高级故障排除
作为优质客户,请通过 https://scc.suse.com/ 联系 SUSE Observability 支持,以获取在本地群集设置 SUSE Observability 的帮助。使用 支持包(日志) 收集有关您实例的信息,以便支持团队使用。
本页面提供有关 SUSE Observability 平台子系统的详细信息,以便排除部署和操作问题。仅在 故障排除 中的步骤未能解决问题时,才应参考本页面。
一般故障排除方法
故障排除 SUSE Observability 平台操作问题的一般方法如下:
-
通过
kubectl get pods获取有关 pod 行为的概述 -
使用本文件中的详细子系统信息以及问题的症状,确定哪些 pod/子系统可能是根本原因。
-
通过以下方式检查可疑 pod 的日志/元数据:
-
kubectl logs <pod-name> --all-containers=true -
kubectl describe pod <pod-name> -
获取与 SUSE Observability 相关的所有日志/描述的快速方法是通过 支持包(日志)。
-
-
日志可能指向某些依赖项的异常行为,在这种情况下,请调查该依赖项。
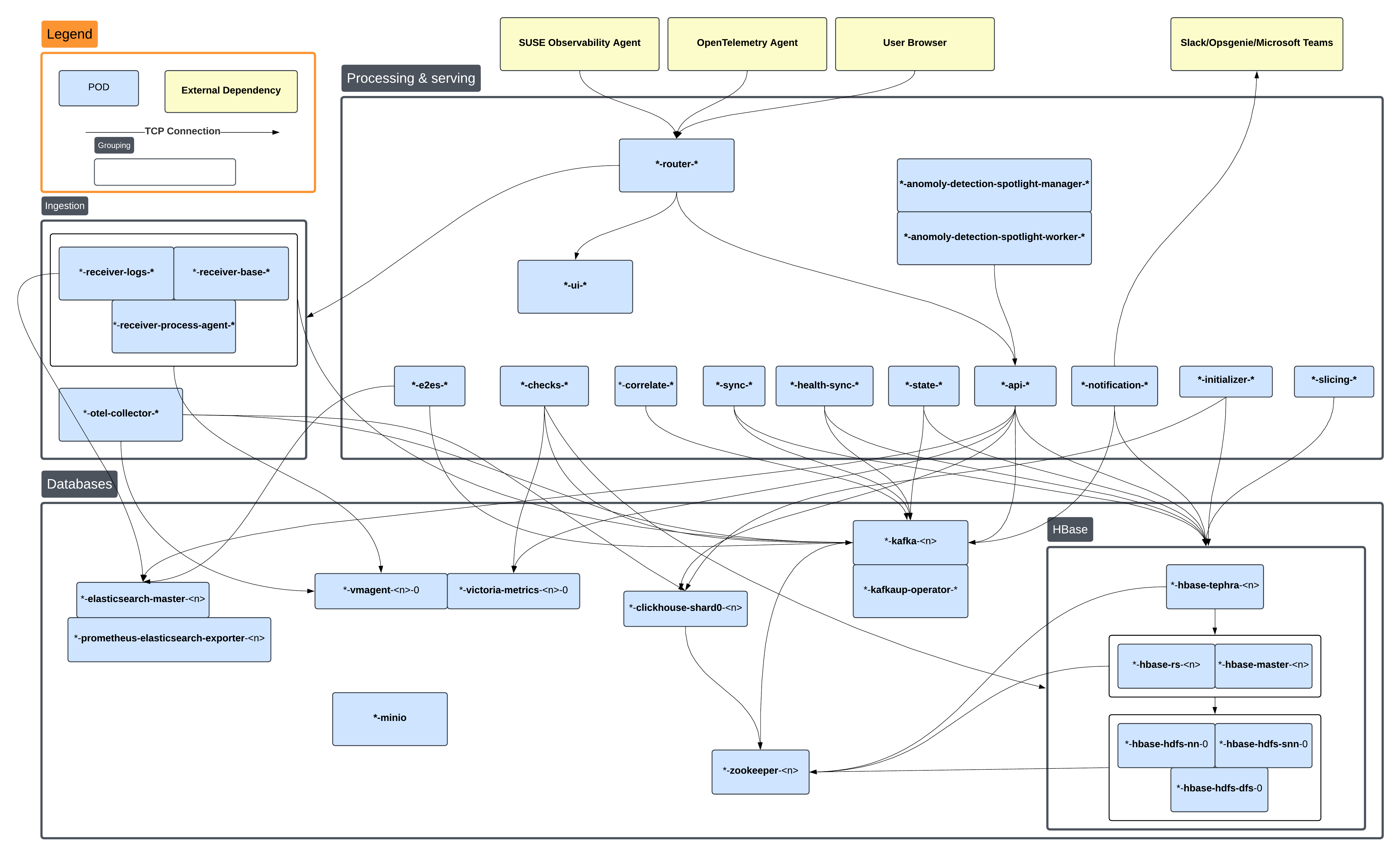
子系统概述
数据库
SUSE Observability 由各种数据库提供支持,每当数据库出现异常时,应首先调查,因为所有其他服务都依赖于它。
-
Zookeeper:Zookeeper 用于服务发现、编排和故障转移。Zookeeper 使用一个或多个名为的 pod 部署:-
suse-observability-zookeeper-<n>
-
-
Kafka:Kafka 用于几乎所有服务之间的消息传递:Kafka 由以下 pod 部署:-
suse-observability-kafka-<n>:主要 Kafka 部署 -
<release-name>-kafkaup-operator-kafkaup-*:执行 Kafka 升级的辅助操作员
-
-
StackGraph:StackGraph 存储了(用户)设置和拓扑。StackGraph 由多个组件构成,并具有两种部署模式。HA 和非 HA。-
Tephra:管理数据库事务的开始、提交和冲突。由 pod<release-name>-hbase-tephra-<n>提供服务-
<release-name>-hbase-tephra-<n>:Tephra 事务服务器 pod。跟踪事务和冲突。
-
-
HBase-HA:存储 StackGraph 数据,分布在多个具有不同职责的 pod 上:-
<release-name>-hbase-hdfs-nn-0:HDFS 的名称节点,跟踪文件索引 -
<release-name>-hbase-hdfs-snn-0:辅助名称节点,在名称节点之后进行清理工作 -
<release-name>-hbase-hdfs-dn-<n>:HDFS 数据节点,存储实际数据 -
<release-name>-hbase-hbase-master-<n>:HBase 主节点,协调表和区域 -
<release-name>-hbase-hbase-rs-<n>:HBase 区域服务器,提供表和区域服务,数据存储在 HDFS 上
-
-
HBase-non-HA:-
<release-name>-hbase-stackgraph-0:所有 StackGraph 组件作为单个 pod 部署在non-HA设置中。这也包括它自己的 zookeeper 实例。
-
-
-
VictoriaMetrics:存储指标数据。由以下 pod 部署:-
suse-observability-victoria-metrics-<n>-0:主要的 VictoriaMetrics 数据存储/查询节点 -
suse-observability-vmagent-0:VictoriaMetrics 的数据摄取代理。数据在转发和存储之前被推送到 vmagent。
-
-
ClickHouse:存储跟踪数据。由以下 pod 部署:-
suse-observability-clickhouse-shard0-<n>:主要的 clickhouse 存储
-
-
ElasticSearch:存储事件和日志。由以下 pods 部署:-
suse-observability-elasticsearch-master-<n>:主要的 Elasticsearch 存储 -
<release-name>-prometheus-elasticsearch-exporter-*:导出 Elasticsearch 实例的性能指标
-
数据摄取服务
SUSE Observability 平台通过代理和 OpenTelemetry (OTEL) 代理获取推送的数据。数据摄取服务执行初步处理并将数据带入存储。
-
Receiver:接收器实现 SUSE Observability 代理的收集端 API。它接受并授权遥测数据(日志、事件、指标或拓扑),并将其转发到相应的数据存储或 Kafka。可以以单一模式或分割模式部署:-
Receiver-Split:-
<release-name>-suse-observability-receiver-logs-*:接收日志并将其放入 Elasticsearch -
<release-name>-suse-observability-receiver-process-agent-*:接收进程和网络连接信息并将其转发到 Kafka 主题 -
<release-name>-suse-observability-receiver-base-*:所有其他 SUSE Observability 代理数据通过这里传输。
-
-
Receiver-NonSplit:-
<release-name>-suse-observability-receiver-*:所有 SUSE Observability 代理数据通过这里传输。
-
-
-
OpenTelemetry Collector:提供一个端点,OpenTelemetry 代理可以将 OpenTelemetry 数据推送到此端点,并根据推送的数据生成跟踪、指标和拓扑。-
suse-observability-otel-collector-0:单个 pod 实现 OTEL 收集器
-
处理和服务
SUSE Observability 平台对接收到的遥测数据进行关联和监控。结果通过 API 按需提供给客户。核心平台可以在分布式和非分布式模式下运行。分布式模式允许更高的吞吐量。
-
Correlator:将 TCP 连接信息关联起来,转化为拓扑结构。由 pod 实现:-
<release-name>-suse-observability-correlate-*
-
-
Events2Elasticsearch:处理事件并将其存储在 Elasticsearch 中:由 pod 实现:-
<release-name>-suse-observability-e2es-*
-
-
Anomaly Detection:SUSE Observability 平台对指标进行异常检测(默认禁用),产生健康违规:-
<release-name>-anomaly-detection-spotlight-manager-*:分布式异常检测工作 -
<release-name>-anomaly-detection-spotlight-worker-*:对指标流进行异常检测
-
-
Platform-Distributed:该平台包含主要的处理组件和服务 API。在分布式模式下,功能单元被拆分。属于该平台的 pods:-
<release-name>-suse-observability-api-*:向用户提供所有数据并管理 StackPack 的安装/卸载。 -
<release-name>-suse-observability-checks-*:运行监控程序 -
<release-name>-suse-observability-health-sync-*:处理来自监控程序和 SUSE Observability 代理的健康(违规)信息,并将其附加到拓扑中。 -
<release-name>-suse-observability-initializer-*:协调数据存储和迁移的初始化 -
<release-name>-suse-observability-notification-*:根据健康违规和用户设置将通知转发到下游系统,如 Slack/Opsgenie。 -
<release-name>-suse-observability-slicing-*:持续优化拓扑历史以便快速检索 -
<release-name>-suse-observability-state-*:处理健康违规并将其汇总到组件健康中 -
<release-name>-suse-observability-sync-*:处理与用户设置结合的拓扑数据,并将其转化为拓扑图。
-
-
Platform-Mono:-
<release-name>-suse-observability-server-*:包含`Platform-Distributed`设置的所有功能,但在一个单一的 pod 中。
-