|
Este documento foi traduzido usando tecnologia de tradução automática de máquina. Sempre trabalhamos para apresentar traduções precisas, mas não oferecemos nenhuma garantia em relação à integridade, precisão ou confiabilidade do conteúdo traduzido. Em caso de qualquer discrepância, a versão original em inglês prevalecerá e constituirá o texto official. |
Escrevendo consultas PromQL para gráficos representativos
Diretrizes
Quando o SUSE Observability exibe dados em um gráfico, quase sempre é necessário alterar a resolução dos dados armazenados para que se encaixem no espaço disponível para o gráfico. Para obter os gráficos mais representativos possíveis, siga estas diretrizes:
-
Não consulte a métrica bruta, mas sempre agregue ao longo do tempo (usando as funções
*_over_timeourate). -
Use o parâmetro
${__interval}como o intervalo para agregações ao longo do tempo, ele se ajustará automaticamente com a resolução do gráfico. -
Use o parâmetro
${__rate_interval}como o intervalo para agregações derate, ele também se ajustará automaticamente com a resolução do gráfico, mas leva em conta comportamentos específicos derate.
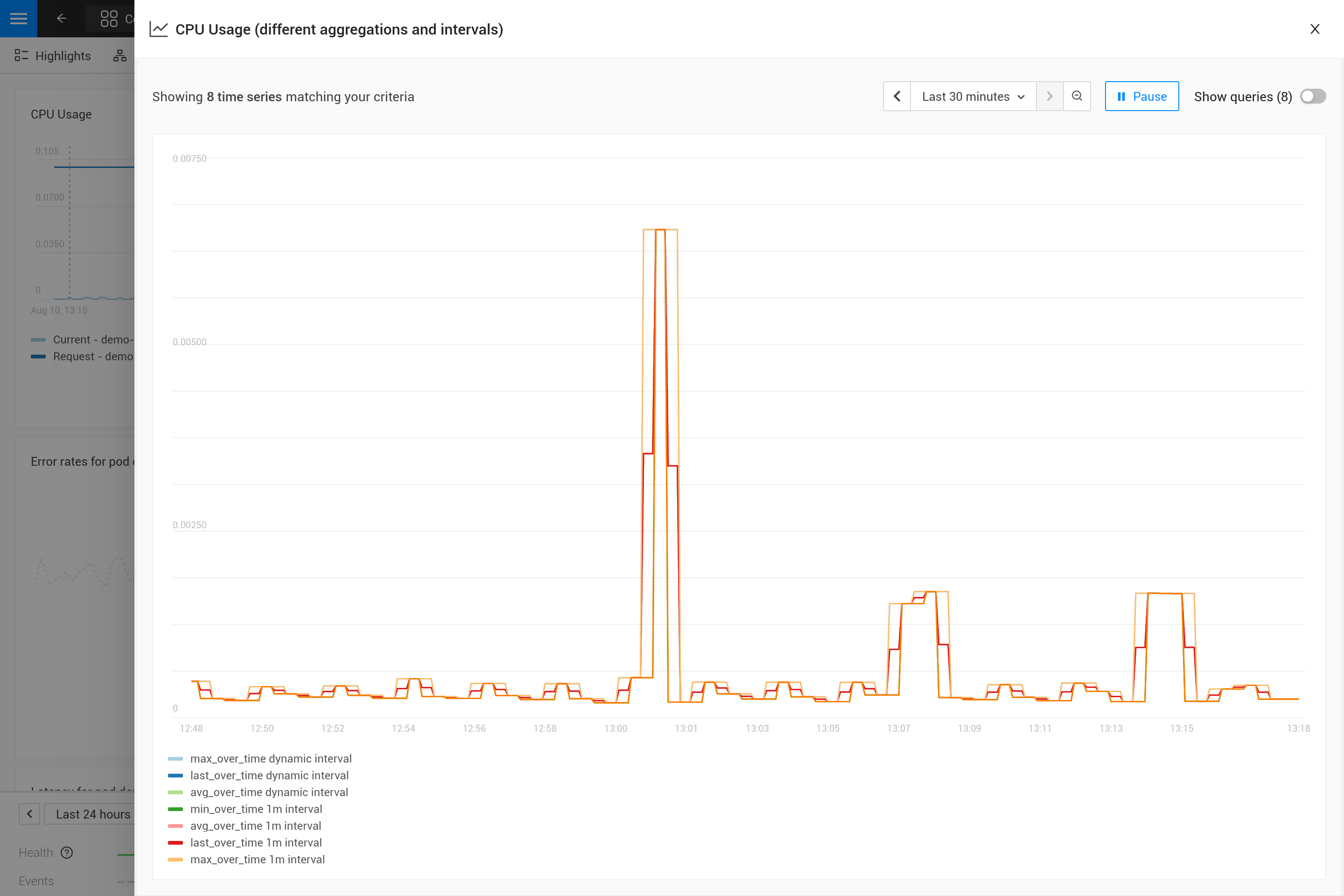
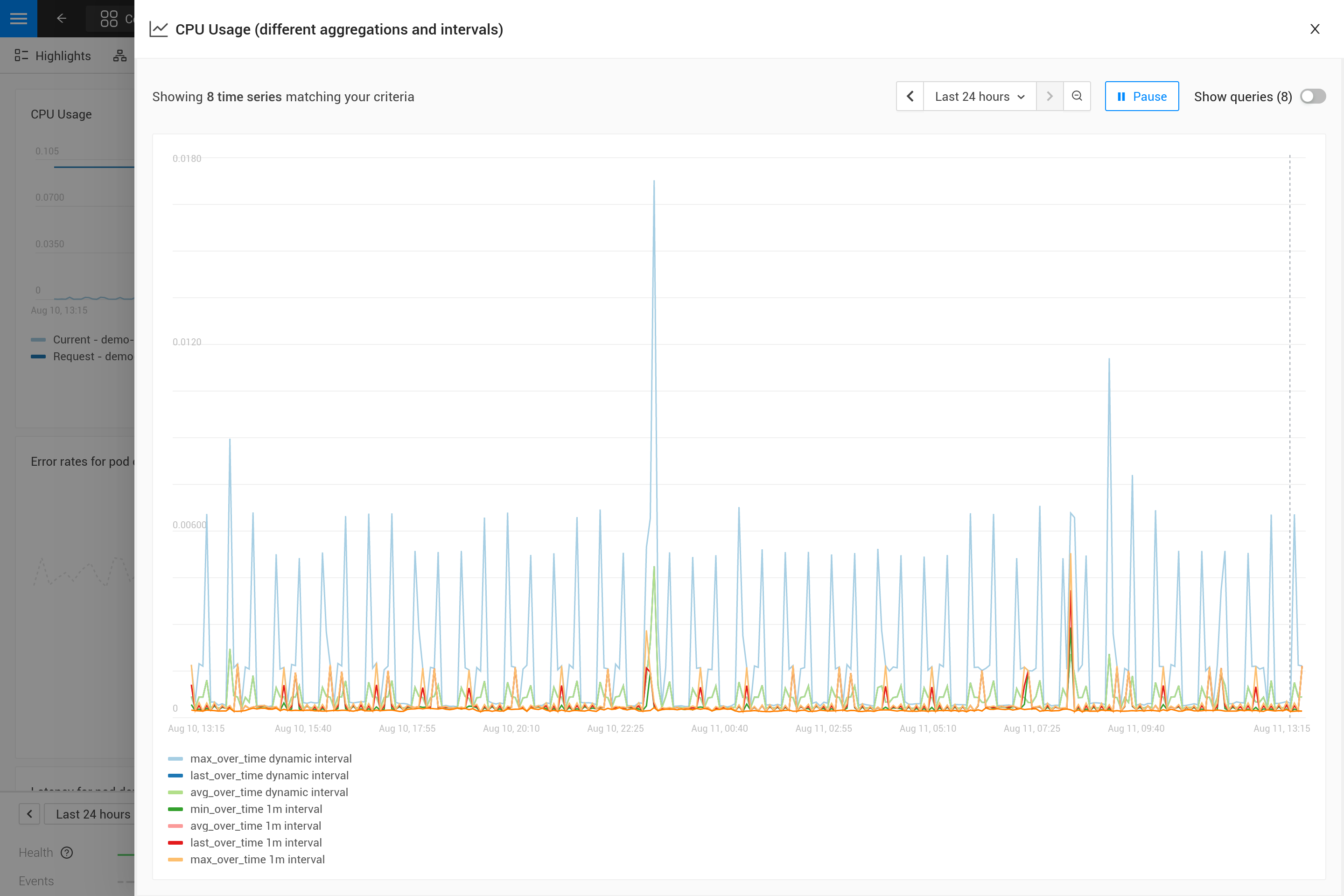
Aplicar uma agregação muitas vezes significa que um compromisso é feito para enfatizar certos padrões nas métricas mais do que outros. Por exemplo, para janelas de tempo grandes, max_over_time mostrará todos os picos, mas não mostrará todos os vales. Enquanto min_over_time faz exatamente o oposto e avg_over_time suaviza tanto picos quanto vales. Para mostrar esse comportamento, aqui está um exemplo de vinculação de métrica usando o uso de CPU de pods. Para experimentar você mesmo, copie-o para um arquivo YAML e use o CLI para aplicá-lo no seu próprio SUSE Observability (você pode removê-lo depois).
nodes:
- _type: MetricBinding
chartType: line
enabled: true
tags: {}
unit: short
name: CPU Usage (different aggregations and intervals)
priority: HIGH
identifier: urn:custom:metric-binding:pod-cpu-usage-a
queries:
- expression: sum(max_over_time(container_cpu_usage{cluster_name="${tags.cluster-name}", namespace="${tags.namespace}", pod_name="${name}"}[${__interval}])) by (cluster_name, namespace, pod_name) /1000000000
alias: max_over_time dynamic interval
- expression: sum(min_over_time(container_cpu_usage{cluster_name="${tags.cluster-name}", namespace="${tags.namespace}", pod_name="${name}"}[${__interval}])) by (cluster_name, namespace, pod_name) /1000000000
alias: min_over_time dynamic interval
- expression: sum(avg_over_time(container_cpu_usage{cluster_name="${tags.cluster-name}", namespace="${tags.namespace}", pod_name="${name}"}[${__interval}])) by (cluster_name, namespace, pod_name) /1000000000
alias: avg_over_time dynamic interval
- expression: sum(last_over_time(container_cpu_usage{cluster_name="${tags.cluster-name}", namespace="${tags.namespace}", pod_name="${name}"}[${__interval}])) by (cluster_name, namespace, pod_name) /1000000000
alias: last_over_time dynamic interval
- expression: sum(max_over_time(container_cpu_usage{cluster_name="${tags.cluster-name}", namespace="${tags.namespace}", pod_name="${name}"}[1m])) by (cluster_name, namespace, pod_name) /1000000000
alias: max_over_time 1m interval
- expression: sum(min_over_time(container_cpu_usage{cluster_name="${tags.cluster-name}", namespace="${tags.namespace}", pod_name="${name}"}[1m])) by (cluster_name, namespace, pod_name) /1000000000
alias: min_over_time 1m interval
- expression: sum(avg_over_time(container_cpu_usage{cluster_name="${tags.cluster-name}", namespace="${tags.namespace}", pod_name="${name}"}[1m])) by (cluster_name, namespace, pod_name) /1000000000
alias: avg_over_time 1m interval
- expression: sum(last_over_time(container_cpu_usage{cluster_name="${tags.cluster-name}", namespace="${tags.namespace}", pod_name="${name}"}[1m])) by (cluster_name, namespace, pod_name) /1000000000
alias: last_over_time 1m interval
scope: (label = "stackpack:kubernetes" and type = "pod")
Após aplicá-lo, abra a perspectiva de métricas para um pod no SUSE Observability (preferencialmente um pod com alguns picos e vales no uso de CPU). Amplie o gráfico usando o ícone no canto superior direito para obter uma visão melhor. Agora você também pode mudar a janela de tempo para ver quais são os efeitos das diferentes agregações (30 minutos vs 24 horas, por exemplo).
|
Quando a vinculação de métrica não especifica uma agregação, o SUSE Observability usará automaticamente a agregação |
Por que isso é necessário?
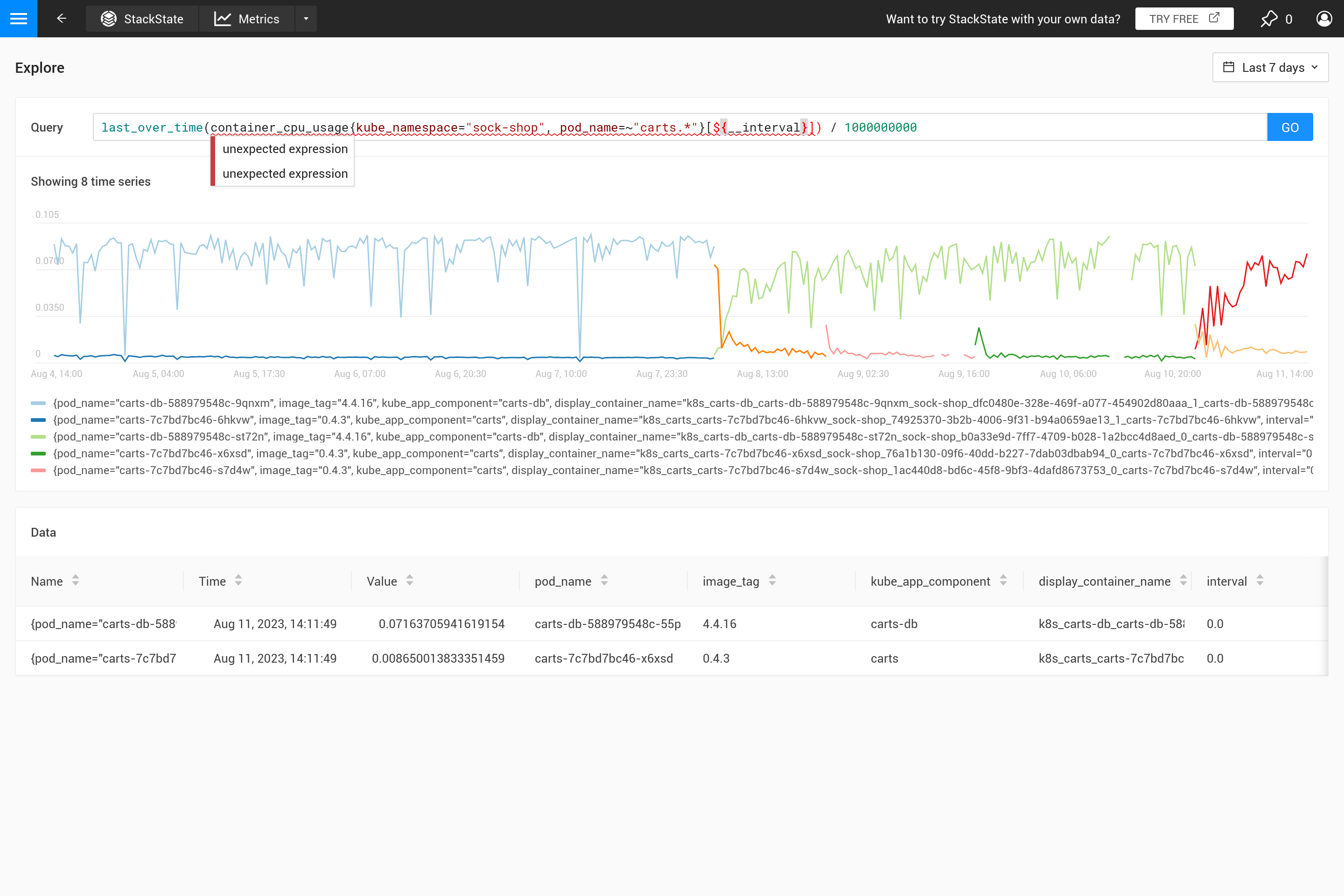
Primeiramente, por que você deve usar uma agregação? Não faz sentido recuperar mais pontos de dados do armazenamento métrico do que cabem no gráfico. Portanto, o SUSE Observability determina automaticamente o passo necessário entre 2 pontos de dados para obter um bom resultado. Para janelas de tempo curtas (por exemplo, um gráfico mostrando apenas 1 hora de dados), isso resulta em um pequeno passo (cerca de 10 segundos). As métricas são frequentemente coletadas a cada 30 segundos, então para passos de 10 segundos, o mesmo valor se repetirá por 3 passos antes de mudar para o próximo valor. Ao ampliar a visualização para uma janela de tempo de 1 semana, será necessário um passo muito maior (cerca de 1 hora, dependendo do tamanho exato do gráfico na tela).
Quando os passos se tornam maiores do que a resolução dos pontos de dados coletados, uma decisão precisa ser tomada sobre como resumir os pontos de dados da faixa de tempo de 1 hora em um único valor. Quando uma agregação ao longo do tempo já está especificada na consulta, ela será usada para isso. No entanto, se nenhuma agregação for especificada, ou quando o intervalo de agregação for menor que o passo, a agregação last_over_time é usada, com o tamanho step como intervalo. O resultado é que apenas o último ponto de dados de cada hora é usado para "resumir" todos os pontos de dados naquela hora.
Para resumir: ao executar uma consulta PromQL para um intervalo de tempo de 1 semana com um passo de 1 hora, esta consulta:
container_cpu_usage /1000000000
é automaticamente convertida para:
last_over_time(container_cpu_usage[1h]) /1000000000
Experimente por conta própria no SUSE Observability playground.
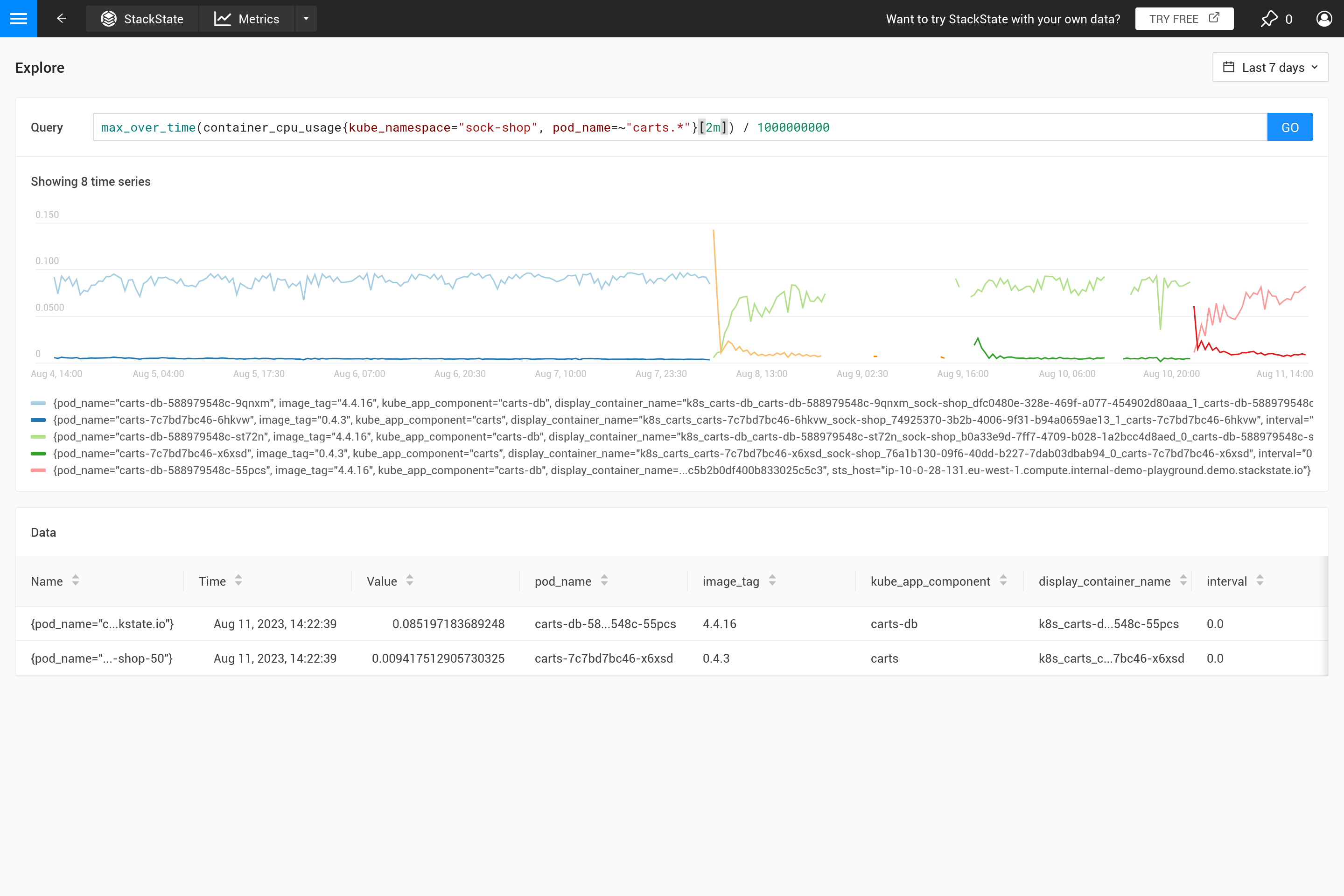
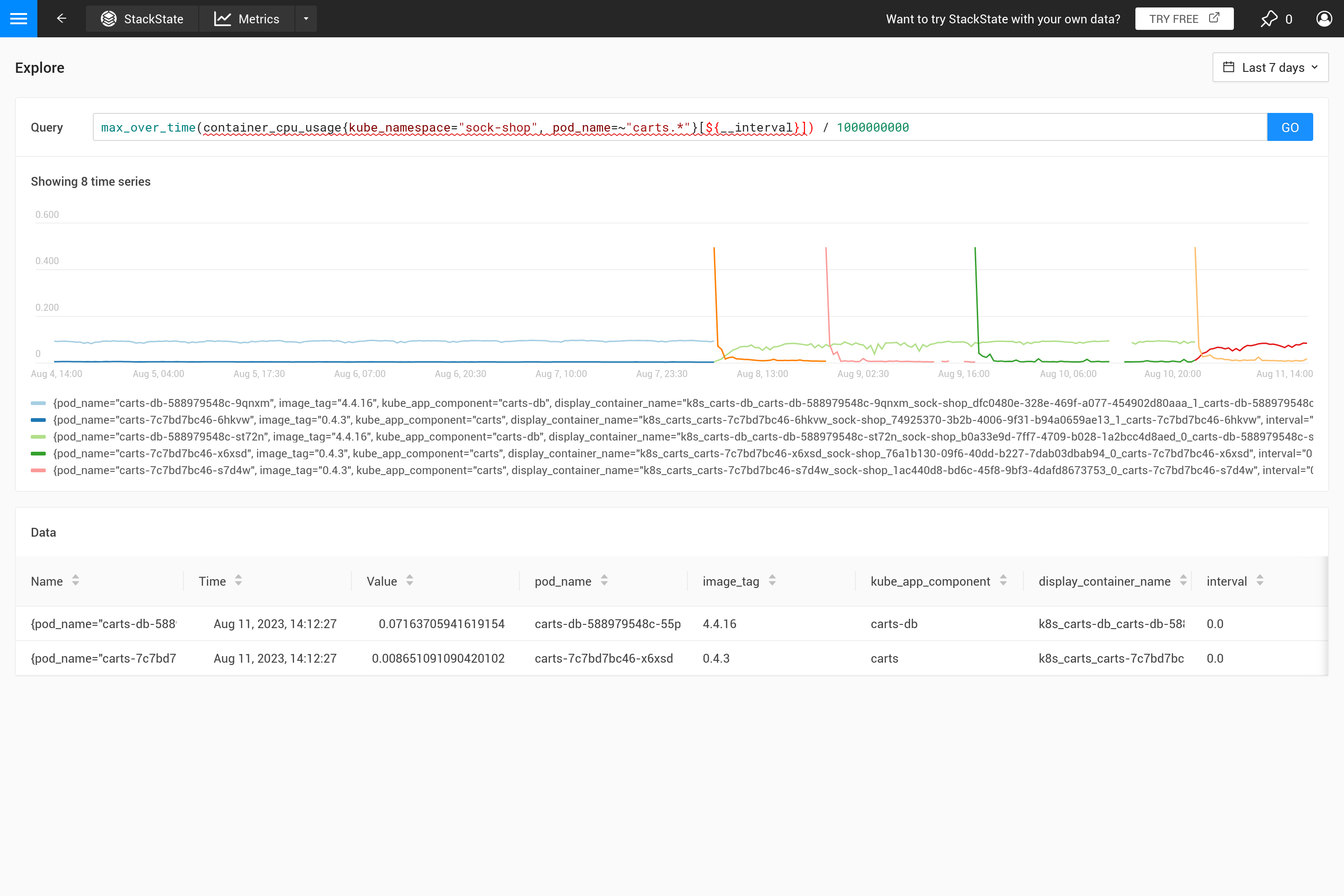
Frequentemente, esse comportamento não é intencional e é melhor decidir por si mesmo que tipo de agregação é necessária. Usando diferentes funções de agregação, é possível enfatizar certos comportamentos (à custa de ocultar outros comportamentos). É mais importante ver picos, vales, um gráfico suave, etc.? Então use o parâmetro ${__interval} para o intervalo, pois ele é automaticamente substituído pelo tamanho step usado para a consulta. O resultado é que todos os pontos de dados no passo são utilizados.
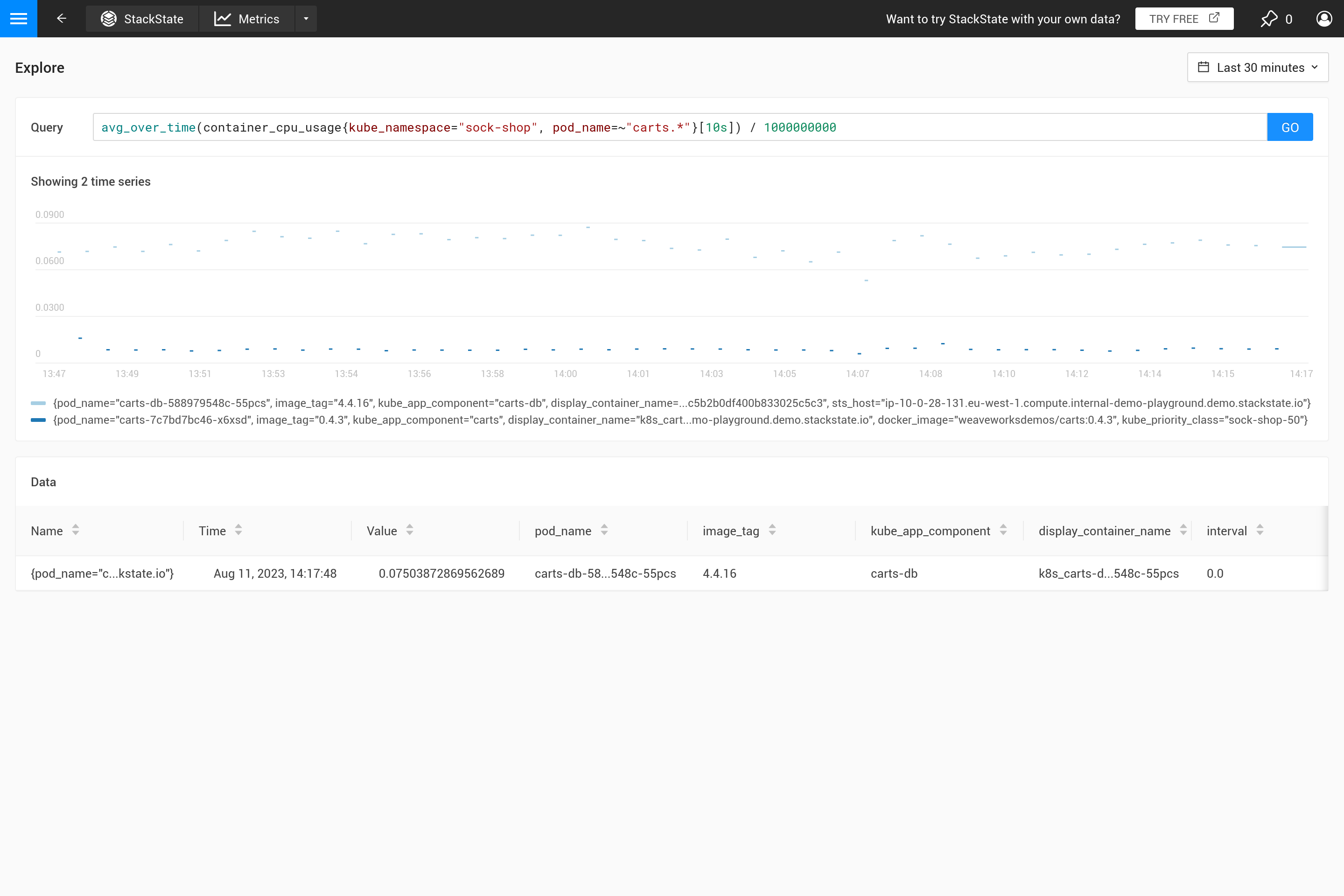
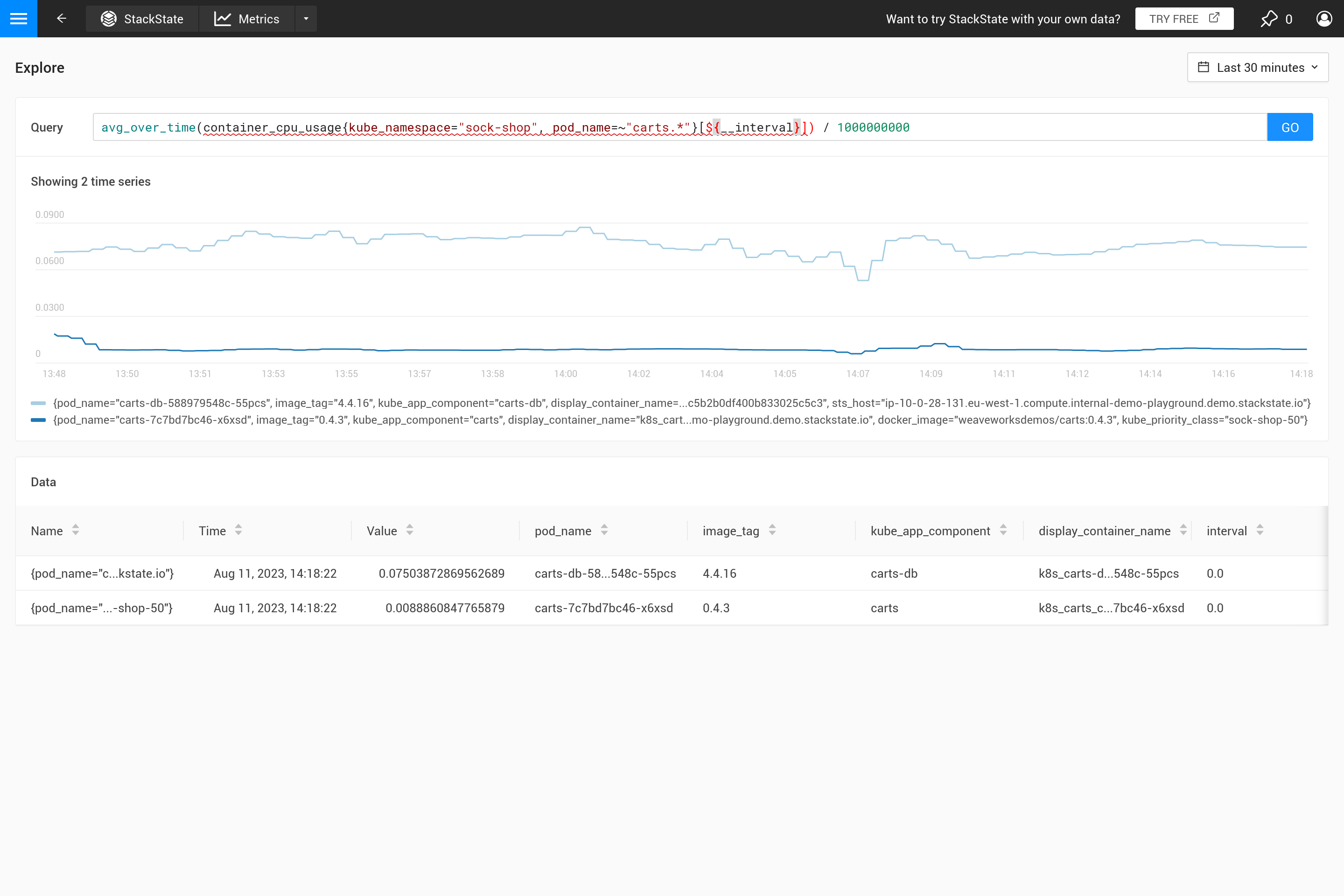
O parâmetro ${interval} previne outro problema. Quando o tamanho step e, portanto, o valor ${interval}, diminuem para um tamanho menor do que a resolução dos dados métricos armazenados, isso resultaria em lacunas no gráfico.
Portanto, ${__interval} nunca diminuirá para menos que 2 vezes o intervalo de coleta padrão (o intervalo de coleta padrão é de 30 segundos) do agente SUSE Observability.
Finalmente, a função rate() requer pelo menos 2 pontos de dados no intervalo para calcular uma taxa. Com menos de 2 pontos de dados, a taxa não terá um valor. Portanto, ${__rate_interval} está garantido para ser sempre pelo menos 4 * o intervalo de coleta. Isso garante que não haja lacunas inesperadas ou outro comportamento estranho em gráficos de taxa, a menos que dados estejam faltando.
Existem alguns excelentes posts em blogs na internet que explicam isso com mais detalhes: