|
Dieses Dokument wurde mithilfe automatisierter maschineller Übersetzungstechnologie übersetzt. Wir bemühen uns um korrekte Übersetzungen, übernehmen jedoch keine Gewähr für die Vollständigkeit, Richtigkeit oder Zuverlässigkeit der übersetzten Inhalte. Im Falle von Abweichungen ist die englische Originalversion maßgebend und stellt den verbindlichen Text dar. |
Upgrade von v1.4.0 auf v1.4.1
Allgemeine Informationen
Ein Upgrade Button erscheint auf dem Dashboard Bildschirm, wann immer eine neue SUSE Virtualization Version verfügbar wird, auf die Sie upgraden können. Für weitere Informationen siehe Starte ein Upgrade.
Für Air-Gapped-Umgebungen siehe Bereite ein Air-Gapped-Upgrade vor.
|
Überprüfen Sie den Speicherplatzverbrauch der Betriebssystem-Images auf jedem Knoten, bevor Sie das Upgrade starten. Um dies zu tun, greifen Sie über SSH auf den Knoten zu und führen Sie den Befehl Beispiel: Wenn
|
Aktualisieren Sie die Harvester UI-Erweiterung auf SUSE Rancher Prime v2.10.1
Sie müssen v1.0.3 der Harvester UI-Erweiterung verwenden, um SUSE Virtualization v1.4.1-Cluster auf Rancher v2.10.1 zu importieren.
-
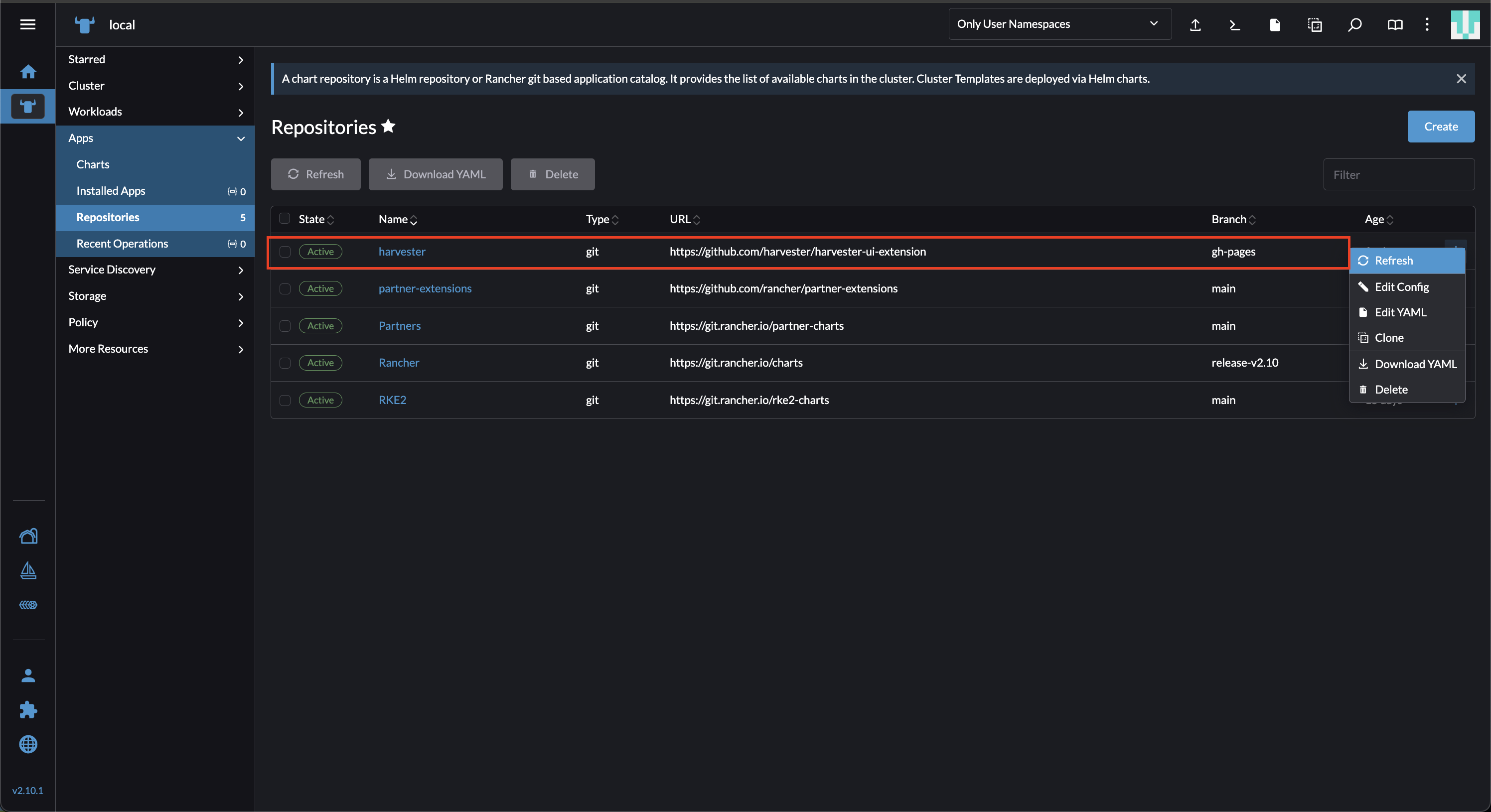
Gehen Sie in der Rancher UI zu lokalen → Apps → Repositories.
-
Suchen Sie das Repository mit dem Namen harvester und wählen Sie dann ⋮ → Aktualisieren aus.
Dieses Repository hat die folgenden Eigenschaften:
-
Branch: gh-pages
-
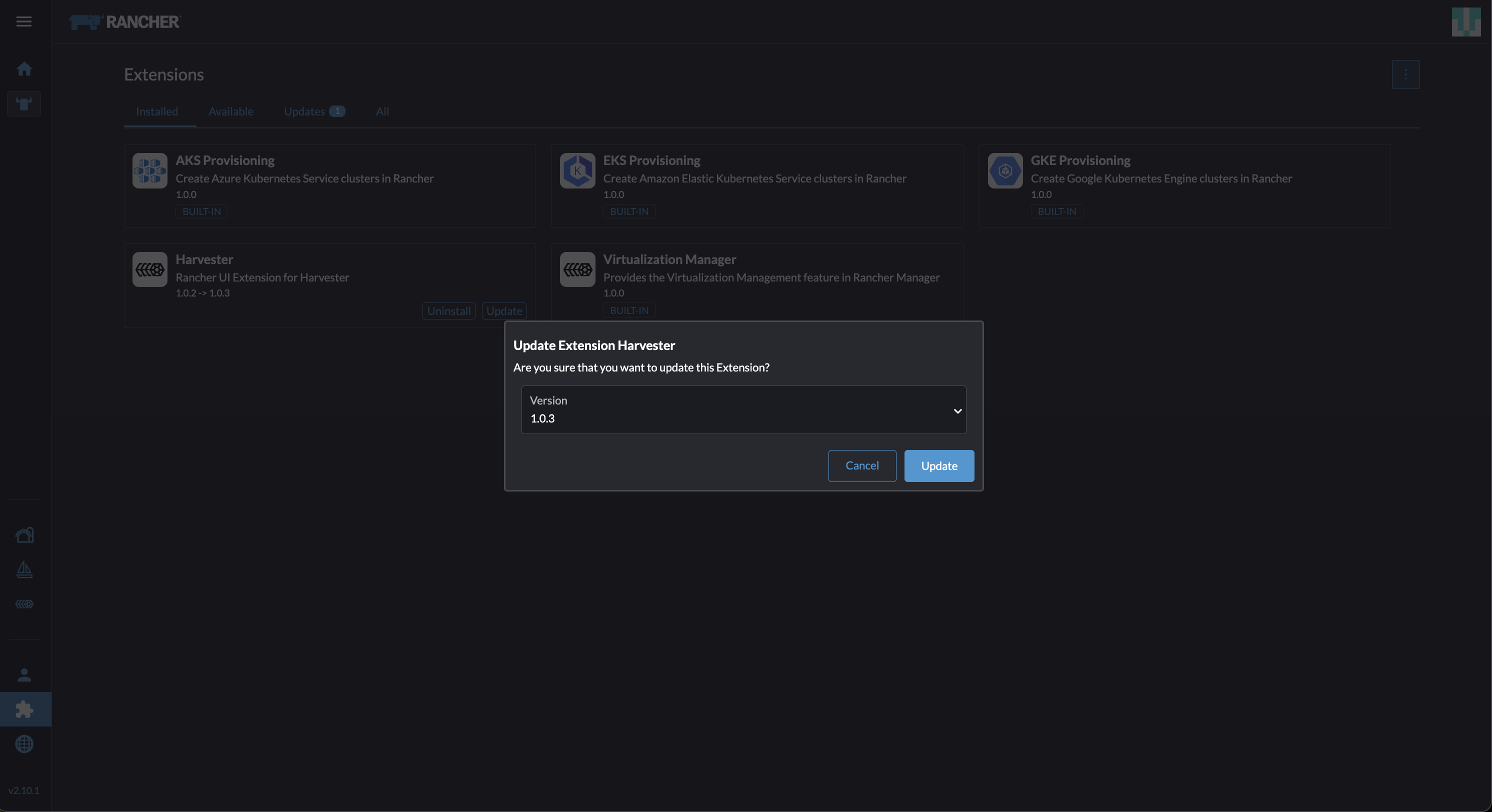
Gehen Sie zum Erweiterungen-Bildschirm.
-
Suchen Sie die Erweiterung mit dem Namen Harvester und klicken Sie dann auf Aktualisieren.
-
Wählen Sie die Version 1.0.3 aus und klicken Sie dann auf Aktualisieren.
-
Lassen Sie etwas Zeit, damit die Erweiterung aktualisiert wird, und aktualisieren Sie dann den Bildschirm.
|
Die Rancher Benutzeroberfläche zeigt eine Fehlermeldung an, nachdem die Erweiterung aktualisiert wurde. Die Fehlermeldung verschwindet, wenn Sie den Bildschirm aktualisieren. Dieses Problem, das in Rancher v2.10.0 und v2.10.1 besteht, wird in v2.10.2 behoben. |
Bekannte Probleme
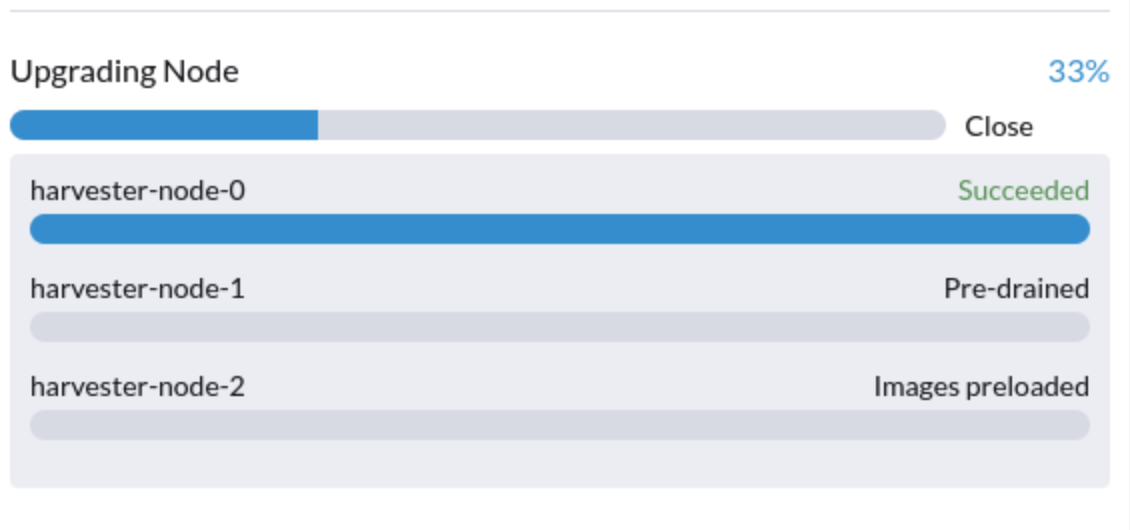
1. Upgrade bleibt im Status "Vorentleert" hängen.
Der Upgrade-Prozess kann im Status "Vorentleert" stecken bleiben. Kubernetes soll die Arbeitslast auf dem Knoten räumen, aber einige Faktoren können den Prozess zum Stillstand bringen.
Eine mögliche Ursache sind Prozesse, die mit verwaisten Engines des Longhorn Instance Managers verbunden sind. Um festzustellen, ob dies auf Ihre Situation zutrifft, führen Sie die folgenden Schritte aus:
-
Überprüfen Sie den Namen des
instance-managerPods auf dem hängenden Knoten.Beispiel:
Der hängende Knoten ist
harvester-node-1, und der Name des Instance Manager Pods istinstance-manager-d80e13f520e7b952f4b7593fc1883e2a.$ kubectl get pods -n longhorn-system --field-selector spec.nodeName=harvester-node-1 | grep instance-manager instance-manager-d80e13f520e7b952f4b7593fc1883e2a 1/1 Running 0 3d8h -
Überprüfen Sie die Protokolle des Longhorn Managers auf Informationsmeldungen.
Beispiel:
$ kubectl -n longhorn-system logs daemonsets/longhorn-manager ... time="2025-01-14T00:00:01Z" level=info msg="Node instance-manager-d80e13f520e7b952f4b7593fc1883e2a is marked unschedulable but removing harvester-node-1 PDB is blocked: some volumes are still attached InstanceEngines count 1 pvc-9ae0e9a5-a630-4f0c-98cc-b14893c74f9e-e-0" func="controller.(*InstanceManagerController).syncInstanceManagerPDB" file="instance_manager_controller.go:823" controller=longhorn-instance-manager node=harvester-node-1Der
instance-managerPod kann nicht entleert werden, weil die Enginepvc-9ae0e9a5-a630-4f0c-98cc-b14893c74f9e-e-0noch aktiv ist. -
Überprüfen Sie, ob die Engine noch auf dem hängenden Knoten läuft.
Beispiel:
$ kubectl -n longhorn-system get engines.longhorn.io pvc-9ae0e9a5-a630-4f0c-98cc-b14893c74f9e-e-0 -o jsonpath='{"Current state: "}{.status.currentState}{"\nNode ID: "}{.spec.nodeID}{"\n"}' Current state: stopped Node ID:Das Problem besteht wahrscheinlich, wenn die Ausgabe zeigt, dass die Engine entweder nicht läuft oder nicht gefunden wird.
-
Überprüfen Sie, ob alle Volumes gesund sind.
kubectl get volumes -n longhorn-system -o yaml | yq '.items[] | select(.status.state == "attached")| .status.robustness'Alle Volumes müssen als
healthymarkiert sein. Wenn dies nicht der Fall ist, melden Sie das Problem. -
Entfernen Sie das PodDisruptionBudget (PDB) des
instance-managerPods.Beispiel:
kubectl delete pdb instance-manager-d80e13f520e7b952f4b7593fc1883e2a -n longhorn-system
2. Upgrade mit der Standard-StorageClass, die nicht harvester-longhorn ist.
Der Harvester fügt die Annotation storageclass.kubernetes.io/is-default-class: "true" zu harvester-longhorn hinzu, welche die ursprüngliche Standard-StorageClass ist. Wenn Sie harvester-longhorn durch eine andere StorageClass ersetzen, treten folgende Ereignisse auf:
-
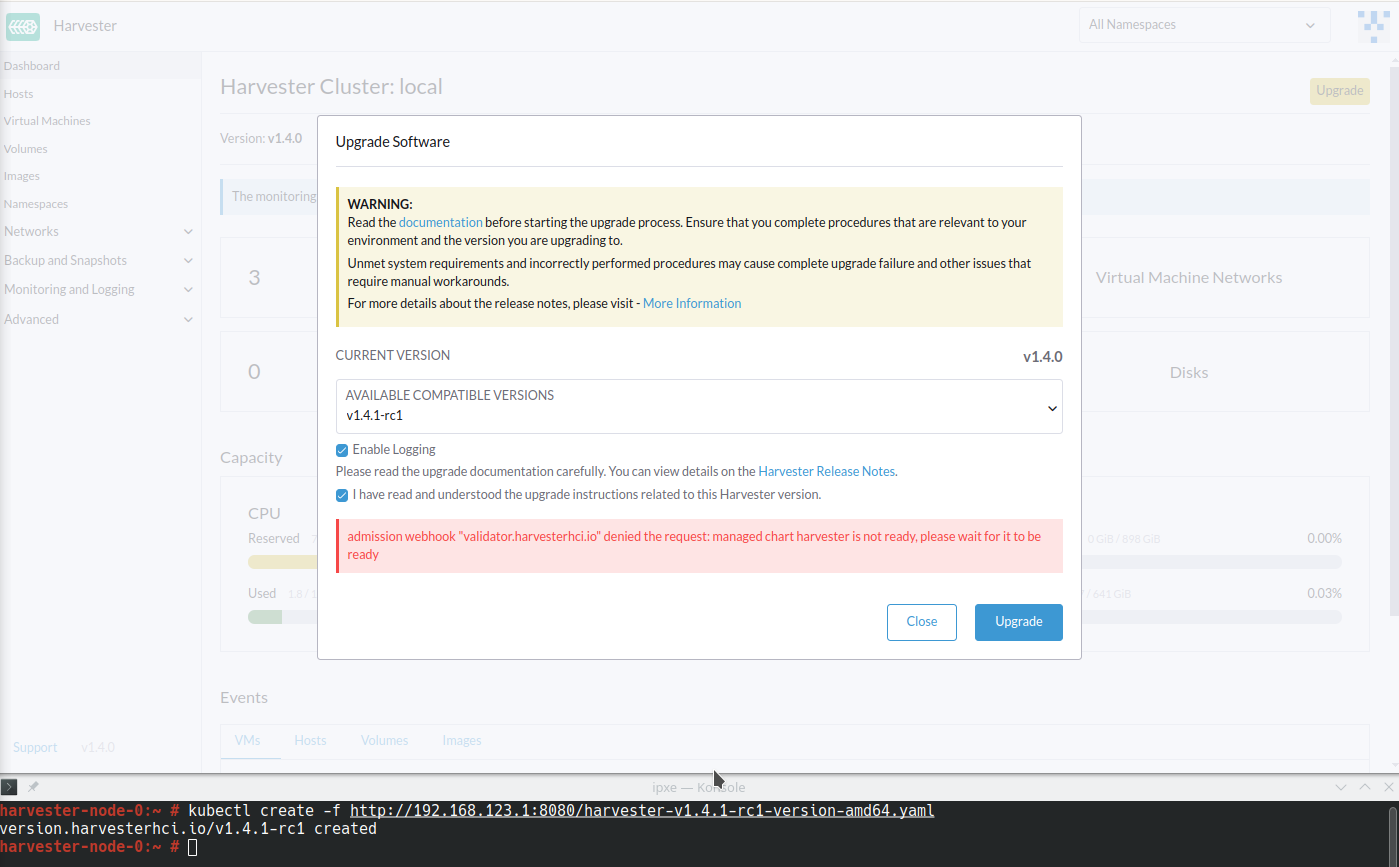
Das Harvester ManagedChart zeigt die Fehlermeldung
cannot patch "harvester-longhorn" with kind StorageClass: admission webhook "validator.harvesterhci.io" denied the request: default storage class %!s(MISSING) already exists, please reset it firstan. -
Der Webhook lehnt die Upgrade-Anfrage ab.
Sie können eine der folgenden Umgehungslösungen durchführen:
-
Setzen Sie
harvester-longhornals die Standard-StorageClass fest. -
Fügen Sie
spec.values.storageClass.defaultStorageClass: falsezumharvesterManagedChart hinzu.kubectl edit managedchart harvester -n fleet-local -
Fügen Sie
timeoutSeconds: 600zur Spezifikation des Harvester ManagedCharts hinzu.kubectl edit managedchart harvester -n fleet-local
Verwandtes Problem: #7375
3. Upgrade bleibt im Status "Warten auf Neustart" hängen.
Der Upgrade-Prozess kann im Status "Warten auf Neustart" hängen bleiben, nachdem das Harvester v1.4.1-Image auf einem Knoten installiert und ein Neustart initiiert wurde. An diesem Punkt beobachtet der Upgrade Controller, ob das Harvester v1.4.1-Betriebssystem läuft.
Wenn das Harvester v1.4.1-Image (im Folgenden als active.img bezeichnet) aus irgendeinem Grund nicht bootet, startet der Knoten automatisch im Fallback-Modus neu und bootet das zuvor installierte Harvester v1.4.0-Image (im Folgenden als passive.img bezeichnet). Der Upgrade Controller kann das erwartete Betriebssystem nicht erkennen, sodass das Upgrade hängen bleibt, bis ein Administrator das Problem mit active.img behebt.
active.img kann während des Upgrades aufgrund unzureichenden Speicherplatzes in der COS_STATE-Partition beschädigt und unbootbar werden. Dies tritt auf, wenn Harvester v1.4.0 ursprünglich auf dem Knoten installiert wurde und das System so konfiguriert war, dass es einen separaten Datenträger verwendet. Das Problem tritt in den folgenden Situationen nicht auf:
-
Das System hat eine einzelne Festplatte, die vom Betriebssystem und den Daten gemeinsam genutzt wird.
-
Eine frühere Harvester-Version wurde ursprünglich installiert und später auf v1.4.0 aktualisiert.
Um zu überprüfen, ob das Problem in Ihrer Umgebung besteht, führen Sie die folgenden Schritte aus:
-
Greifen Sie über SSH auf den Knoten zu und melden Sie sich mit dem Root-Konto an.
-
Führen Sie die Befehle
cat /proc/cmdlineundhead -n1 /etc/harvester-release.yamlaus.Beispiel:
# cat /proc/cmdline BOOT_IMAGE=(loop0)/boot/vmlinuz console=tty1 root=LABEL=COS_STATE cos-img/filename=/cOS/passive.img panic=0 net.ifnames=1 rd.cos.oemlabel=COS_OEM rd.cos.mount=LABEL=COS_OEM:/oem rd.cos.mount=LABEL=COS_PERSISTENT:/usr/local rd.cos.oemtimeout=120 audit=1 audit_backlog_limit=8192 intel_iommu=on amd_iommu=on iommu=pt multipath=off upgrade_failure # head -n1 /etc/harvester-release.yaml harvester: v1.4.0Das Vorhandensein von
cos-img/filename=/cOS/passive.imgundupgrade_failurein der Ausgabe zeigt an, dass das System im Fallback-Modus gestartet wurde. Die Harvester-Version in/etc/harvester-release.yamlbestätigt, dass das System derzeit das Image v1.4.0 verwendet. -
Überprüfen Sie, ob
active.imgbeschädigt ist, indem Sie den Befehlfsck.ext2 -nf /run/initramfs/cos-state/cOS/active.imgausführen.Beispiel:
# fsck.ext2 -nf /run/initramfs/cos-state/cOS/active.img e2fsck 1.46.4 (18-Aug-2021) Pass 1: Checking inodes, blocks, and sizes Pass 2: Checking directory structure [...a list of various different errors may appear here...] e2fsck: aborted COS_ACTIVE: ********** WARNING: Filesystem still has errors ********** -
Überprüfen Sie die Partitionsgrößen, indem Sie den Befehl
lsblk -o NAME,LABEL,SIZEausführen.Beispiel:
# lsblk -o NAME,LABEL,SIZE NAME LABEL SIZE loop0 COS_ACTIVE 3G sr0 1024M vda 250G ├─vda1 COS_GRUB 64M ├─vda2 COS_OEM 64M ├─vda3 COS_RECOVERY 4G ├─vda4 COS_STATE 8G └─vda5 COS_PERSISTENT 237.9G vdb HARV_LH_DEFAULT 128GDie Ausgabe im Beispiel zeigt eine
COS_STATE-Partition mit einer Größe von 8G. In diesem speziellen Fall, der einen fehlgeschlagenen Upgrade-Versuch und ein beschädigtesactive.imgbetrifft, hatte die Partition wahrscheinlich nicht genügend freien Speicherplatz, damit das Upgrade erfolgreich sein konnte.
Um das Problem zu beheben, führen Sie die folgenden Schritte aus:
-
Wenn Ihr Cluster zwei oder mehr Knoten hat, greifen Sie über SSH auf die verbleibenden Knoten zu und überprüfen Sie die Festplattennutzung von
active.imgundpassive.img.# du -sh /run/initramfs/cos-state/cOS/* 1.7G /run/initramfs/cos-state/cOS/active.img 3.1G /run/initramfs/cos-state/cOS/passive.imgWenn
passive.img3,1G Speicherplatz verbraucht, führen Sie die folgenden Befehle mit dem Root-Konto aus:# mount -o remount,rw /run/initramfs/cos-state # fallocate --dig-holes /run/initramfs/cos-state/cOS/passive.img # mount -o remount,ro /run/initramfs/cos-statepassive.imgwird in eine Sparse-Datei umgewandelt, die nur 1,7G Speicherplatz verbrauchen sollte (das gleiche wieactive.img). Dies stellt sicher, dass die anderen Knoten genügend freien Speicherplatz haben, um zu verhindern, dass der Upgrade-Prozess erneut hängen bleibt. -
Greifen Sie über SSH auf den festgefahrenen Knoten zu und führen Sie dann die folgenden Befehle mit dem Root-Konto aus:
# mount -o remount,rw /run/initramfs/cos-state # cp /run/initramfs/cos-state/cOS/passive.img \ /run/initramfs/cos-state/cOS/active.img # tune2fs -L COS_ACTIVE /run/initramfs/cos-state/cOS/active.img # mount -o remount,ro /run/initramfs/cos-stateDas vorhandene (saubere)
passive.imgwird über das beschädigteactive.imgkopiert, und das Label wird korrekt gesetzt. -
Starten Sie den festgefahrenen Knoten neu und wählen Sie dann den ersten Eintrag (Harvester v1.4.1) auf dem GRUB-Bootbildschirm aus.
Der GRUB-Bootbildschirm zeigt standardmäßig zunächst Harvester v1.4.1 (fallback) an. Trotz der angezeigten Version startet das System in Harvester v1.4.0.
-
Kopieren Sie
rootfs.squashfsvon der Harvester v1.4.1 ISO an einen geeigneten Ort auf dem festgefahrenen Knoten.Die ISO kann entweder auf dem festgefahrenen Knoten oder auf einem anderen System eingebunden werden. Sie können die Datei mit dem
scpBefehl kopieren. -
Greifen Sie über SSH auf den festgefahrenen Knoten zu und führen Sie dann die folgenden Befehle mit dem Root-Konto aus:
# mkdir /tmp/manual-os-upgrade # mkdir /tmp/manual-os-upgrade/config # mkdir /tmp/manual-os-upgrade/rootfs # mount -o loop rootfs.squashfs /tmp/manual-os-upgrade/rootfs # cat > /tmp/manual-os-upgrade/config/config.yaml <<EOF upgrade: system: size: 3072 EOF # elemental upgrade \ --logfile /tmp/manual-os-upgrade/upgrade.log \ --directory /tmp/manual-os-upgrade/rootfs \ --config-dir /tmp/manual-os-upgrade/config \ --debugSie müssen den Beispielpfad in der vierten Zeile durch den tatsächlichen Pfad der kopierten
rootfs.squashfsersetzen.Ein neues (sauberes)
active.imgwird basierend auf dem Root-Image der Harvester v1.4.1 ISO erstellt.Wenn Fehler auftreten, speichern Sie eine Kopie von
/tmp/manual-os-upgrade/upgrade.log. -
Führen Sie folgende Befehle aus:
# umount /tmp/manual-os-upgrade/rootfs # rebootDer Knoten sollte erfolgreich in Harvester v1.4.1 booten, und das Upgrade sollte wie erwartet fortschreiten.
4. Das Upgrade wird unerwartet neu gestartet, nachdem der "Dismiss it"-Button geklickt wurde.
Wenn Sie Rancher verwenden, um SUSE Virtualization zu aktualisieren, zeigt die Rancher UI ein Dialogfeld mit einem Button mit der Aufschrift "Dismiss it" an. Ein Klick auf diesen Button kann zu folgenden Problemen führen:
-
Der
statusAbschnitt desharvesterhci.io/v1beta1/upgradeCR wird gelöscht, was den Verlust aller wichtigen Informationen über das Upgrade zur Folge hat. -
Der Upgrade-Prozess wird unerwartet neu gestartet.
Dieses Problem betrifft Rancher v2.10.x, das v1.0.2, v1.0.3 und v1.0.4 der Harvester UI Erweiterung verwendet. Alle SUSE Virtualization UI-Versionen sind nicht betroffen. Das Problem ist in Harvester UI Erweiterung v1.0.5 und v1.5.0 behoben.
Um dieses Problem zu vermeiden, führen Sie eine der folgenden Aktionen aus:
-
Verwenden Sie die SUSE Virtualization UI für Upgrades. Ein Klick auf den "Dismiss it"-Button in der SUSE Virtualization UI führt nicht zu unerwartetem Verhalten.
-
Anstatt den Button in der Rancher UI zu klicken, führen Sie den folgenden Befehl gegen den Cluster aus:
kubectl -n harvester-system label upgrades -l harvesterhci.io/latestUpgrade=true harvesterhci.io/read-message=true
Verwandtes Problem: #7791
5. Virtuelle Maschinen, die migrierbare RWX-Volumes verwenden, starten unerwartet neu.
Virtuelle Maschinen, die migrierbare RWX-Volumes verwenden, starten unerwartet neu, wenn die CSI-Plugin-Pods neu gestartet werden. Dieses Problem betrifft SUSE Virtualization v1.4.x, v1.5.0 und v1.5.1.
Die Umgehungslösung besteht darin, die Einstellung Automatisch Arbeitslast-Pod löschen, wenn das Volume unerwartet getrennt wird in der SUSE Storage UI vor dem Start des Upgrades zu deaktivieren. Sie müssen die Einstellung erneut aktivieren, sobald das Upgrade abgeschlossen ist.
Das Problem wird in SUSE Storage v1.8.3, v1.9.1 und späteren Versionen behoben. SUSE Virtualization v1.6.0 wird SUSE Storage v1.9.1 enthalten.