Solução avançada de problemas
Quando você é um cliente prioritário, entre em contato com o suporte da SUSE Observability pelo https://scc.suse.com/ para obter ajuda na configuração do SUSE Observability em seu cluster local. Use Pacote de Suporte (Logs) para coletar informações sobre sua instância para a equipe de suporte.
Esta página fornece informações detalhadas sobre os subsistemas da plataforma SUSE Observability para solucionar problemas operacionais e de implantação. Esta página deve ser consultada apenas quando os passos na solução de problemas não resultarem em uma solução.
Abordagem geral de solução de problemas
A abordagem geral para solucionar problemas operacionais da plataforma SUSE Observability é a seguinte:
-
Obter uma visão geral de como os pods estão se comportando através de
kubectl get pods -
Use as informações detalhadas do subsistema neste documento, juntamente com os sintomas do problema, para determinar quais pods/subsistemas podem ser a causa raiz.
-
Inspecione os logs/metadados dos pods suspeitos através de:
-
kubectl logs <pod-name> --all-containers=true -
kubectl describe pod <pod-name> -
Uma maneira rápida de obter todos os logs/descrições relacionados ao SUSE Observability é através do Pacote de Suporte (Logs).
-
-
Pode ser que os logs apontem para alguma dependência com comportamento inadequado; nesse caso, investigue a dependência.
Visão geral dos subsistemas
Bancos de Dados
O SUSE Observability é alimentado por vários bancos de dados; sempre que um banco de dados estiver com comportamento inadequado, isso deve ser investigado primeiro, pois todos os outros serviços dependem dele.
-
Zookeeper: O Zookeeper é usado para descoberta de serviços, orquestração e failover. O Zookeeper é implantado usando 1 ou mais pods com o nome:-
suse-observability-zookeeper-<n>
-
-
Kafka: O Kafka é usado para a troca de mensagens entre quase todos os serviços: O Kafka é implantado pelos seguintes pods:-
suse-observability-kafka-<n>: Implantação principal do Kafka -
<release-name>-kafkaup-operator-kafkaup-*: Operador auxiliar para fazer upgrade do Kafka.
-
-
StackGraph: O StackGraph armazena as configurações (do usuário) e a topologia. O StackGraph é construído a partir de múltiplos componentes e possui 2 modos de implantação. HA e nonHA.-
Tephra: Gerencia o início, o commit e os conflitos das transações do banco de dados. Servido pelo pod<release-name>-hbase-tephra-<n>-
<release-name>-hbase-tephra-<n>: Pod do servidor de transações Tephra. Acompanha transações e conflitos.
-
-
HBase-HA: Armazena os dados do StackGraph, distribuídos em múltiplos pods com diferentes responsabilidades:-
<release-name>-hbase-hdfs-nn-0: Nome do nó para HDFS, acompanha o índice de arquivos -
<release-name>-hbase-hdfs-snn-0: Nome do nó secundário, realiza trabalho de limpeza após o nome do nó -
<release-name>-hbase-hdfs-dn-<n>: Datanode HDFS, armazena os dados reais -
<release-name>-hbase-hbase-master-<n>: Mestre HBase, coordena tabelas e regiões -
<release-name>-hbase-hbase-rs-<n>: Servidor de Região HBase, serve tabelas e regiões, armazena seus dados no HDFS
-
-
HBase-non-HA:-
<release-name>-hbase-stackgraph-0: Todos os componentes do StackGraph implantados como um único pod na configuraçãonon-HA. Isso também inclui sua própria instância do Zookeeper.
-
-
-
VictoriaMetrics: Armazena dados métricos. É implantado pelos pods:-
suse-observability-victoria-metrics-<n>-0: Nó principal de armazenamento/consulta de dados do VictoriaMetrics -
suse-observability-vmagent-0: Agente de ingestão para o VictoriaMetrics. Os dados são enviados para o vmagent antes de serem encaminhados e armazenados.
-
-
ClickHouse: Armazena dados de rastreamento. Implantado pelos seguintes pods:-
suse-observability-clickhouse-shard0-<n>: Armazenamento principal do ClickHouse
-
-
ElasticSearch: Armazena eventos e logs. Implantado pelos seguintes pods:-
suse-observability-elasticsearch-master-<n>: Armazenamento principal do Elasticsearch -
<release-name>-prometheus-elasticsearch-exporter-*: Exporta métricas de desempenho das instâncias do Elasticsearch
-
Serviços de ingestão
A plataforma de Observabilidade SUSE recebe dados enviados pelo agente e pelo agente OpenTelemetry (OTEL). Os serviços de ingestão realizam o processamento inicial e trazem os dados para o armazenamento.
-
Receiver: O receptor implementa a API do lado da coleta para o agente de Observabilidade SUSE. Aceita e autoriza dados de telemetria (logs, eventos, métricas ou topologia) e os encaminha para o datastore correspondente ou Kafka. Pode ser implantado em modo único ou dividido:-
Receiver-Split:-
<release-name>-suse-observability-receiver-logs-*: Recebe logs e os coloca no Elasticsearch -
<release-name>-suse-observability-receiver-process-agent-*: Recebe informações de conectividade de processos e rede e as encaminha para tópicos do Kafka -
<release-name>-suse-observability-receiver-base-*: Todos os outros dados do Agente de Observabilidade SUSE passam por aqui.
-
-
Receiver-NonSplit:-
<release-name>-suse-observability-receiver-*: Todos os dados do Agente de Observabilidade SUSE passam por aqui.
-
-
-
OpenTelemetry Collector: Fornece um endpoint para que os agentes OpenTelemetry possam enviar dados OpenTelemetry e produz traços, métricas e topologia com base nos dados enviados.-
suse-observability-otel-collector-0: Pod único implementando o coletor OTEL
-
Processamento e entrega.
A plataforma de Observabilidade da SUSE realiza correlação e monitoramento dos dados de telemetria que recebe. Os resultados são disponibilizados ao cliente sob demanda através da API. A plataforma principal pode ser executada em modo distribuído e não distribuído. O modo distribuído permite maior taxa de transferência.
-
Correlator: Correlaciona informações de conexão TCP para transformá-las em topologia. Implementado por pod:-
<release-name>-suse-observability-correlate-*
-
-
Events2Elasticsearch: Processa eventos e os armazena no Elasticsearch: Implementado por pod:-
<release-name>-suse-observability-e2es-*
-
-
Anomaly Detection: A plataforma de Observabilidade da SUSE realiza detecção de anomalias (desativada por padrão) em métricas, produzindo violações de saúde:-
<release-name>-anomaly-detection-spotlight-manager-*: Trabalho de detecção de anomalias distribuídas -
<release-name>-anomaly-detection-spotlight-worker-*: Realiza detecção de anomalias em fluxos de métricas
-
-
Platform-Distributed: A plataforma contém os principais componentes de processamento e a API de serviço. No modo distribuído, as unidades funcionais são separadas. Os pods que pertencem à plataforma:-
<release-name>-suse-observability-api-*: Serve todos os dados ao usuário e gerencia a instalação/desinstalação do StackPack. -
<release-name>-suse-observability-checks-*: Executa os monitores -
<release-name>-suse-observability-health-sync-*: Processa informações de saúde (violações) dos monitores e do Agente de Observabilidade da SUSE e as anexa à topologia. -
<release-name>-suse-observability-initializer-*: Coordena a inicialização dos datastores e migrações -
<release-name>-suse-observability-notification-*: Encaminha notificações com base em violações de saúde e configurações do usuário para sistemas downstream como Slack/Opsgenie. -
<release-name>-suse-observability-slicing-*: Otimizando continuamente o histórico da topologia para recuperação rápida -
<release-name>-suse-observability-state-*: Processando violações de saúde e agregando-as na saúde dos componentes -
<release-name>-suse-observability-sync-*: Processa dados de topologia combinados com as configurações do usuário e os transforma no gráfico de topologia.
-
-
Platform-Mono:-
<release-name>-suse-observability-server-*: Contém toda a funcionalidade da configuraçãoPlatform-Distributed, mas em um único pod.
-
Diversos
-
Routing: Aceita conexões e direciona para o serviço de backend correto:-
<release-name>-suse-observability-router-: Roteador baseado no Envoy
-
-
UI: Interface de usuário baseada em React-
<release-name>-suse-observability-ui: Serve apenas o código e os ativos da interface de usuário estática, todo o comportamento dinâmico é realizado peloapi.
-
-
Backup/Restore: Executa periodicamente tarefas para fazer backup dos vários armazenamentos de dados. Possui um pod em execução continuamente:-
suse-observability-minio-*: Fornece uma interface abstrata para interagir com o armazenamento de backup.
-
Relações entre subsistemas
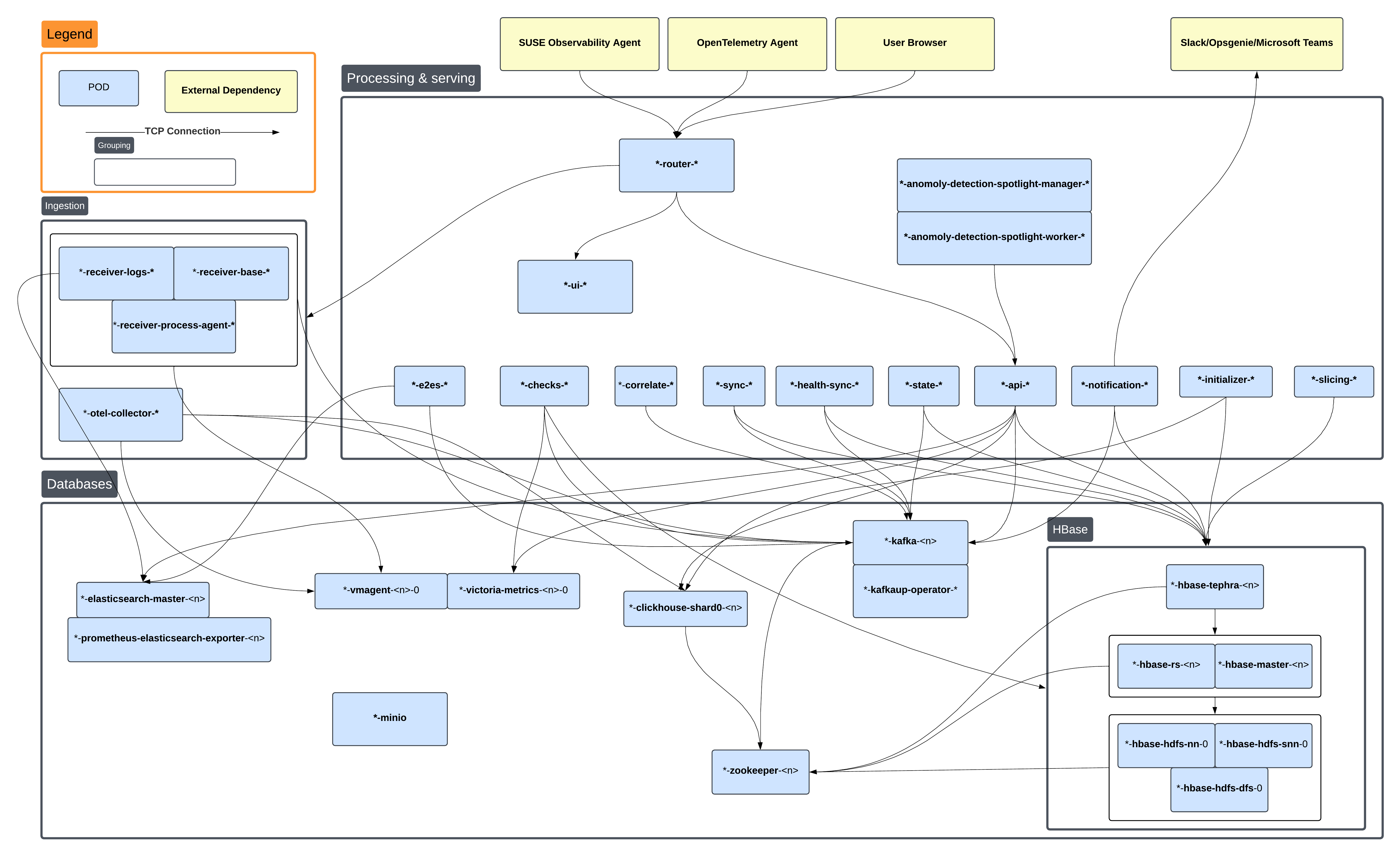
Para encontrar efetivamente a causa raiz de um problema, é importante entender quais pods dependem de outros quando implantados. O diagrama a seguir mostra uma visão geral dos pods com conexões TCP que podem existir entre eles. Ao procurar uma causa raiz, faz sentido olhar para o pod que está 'mais baixo' nesta cadeia de dependência.
Os nomes dos pods neste diagrama estão abreviados para brevidade.