Solución de problemas avanzada
Cuando eres un cliente principal, contacta con el soporte de SUSE Observability en https://scc.suse.com/ para obtener ayuda configurando SUSE Observability en tu clúster local. Utiliza Paquete de Soporte (Registros) para recopilar información sobre tu instancia para el equipo de soporte.
Esta página proporciona información detallada sobre los subsistemas de la plataforma SUSE Observability para solucionar problemas de despliegue y operativos. Esta página solo debe consultarse cuando los pasos en la solución de problemas no ofrecen una solución.
Enfoque general de solución de problemas
El enfoque general para solucionar problemas operativos de la plataforma SUSE Observability es el siguiente:
-
Obtener una visión general de cómo se comportan los pods a través de
kubectl get pods -
Utiliza la información detallada del subsistema en este documento, junto con los síntomas del problema, para determinar qué pods/subsistemas podrían ser la causa raíz.
-
Inspecciona los registros/metadatos de los pods sospechosos a través de:
-
kubectl logs <pod-name> --all-containers=true -
kubectl describe pod <pod-name> -
Una forma rápida de obtener todos los registros/descripciones relacionados con SUSE Observability es a través del Paquete de Soporte (Registros).
-
-
Podría ser que los registros indiquen que alguna dependencia está fallando, en este caso investiga la dependencia.
Visión general de los subsistemas
Bases de datos
SUSE Observability está impulsado por varias bases de datos, siempre que una base de datos esté fallando, esto debe investigarse primero porque todos los demás servicios dependen de ella.
-
Zookeeper: Zookeeper se utiliza para el descubrimiento de servicios, orquestación y failover. Zookeeper se despliega utilizando 1 o más pods con el nombre:-
suse-observability-zookeeper-<n>
-
-
Kafka: Kafka se utiliza para el paso de mensajes entre casi todos los servicios: Kafka se despliega mediante los siguientes pods:-
suse-observability-kafka-<n>: Despliegue principal de Kafka -
<release-name>-kafkaup-operator-kafkaup-*: Operador auxiliar realizando actualizaciones de Kafka
-
-
StackGraph: StackGraph almacena la configuración (de usuario) y la topología. StackGraph está construido a partir de múltiples componentes y tiene 2 modos de despliegue. HA y noHA.-
Tephra: Gestiona el inicio, la confirmación y los conflictos de transacciones de la base de datos. Servido por el pod<release-name>-hbase-tephra-<n>-
<release-name>-hbase-tephra-<n>: Pod del servidor de transacciones Tephra. Realiza un seguimiento de las transacciones y los conflictos.
-
-
HBase-HA: Almacena los datos de StackGraph, distribuidos en múltiples pods con diferentes responsabilidades:-
<release-name>-hbase-hdfs-nn-0: Nodo de nombre para HDFS, realiza un seguimiento del índice de archivos -
<release-name>-hbase-hdfs-snn-0: Nodo de nombre secundario, realiza tareas de limpieza después del nodo de nombre -
<release-name>-hbase-hdfs-dn-<n>: Datanode de HDFS, almacena los datos reales -
<release-name>-hbase-hbase-master-<n>: Maestro de HBase, coordina tablas y regiones -
<release-name>-hbase-hbase-rs-<n>: Servidor de región de HBase, sirve tablas y regiones, almacena sus datos en HDFS
-
-
HBase-non-HA:-
<release-name>-hbase-stackgraph-0: Todos los componentes de StackGraph se despliegan como un único pod en la configuraciónnon-HA. Esto también incluye su propia instancia de Zookeeper.
-
-
-
VictoriaMetrics: Almacena datos métricos. Se despliega por los pods:-
suse-observability-victoria-metrics-<n>-0: Nodo principal de almacenamiento de datos/consulta de VictoriaMetrics -
suse-observability-vmagent-0: Agente de ingestión para VictoriaMetrics. Los datos se envían a vmagent antes de ser reenviados y almacenados.
-
-
ClickHouse: Almacena datos de trazas. Desplegado por el/los siguientes pod(s):-
suse-observability-clickhouse-shard0-<n>: Almacén principal de Clickhouse
-
-
ElasticSearch: Almacena eventos y registros. Desplegado por los siguientes pods:-
suse-observability-elasticsearch-master-<n>: Almacén principal de Elasticsearch -
<release-name>-prometheus-elasticsearch-exporter-*: Exporta métricas de rendimiento de las instancias de Elasticsearch
-
Servicios de ingestión
La plataforma de observabilidad de SUSE recibe datos enviados por el agente y el agente de OpenTelemetry (OTEL). Los servicios de ingestión realizan un procesamiento inicial y llevan los datos al almacenamiento.
-
Receiver: El receptor implementa la API del lado de la colección para el agente de observabilidad de SUSE. Acepta y autoriza datos de telemetría (registros, eventos, métricas o topología) y los reenvía al almacén de datos correspondiente o a Kafka. Se puede desplegar en modo único o dividido:-
Receiver-Split:-
<release-name>-suse-observability-receiver-logs-*: Recibe registros y los coloca en Elasticsearch -
<release-name>-suse-observability-receiver-process-agent-*: Recibe información de procesos y de conectividad de red y la reenvía a los temas de Kafka -
<release-name>-suse-observability-receiver-base-*: Todos los demás datos del agente de observabilidad de SUSE pasan por aquí.
-
-
Receiver-NonSplit:-
<release-name>-suse-observability-receiver-*: Todos los datos del agente de observabilidad de SUSE pasan por aquí.
-
-
-
OpenTelemetry Collector: Proporciona un punto final al que los agentes de OpenTelemetry pueden enviar datos de OpenTelemetry y produce trazas, métricas y topología basadas en los datos enviados.-
suse-observability-otel-collector-0: Pod único que implementa el colector OTEL
-
Procesamiento y servicio
La plataforma de observabilidad de SUSE realiza la correlación y el monitoreo de los datos de telemetría que recibe. Los resultados se sirven al cliente bajo demanda a través de la API. La plataforma central puede ejecutarse en modo distribuido y no distribuido. El modo distribuido permite un mayor rendimiento.
-
Correlator: Correlaciona la información de conexión TCP para convertirla en topología. Implementado por pod:-
<release-name>-suse-observability-correlate-*
-
-
Events2Elasticsearch: Procesa eventos y los almacena en Elasticsearch: Implementado por pod:-
<release-name>-suse-observability-e2es-*
-
-
Anomaly Detection: La plataforma de observabilidad de SUSE realiza detección de anomalías (desactivada por defecto) en métricas, produciendo violaciones de salud:-
<release-name>-anomaly-detection-spotlight-manager-*: Detección de anomalías distribuida -
<release-name>-anomaly-detection-spotlight-worker-*: Realiza detección de anomalías en flujos de métricas
-
-
Platform-Distributed: La plataforma contiene los principales componentes de procesamiento y la API de servicios. En modo distribuido, las unidades funcionales se separan. Los pods que pertenecen a la plataforma:-
<release-name>-suse-observability-api-*: Sirve todos los datos al usuario y gestiona la instalación/desinstalación de StackPack. -
<release-name>-suse-observability-checks-*: Ejecuta los monitores -
<release-name>-suse-observability-health-sync-*: Procesa la información de salud (violación) de los monitores y del Agente de Observabilidad de SUSE y la adjunta a la topología. -
<release-name>-suse-observability-initializer-*: Coordina la inicialización de los almacenes de datos y las migraciones -
<release-name>-suse-observability-notification-*: Reenvía notificaciones basadas en violaciones de salud y configuración del usuario a sistemas en sentido descendente como Slack/Opsgenie. -
<release-name>-suse-observability-slicing-*: Optimiza continuamente el historial de topología para una recuperación rápida -
<release-name>-suse-observability-state-*: Procesa violaciones de salud y las agrega en la salud de los componentes. -
<release-name>-suse-observability-sync-*: Procesa los datos de topología combinados con la configuración del usuario y los convierte en el gráfico de topología.
-
-
Platform-Mono:-
<release-name>-suse-observability-server-*: Contiene toda la funcionalidad de la configuraciónPlatform-Distributedpero en un solo pod.
-
miscelánea
-
Routing: Acepta conexiones y las dirige al servicio backend correcto:-
<release-name>-suse-observability-router-: Router basado en Envoy
-
-
UI: Interfaz de usuario basada en React-
<release-name>-suse-observability-ui: Sirve solo el código y los activos de la interfaz de usuario estática, todo el comportamiento dinámico lo realiza elapi.
-
-
Backup/Restore: Ejecuta periódicamente trabajos para hacer una copia de seguridad de los diversos almacenes de datos. Tiene un pod en funcionamiento continuo:-
suse-observability-minio-*: Proporciona una interfaz abstracta para interactuar con el almacenamiento de copia de seguridad.
-
Relaciones entre subsistemas
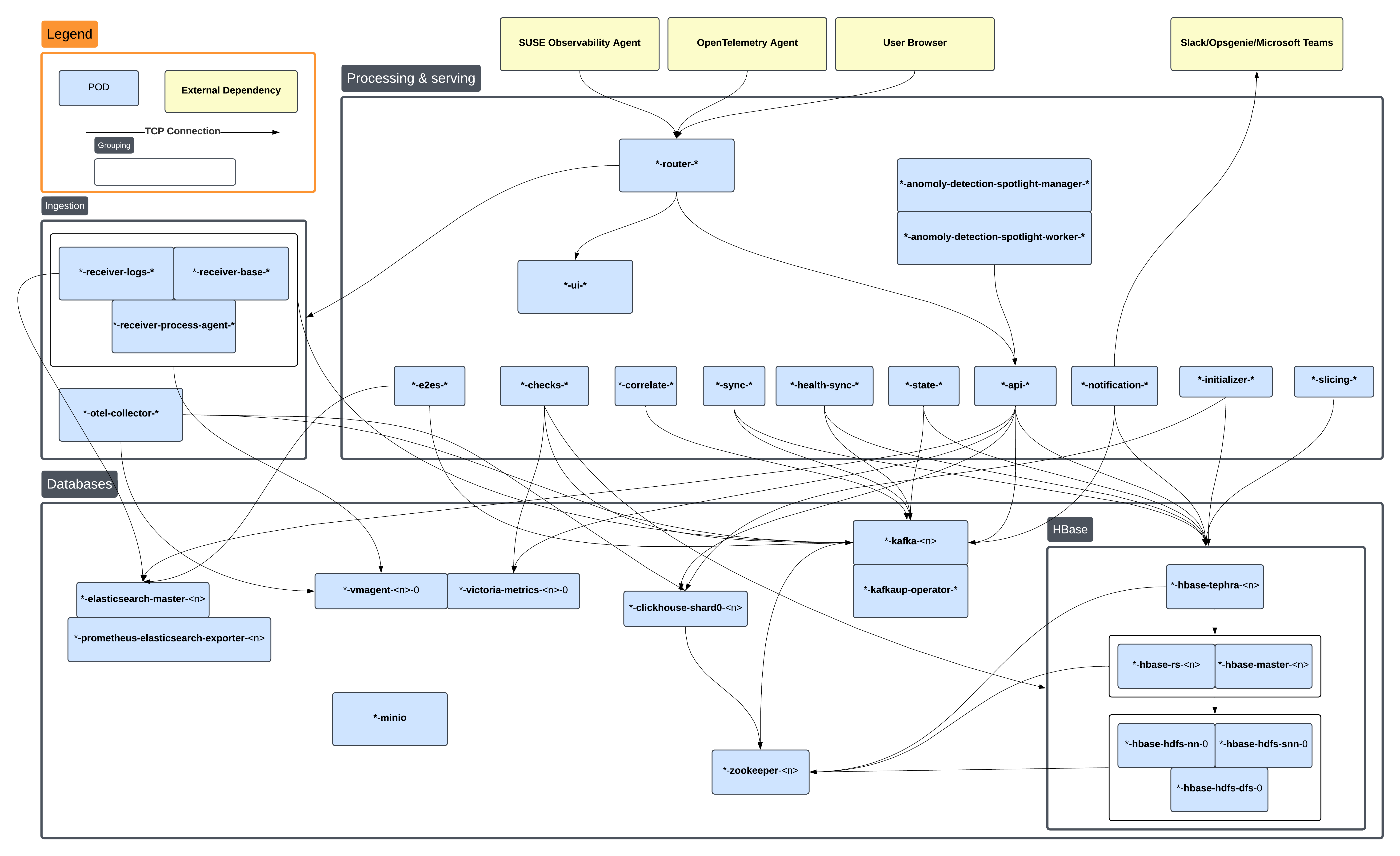
Para encontrar eficazmente la causa raíz de un problema, es importante entender qué pods dependen de otros cuando se despliegan. El siguiente diagrama muestra una visión general de los pods con conexiones TCP que pueden existir entre ellos. Al buscar una causa raíz, tiene sentido mirar al pod que está 'más bajo' en esta cadena de dependencia.
Los nombres de los pods en este diagrama están abreviados por brevedad.