|
Este documento ha sido traducido utilizando tecnología de traducción automática. Si bien nos esforzamos por proporcionar traducciones precisas, no ofrecemos garantías sobre la integridad, precisión o confiabilidad del contenido traducido. En caso de discrepancia, la versión original en inglés prevalecerá y constituirá el texto autorizado. |
Escribiendo consultas PromQL para gráficos representativos
Directrices
Cuando SUSE® Observability muestra datos en un gráfico, casi siempre necesita cambiar la resolución de los datos almacenados para que se ajusten al espacio disponible para el gráfico. Para obtener los gráficos más representativos posibles, sigue estas directrices:
-
No consultes la métrica en bruto, sino que siempre agrega a lo largo del tiempo (usando las funciones
*_over_timeorate). -
Utiliza el parámetro
${__interval}como el rango para las agregaciones a lo largo del tiempo, se ajustará automáticamente con la resolución del gráfico. -
Utiliza el parámetro
${__rate_interval}como el rango para las agregaciones derate, también se ajustará automáticamente con la resolución del gráfico, pero tiene en cuenta comportamientos específicos derate. -
Proyecta métricas solo a las etiquetas utilizadas agregando sobre diferentes series temporales.
Aplicar una agregación a menudo significa que se hace un compromiso para enfatizar ciertos patrones en las métricas más que en otros. Por ejemplo, para ventanas de tiempo grandes, max_over_time mostrará todos los picos, pero no mostrará todos los valles. Mientras que min_over_time hace exactamente lo contrario y avg_over_time suavizará tanto los picos como los valles. Para mostrar este comportamiento, aquí hay un ejemplo de vinculación de métricas utilizando el uso de CPU de los pods. Para probarlo tú mismo, cópialo a un archivo YAML y utiliza el CLI para aplicarlo en tu propio SUSE® Observability (puedes eliminarlo más tarde).
Proyectar potencialmente múltiples series temporales a un subconjunto de sus etiquetas agrupa series temporales que difieren en un detalle irrelevante. Al crear una vinculación de métricas, solo las etiquetas que se utilizan en la leyenda son relevantes. De manera similar, al crear monitores, solo aquellas etiquetas que son necesarias para mapear a un (estado de monitor en un) componente deben ser devueltas por la consulta.
- _type: MetricBinding
chartType: line
enabled: true
tags: {}
unit: short
name: CPU Usage (different aggregations and intervals)
priority: HIGH
identifier: urn:stackpack:my-stackpack:metric-binding:pod-cpu-usage-a
queries:
- expression: sum(max_over_time(container_cpu_usage{cluster_name="${tags.cluster-name}", namespace="${tags.namespace}", pod_name="${name}"}[${__interval}])) by (cluster_name, namespace, pod_name) /1000000000
alias: max_over_time dynamic interval
- expression: sum(min_over_time(container_cpu_usage{cluster_name="${tags.cluster-name}", namespace="${tags.namespace}", pod_name="${name}"}[${__interval}])) by (cluster_name, namespace, pod_name) /1000000000
alias: min_over_time dynamic interval
- expression: sum(avg_over_time(container_cpu_usage{cluster_name="${tags.cluster-name}", namespace="${tags.namespace}", pod_name="${name}"}[${__interval}])) by (cluster_name, namespace, pod_name) /1000000000
alias: avg_over_time dynamic interval
- expression: sum(last_over_time(container_cpu_usage{cluster_name="${tags.cluster-name}", namespace="${tags.namespace}", pod_name="${name}"}[${__interval}])) by (cluster_name, namespace, pod_name) /1000000000
alias: last_over_time dynamic interval
- expression: sum(max_over_time(container_cpu_usage{cluster_name="${tags.cluster-name}", namespace="${tags.namespace}", pod_name="${name}"}[1m])) by (cluster_name, namespace, pod_name) /1000000000
alias: max_over_time 1m interval
- expression: sum(min_over_time(container_cpu_usage{cluster_name="${tags.cluster-name}", namespace="${tags.namespace}", pod_name="${name}"}[1m])) by (cluster_name, namespace, pod_name) /1000000000
alias: min_over_time 1m interval
- expression: sum(avg_over_time(container_cpu_usage{cluster_name="${tags.cluster-name}", namespace="${tags.namespace}", pod_name="${name}"}[1m])) by (cluster_name, namespace, pod_name) /1000000000
alias: avg_over_time 1m interval
- expression: sum(last_over_time(container_cpu_usage{cluster_name="${tags.cluster-name}", namespace="${tags.namespace}", pod_name="${name}"}[1m])) by (cluster_name, namespace, pod_name) /1000000000
alias: last_over_time 1m interval
scope: (label = "stackpack:kubernetes" and type = "pod")
Después de aplicarlo, abre la perspectiva de métricas para un pod en SUSE® Observability (preferiblemente un pod con algunos picos y valles en el uso de CPU). Amplía el gráfico utilizando el icono en la esquina superior derecha para obtener una mejor vista. Ahora también puedes cambiar la ventana de tiempo para ver cuáles son los efectos de las diferentes agregaciones (30 minutos frente a 24 horas, por ejemplo).
|
Cuando la vinculación de métricas no especifica una agregación, SUSE® Observability utilizará automáticamente la agregación |
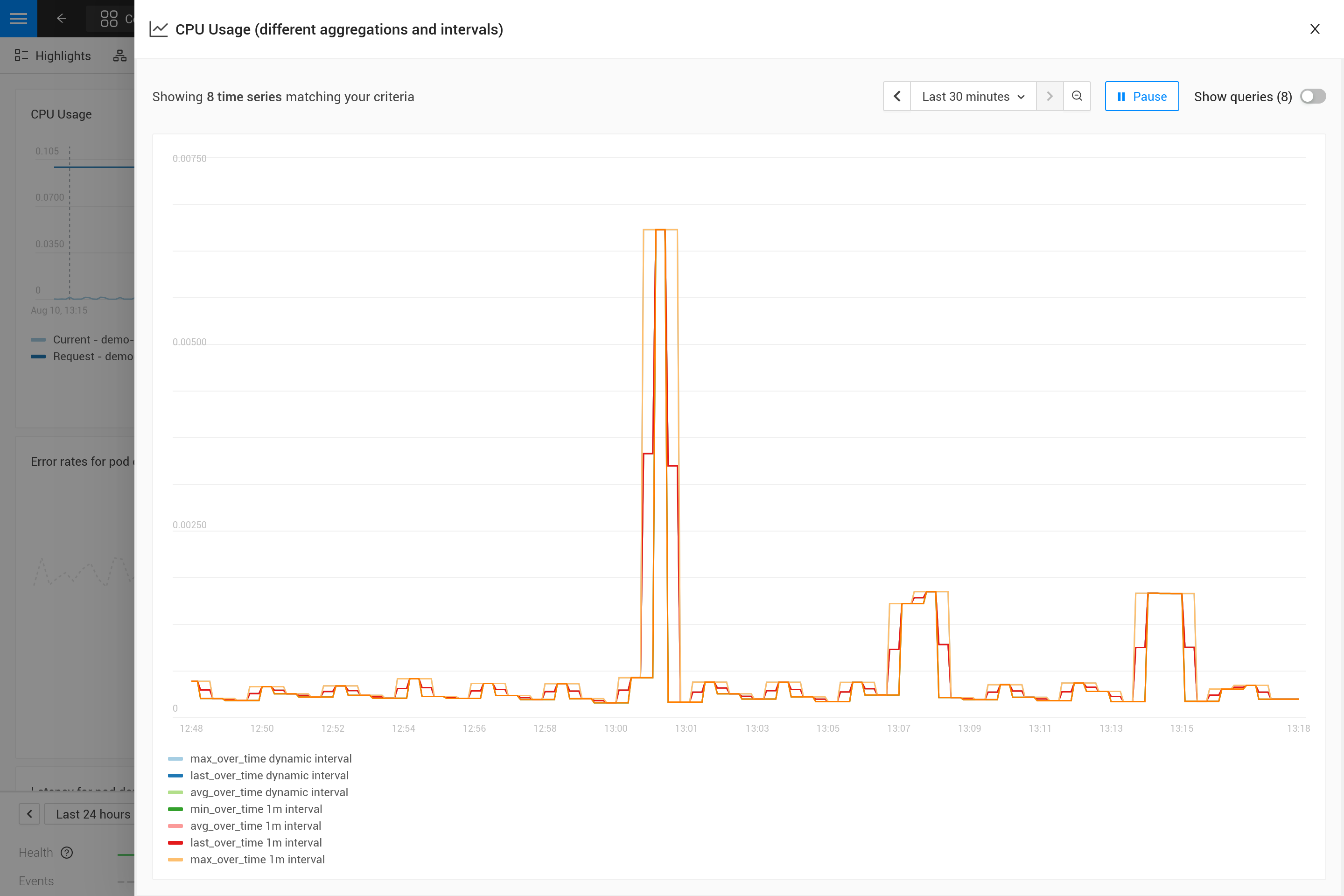
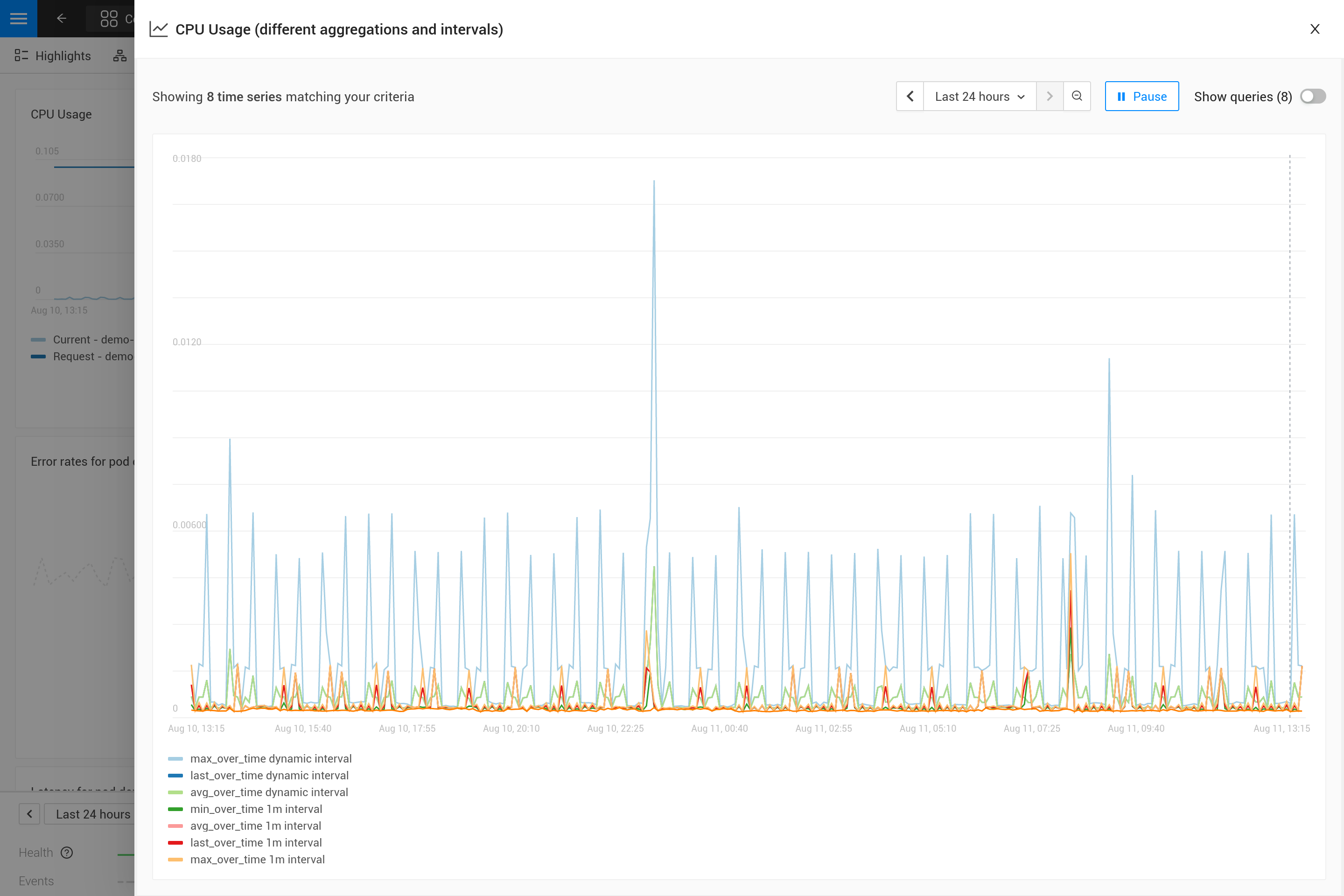
¿Por qué es necesaria la agregación?
Primero que nada, ¿por qué deberías usar una agregación? No tiene sentido recuperar más puntos de datos de la tienda métrica de los que caben en el gráfico. Por lo tanto, SUSE® Observability determina automáticamente el paso necesario entre dos puntos de datos para obtener un buen resultado. Para ventanas de tiempo cortas (por ejemplo, un gráfico que muestra solo una hora de datos), esto resulta en un paso pequeño (alrededor de 10 segundos). Las métricas a menudo solo se recogen cada 30 segundos, por lo que para pasos de 10 segundos, el mismo valor se repetirá durante tres pasos antes de cambiar al siguiente valor. Al hacer zoom hacia atrás a una ventana de tiempo de una semana, se requerirá un paso mucho mayor (alrededor de una hora, dependiendo del tamaño exacto del gráfico en pantalla).
Cuando los pasos se vuelven más grandes que la resolución de los puntos de datos recogidos, se debe tomar una decisión sobre cómo resumir los puntos de datos del rango de tiempo de una hora en un solo valor. Cuando ya se especifica una agregación en el tiempo en la consulta, se utilizará para hacer eso. Sin embargo, si no se especifica ninguna agregación, o cuando el intervalo de agregación es menor que el paso, se utiliza la agregación last_over_time, con el tamaño step como intervalo. El resultado es que solo se utiliza el último punto de datos de cada hora para "resumir" todos los puntos de datos en esa hora.
Para resumir, al ejecutar una consulta PromQL para un rango de tiempo de una semana con un paso de una hora esta consulta:
container_cpu_usage /1000000000
se convierte automáticamente en:
last_over_time(container_cpu_usage[1h]) /1000000000
Pruébalo tú mismo en el SUSE® Observability playground.
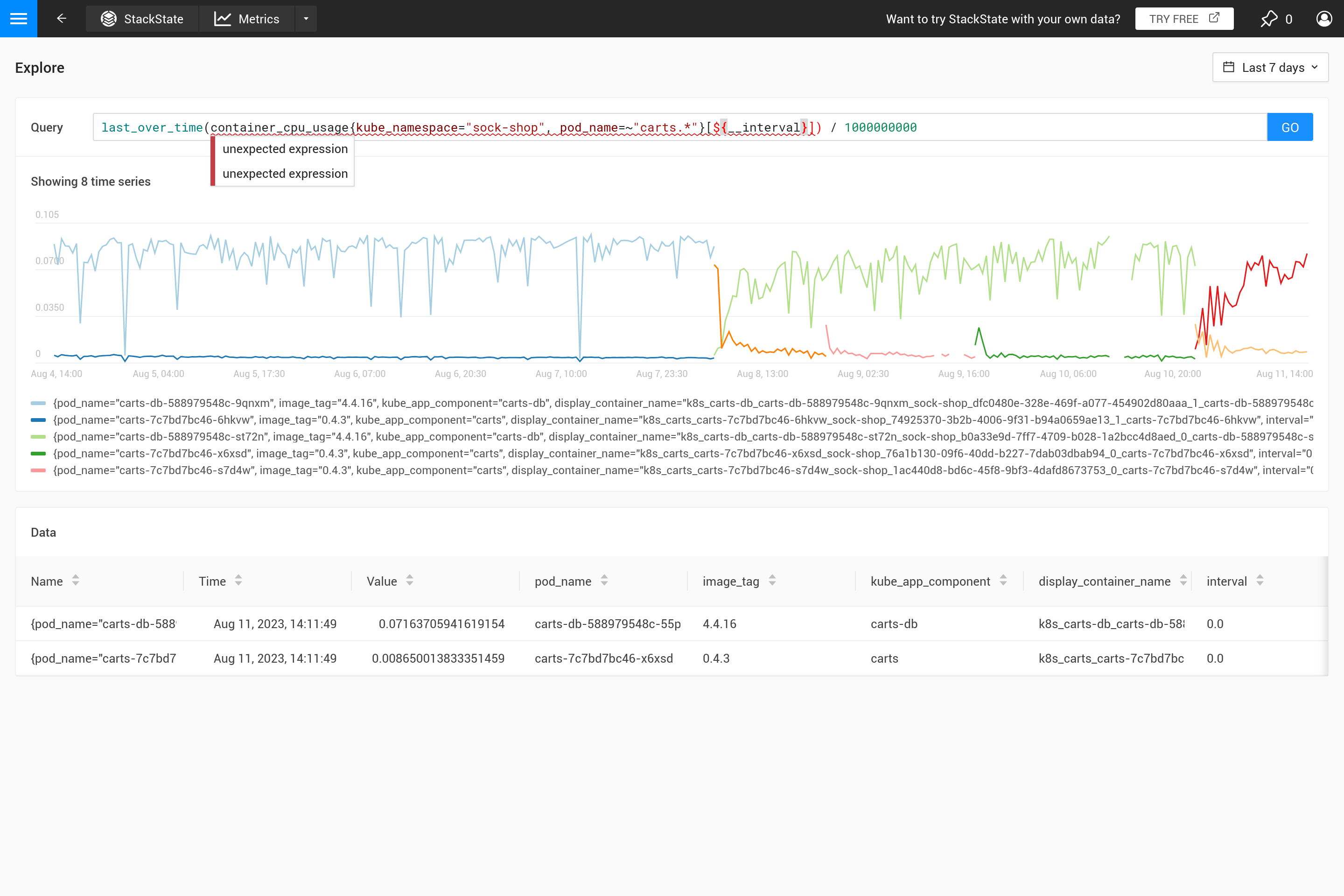
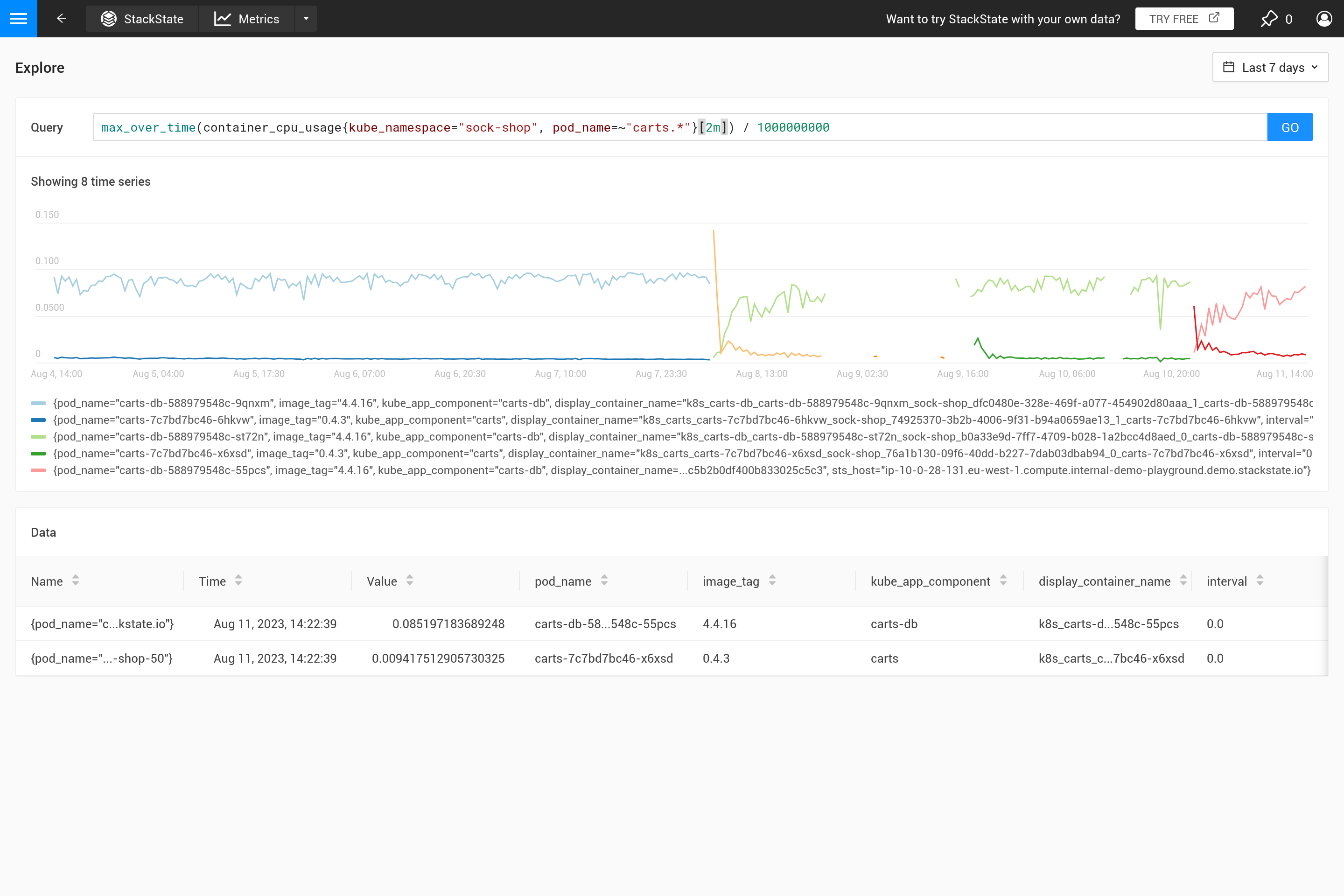
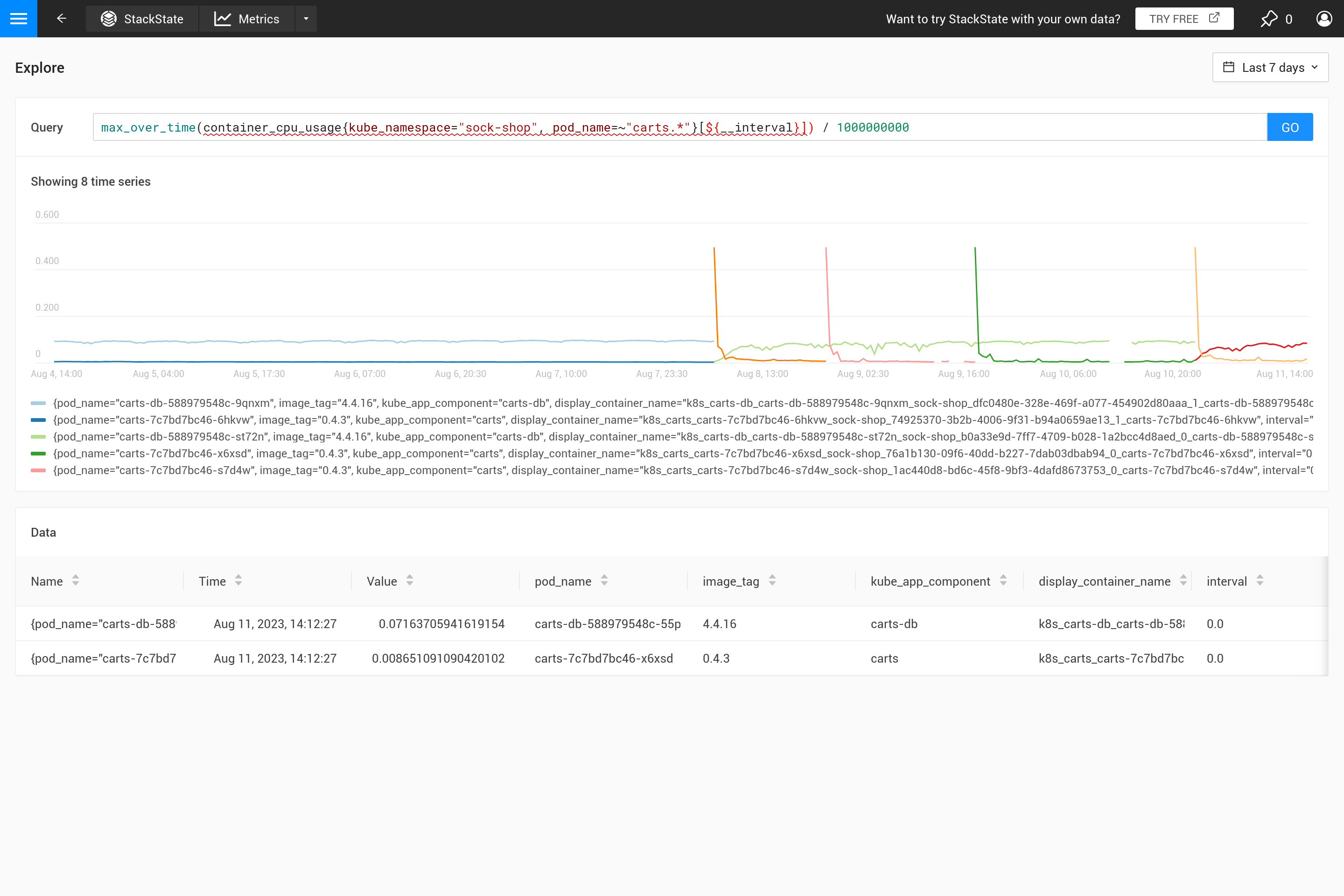
A menudo, este comportamiento no es intencionado y es mejor decidir por ti mismo qué tipo de agregación se necesita. Usando diferentes funciones de agregación, es posible enfatizar cierto comportamiento (a costa de ocultar otro comportamiento). ¿Es más importante ver picos, valles, un gráfico suave, etc.? Entonces utiliza el parámetro ${__interval} para el rango, ya que se reemplaza automáticamente con el tamaño step utilizado para la consulta. El resultado es que se utilizan todos los puntos de datos en el paso.
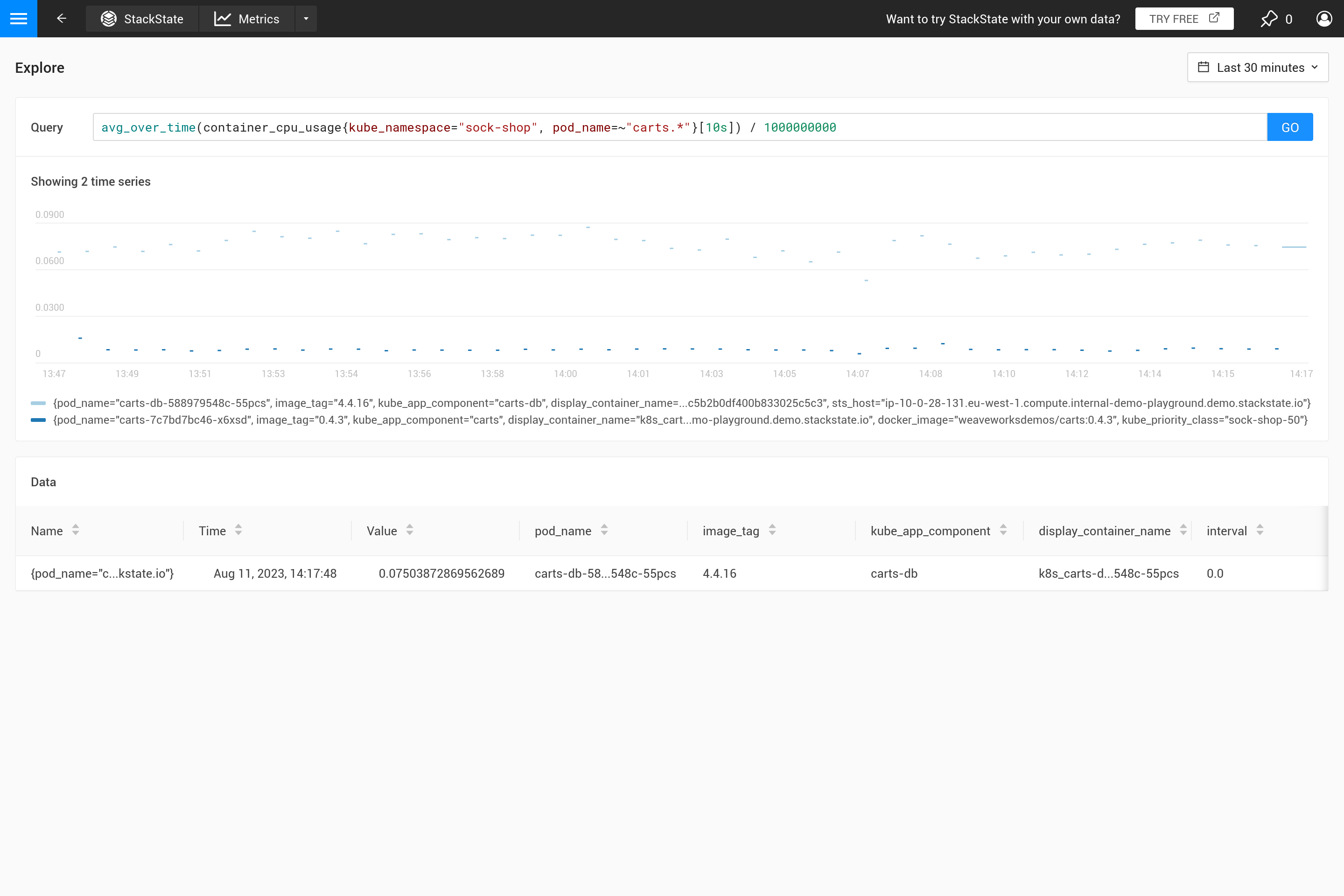
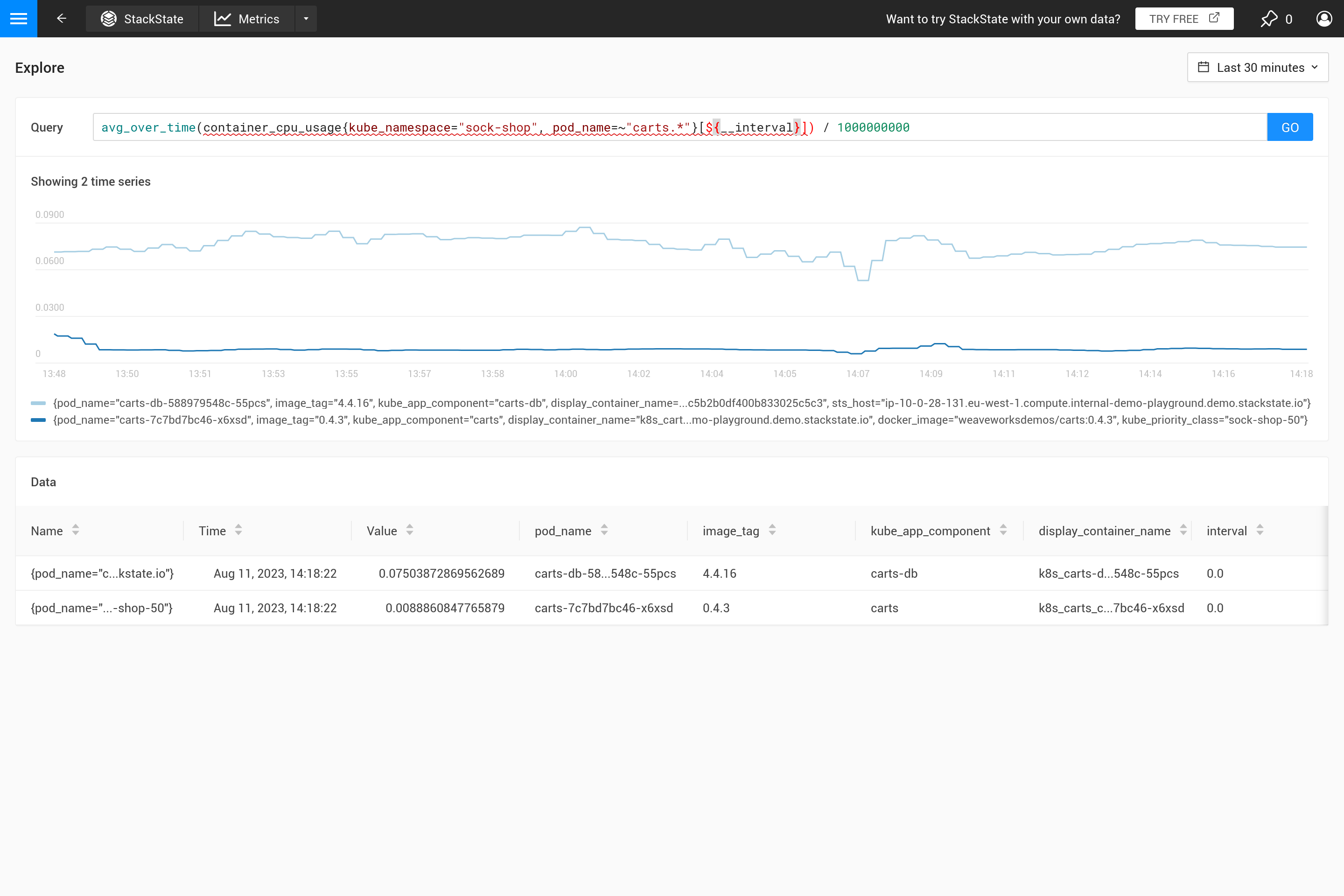
El parámetro ${interval} previene otro problema. Cuando el tamaño step y, por lo tanto, el valor ${interval}, se reducirían a un tamaño más pequeño que la resolución de los datos métricos almacenados, esto resultaría en huecos en el gráfico.
Por lo tanto, ${__interval} nunca se reducirá a menos de 2* el intervalo de raspado por defecto (el intervalo de raspado por defecto es de 30 segundos) del agente SUSE® Observability.
Finalmente, la función rate() requiere al menos dos puntos de datos en el intervalo para calcular una tasa en absoluto. Con menos de dos puntos de datos, la tasa no tendrá un valor. Por lo tanto, ${__rate_interval} está garantizado para ser siempre al menos 4 * el intervalo de raspado. Esto garantiza que no haya huecos inesperados ni otro comportamiento extraño en los gráficos de tasas, a menos que falten datos.
Hay algunas excelentes publicaciones en blogs en internet que explican esto con más detalle: