n harvester-system get upgrades -l harvesterhci.io/latestUpgrade=true -o yaml
...
annotations:
harvesterhci.io/node-upgrade-pause-map: '{"charlie-1-tink-system":"unpause","charlie-2-tink-system":"pause","charlie-3-tink-system":"pause"}'
...
nodeStatuses:
charlie-1-tink-system:
state: Pre-draining
charlie-2-tink-system:
state: Images preloaded
charlie-3-tink-system:
state: Images preloaded
...Je nach Anzahl der Zielknoten müssen Sie die Unpause-Operation möglicherweise während des gesamten Cluster-Upgrade-Prozesses mehrmals ausführen.
Anforderung an den freien Speicherplatz der Systempartition
SUSE Virtualization lädt während der Upgrades Bilder auf jedem Knoten. Wenn die Speichernutzung die Schwelle für die Müllabfuhr des Kubelets überschreitet, löscht das Kubelet ungenutzte Bilder, um Speicherplatz freizugeben. Dies kann in Air-Gapped-Umgebungen Probleme verursachen, da die Bilder auf dem Knoten nicht verfügbar sind.
SUSE Virtualization enthält Überprüfungen, die sicherstellen, dass Knoten nach dem Laden neuer Bilder keine Müllabfuhr auslösen.
Wenn der Speicherplatz nicht ausreicht, blockiert SUSE Virtualization das Upgrade und gibt einen Fehler zurück, der dem folgenden ähnlich ist:
Node "harvester-node-0" will reach 92.84% storage space after loading new images. It's higher than kubelet image garbage collection threshold 85%.Wenn Sie das Upgrade versuchen möchten, auch wenn der freie Speicherplatz der Systempartition auf einigen Knoten unzureichend ist, können Sie die harvesterhci.io/skipGarbageCollectionThresholdCheck: true Annotation des Upgrade Objekts aktualisieren.
apiVersion: harvesterhci.io/v1beta1
kind: Upgrade
metadata:
annotations:
harvesterhci.io/skipGarbageCollectionThresholdCheck: true
generateName: hvst-upgrade-
namespace: harvester-system
spec:
version: "1.6.0"
logEnabled: true|
Einen kleineren Wert als den vordefinierten Wert festzulegen, kann dazu führen, dass das Upgrade fehlschlägt und wird in einer Produktionsumgebung nicht empfohlen. |
Die folgenden Abschnitte beschreiben Lösungen für Probleme, die mit dieser Anforderung zusammenhängen.
Manuell freien Speicherplatz der Systempartition
SUSE Virtualization versucht, unnötige Containerbilder nach Abschluss eines Upgrades zu entfernen. Diese automatische Bildbereinigung kann jedoch aus verschiedenen Gründen möglicherweise nicht durchgeführt werden. Sie können ein Skript verwenden, um Bilder manuell zu entfernen. Für weitere Informationen siehe das Problem #6620.
Richten Sie eine private Container-Registry ein und überspringen Sie das Vorladen von Bildern.
Die Systempartition könnte weiterhin an freiem Speicherplatz mangeln, selbst nachdem Sie Bilder entfernt haben. Um dies zu adressieren, richten Sie eine private Container-Registry für aktuelle und neue Images ein und konfigurieren Sie die Einstellung upgrade-config mit folgendem Wert:
{"imagePreloadOption":{"strategy":{"type":"skip"}}, "restoreVM": false}SUSE Virtualization überspringt den Prozess des Vorladens des Upgrade-Images. Wenn die Implementierungen auf den Knoten geupgradet werden, lädt die Container-Laufzeit die in der privaten Container-Registry gespeicherten Images.
|
Verlassen Sie sich nicht auf die öffentliche Container-Registry. Beachten Sie mögliche Unterbrechungen des Internetdienstes und wie nah Sie daran sind, Ihr Docker Hub Rate Limit zu erreichen. Das Fehlschlagen beim Herunterladen eines der erforderlichen Images kann dazu führen, dass das Upgrade fehlschlägt und den Cluster in einem Zwischenzustand zurücklässt. |
Überprüfung des Ablaufdatums von Zertifikaten
SUSE Virtualization überprüft den Gültigkeitszeitraum von Zertifikaten auf jedem Knoten. Diese Überprüfung schließt die Möglichkeit aus, dass Zertifikate während des laufenden Upgrades ablaufen. Wenn ein Zertifikat innerhalb von 7 Tagen abläuft, wird ein Fehler zurückgegeben. Dieses Verhalten kann durch Setzen der harvesterhci.io/minCertsExpirationInDay Annotation überschrieben werden.
Beispiel:
apiVersion: harvesterhci.io/v1beta1
kind: Upgrade
metadata:
annotations:
harvesterhci.io/minCertsExpirationInDay: "14"
generateName: hvst-upgrade-
namespace: harvester-system
spec:
version: "1.6.0"
logEnabled: trueWenn diese Annotation zum Upgrade Objekt hinzugefügt wird, gibt SUSE Virtualization einen Fehler zurück, wenn es ein Zertifikat erkennt, das innerhalb von 14 Tagen abläuft.
Für weitere Informationen siehe auto-rotate-rke2-certs.
Kompatibilität von virtuellen Maschinen-Backups
Sie können auf bestimmte Einschränkungen stoßen, wenn Sie Backups erstellen und wiederherstellen, die externen Speicher betreffen.
Longhorn Manager Abstürze aufgrund der Auslagerung von Backing-Images
|
Beim Upgrade auf SUSE Virtualization v1.4.x kann der Longhorn Manager abstürzen, wenn das Um zu verhindern, dass das Problem auftritt, stellen Sie sicher, dass das |
Reaktivieren Sie die RKE2 ingress-nginx Zulassungs-Webhooks (CVE-2025-1974)
Wenn Sie die RKE2 ingress-nginx admission webhooks deaktiviert haben, um CVE-2025-1974 zu mildern, müssen Sie den Webhook nach dem Upgrade auf SUSE Virtualization v1.5.0 oder höher wieder aktivieren.
-
Überprüfen Sie, ob SUSE Virtualization nginx-ingress v1.12.1 oder höher verwendet.
$ kubectl -n kube-system get po -l"app.kubernetes.io/name=rke2-ingress-nginx" -ojsonpath='{.items[].spec.containers[].image}' rancher/nginx-ingress-controller:v1.12.1-hardened1 -
Führen Sie
kubectl -n kube-system edit helmchartconfig rke2-ingress-nginxaus, um zu entfernen die folgenden Konfigurationen aus derHelmChartConfigRessource.-
.spec.valuesContent.controller.admissionWebhooks.enabled: false -
.spec.valuesContent.controller.extraArgs.enable-annotation-validation: true
-
-
Überprüfen Sie, ob die neue
.spec.ValuesContentKonfiguration ähnlich dem folgenden Beispiel ist.apiVersion: helm.cattle.io/v1 kind: HelmChartConfig metadata: name: rke2-ingress-nginx namespace: kube-system spec: valuesContent: |- controller: admissionWebhooks: port: 8444 extraArgs: default-ssl-certificate: cattle-system/tls-rancher-internal config: proxy-body-size: "0" proxy-request-buffering: "off" publishService: pathOverride: kube-system/ingress-exposeWenn die
HelmChartConfigRessource andere benutzerdefinierteingress-nginxKonfigurationen enthält, müssen Sie diese beim Bearbeiten der Ressource beibehalten. -
Beenden Sie die Ausführung des
kubectl editBefehls, um die Konfiguration zu speichern.SUSE Virtualization wendet die Änderung automatisch an, sobald der Inhalt gespeichert ist.
-
Überprüfen Sie, ob die
rke2-ingress-nginx-admissionWebhook-Konfiguration wieder aktiviert ist.$ kubectl get validatingwebhookconfiguration rke2-ingress-nginx-admission NAME WEBHOOKS AGE rke2-ingress-nginx-admission 1 6s -
Überprüfen Sie, ob die
ingress-nginxPods erfolgreich neu gestartet wurden.kubectl -n kube-system get po -lapp.kubernetes.io/instance=rke2-ingress-nginx NAME READY STATUS RESTARTS AGE rke2-ingress-nginx-controller-l2cxz 1/1 Running 0 94s
Das Upgrade steckt im Zustand "Pre-drained" fest.
Der Upgrade-Prozess kann im Zustand "Pre-drained" stecken bleiben. Kubernetes soll die Arbeitslast auf dem Knoten entleeren, aber einige Faktoren können den Prozess zum Stillstand bringen.
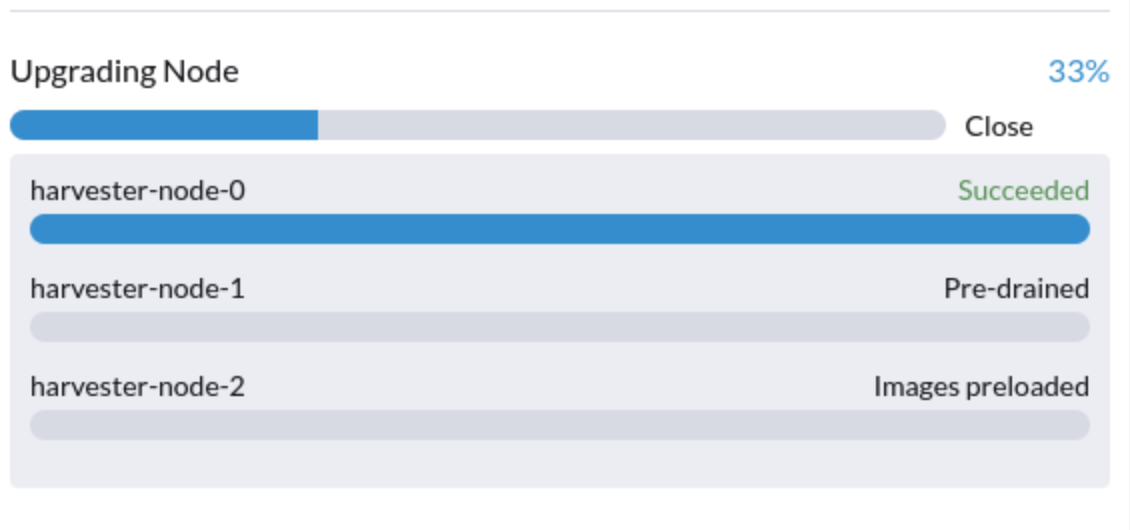
Ein möglicher Grund sind Prozesse, die mit verwaisten Engines des Longhorn Instance Managers verbunden sind. Um festzustellen, ob dies auf Ihre Situation zutrifft, führen Sie die folgenden Schritte aus:
-
Überprüfen Sie den Namen des
instance-managerPods auf dem feststeckenden Knoten.Beispiel:
Der feststeckende Knoten ist
harvester-node-1, und der Name des Instance Manager Pod istinstance-manager-d80e13f520e7b952f4b7593fc1883e2a.$ kubectl get pods -n longhorn-system --field-selector spec.nodeName=harvester-node-1 | grep instance-manager instance-manager-d80e13f520e7b952f4b7593fc1883e2a 1/1 Running 0 3d8h -
Überprüfen Sie die Protokolle des Longhorn Managers auf Informationsnachrichten.
Beispiel:
$ kubectl -n longhorn-system logs daemonsets/longhorn-manager ... time="2025-01-14T00:00:01Z" level=info msg="Node instance-manager-d80e13f520e7b952f4b7593fc1883e2a is marked unschedulable but removing harvester-node-1 PDB is blocked: some volumes are still attached InstanceEngines count 1 pvc-9ae0e9a5-a630-4f0c-98cc-b14893c74f9e-e-0" func="controller.(*InstanceManagerController).syncInstanceManagerPDB" file="instance_manager_controller.go:823" controller=longhorn-instance-manager node=harvester-node-1Der
instance-managerPod kann nicht entleert werden, weil die Enginepvc-9ae0e9a5-a630-4f0c-98cc-b14893c74f9e-e-0vorhanden ist. -
Überprüfen Sie, ob die Engine noch auf dem feststeckenden Knoten läuft.
Beispiel:
$ kubectl -n longhorn-system get engines.longhorn.io pvc-9ae0e9a5-a630-4f0c-98cc-b14893c74f9e-e-0 -o jsonpath='{"Current state: "}{.status.currentState}{"\nNode ID: "}{.spec.nodeID}{"\n"}' Current state: stopped Node ID:Das Problem besteht wahrscheinlich, wenn die Ausgabe zeigt, dass die Engine entweder nicht läuft oder nicht gefunden wurde.
-
Überprüfen Sie, ob alle Volumes gesund sind.
kubectl get volumes -n longhorn-system -o yaml | yq '.items[] | select(.status.state == "attached")| .status.robustness'Alle Volumes müssen mit
healthygekennzeichnet sein. Wenn dies nicht der Fall ist, melden Sie das Problem. -
Entfernen Sie das PodDisruptionBudget (PDB) des
instance-managerPods.Beispiel:
kubectl delete pdb instance-manager-d80e13f520e7b952f4b7593fc1883e2a -n longhorn-system
Verwandte Probleme:
Fehlgeschlagene Live-Migration im Zustand "Pre-drained"
Die Live-Migration von virtuellen Maschinen kann fehlschlagen, wenn der aktualisierende Knoten während des Vorentleerungszustands abgeriegelt ist. Eine häufige Ursache ist das Fehlen kompatibler Zielknoten aufgrund strenger Anti-Affinitätsregeln.
Wenn dies geschieht, fährt SUSE Virtualization diese virtuellen Maschinen automatisch herunter, um das Upgrade freizugeben und zu verhindern, dass der Prozess unsicher neu gestartet wird.
Wiederkehrende SUSE Storage Snapshots und Backups werden nicht unterstützt
Wiederkehrende SUSE Storage Snapshots und Backups sind nicht in SUSE Virtualization integriert. Wenn Sie sich entscheiden, diese Funktion zu nutzen, müssen Sie alle wiederkehrenden Snapshot- und Backup-Jobs in SUSE Storage deaktivieren, bevor Sie das Upgrade starten.
Für weitere Informationen zur Inkompatibilität siehe Geplante virtuelle Maschinen-Backups und Snapshots.