|
本文档采用自动化机器翻译技术翻译。 尽管我们力求提供准确的译文,但不对翻译内容的完整性、准确性或可靠性作出任何保证。 若出现任何内容不一致情况,请以原始 英文 版本为准,且原始英文版本为权威文本。 |
为代表性图表编写 PromQL 查询
准则
当 SUSE Observability 在图表中显示数据时,几乎总是需要更改存储数据的分辨率,以使其适合图表的可用空间。为了获得尽可能代表性的图表,请遵循以下指南:
-
不要查询原始指标,而是始终在时间上进行聚合(使用
*_over_time或rate函数)。 -
将
${__interval}参数用作时间聚合的范围,它会随着图表的分辨率自动调整。 -
将
${__rate_interval}参数用作rate聚合的范围,它也会随着图表的分辨率自动调整,但会考虑rate的特定行为。
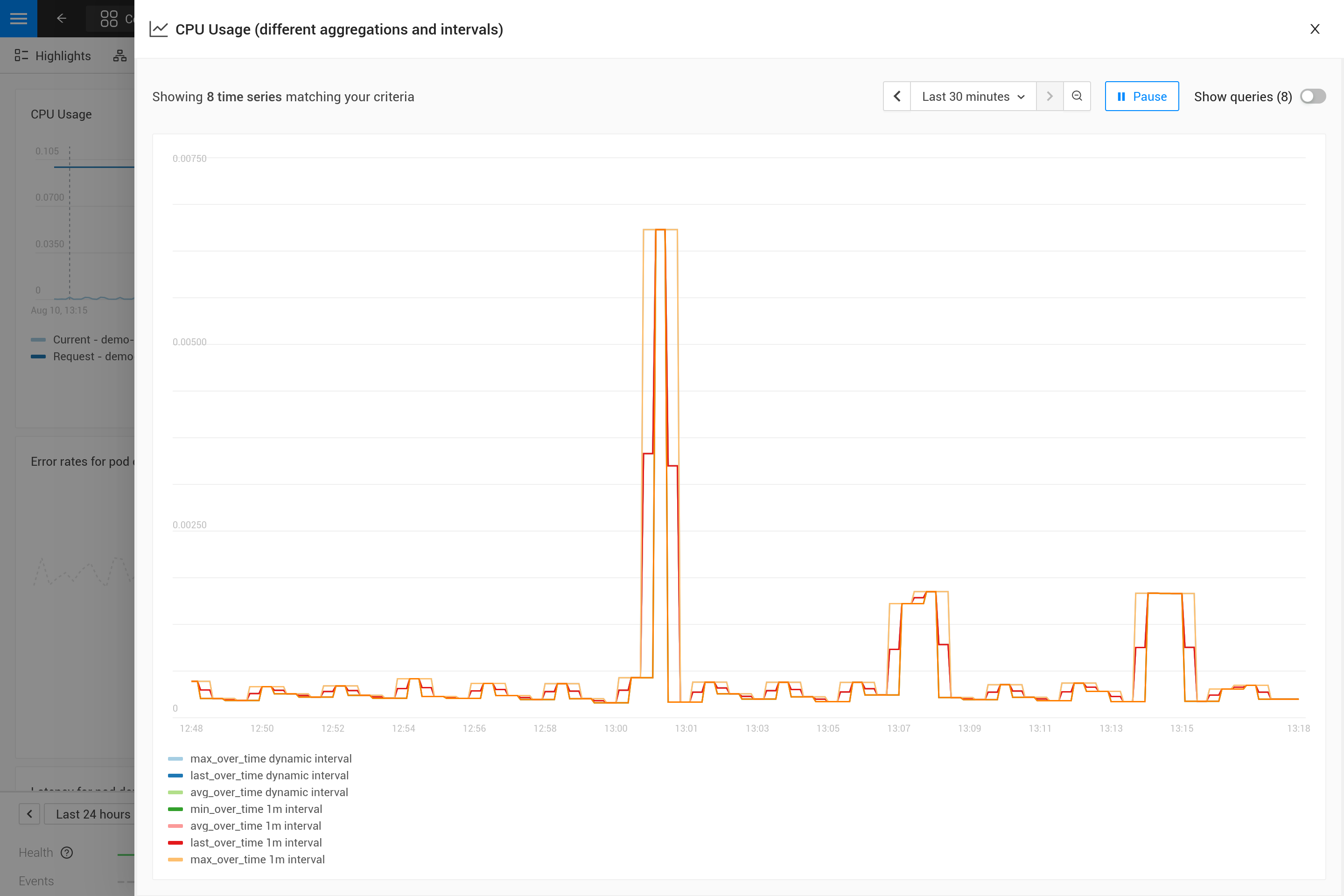
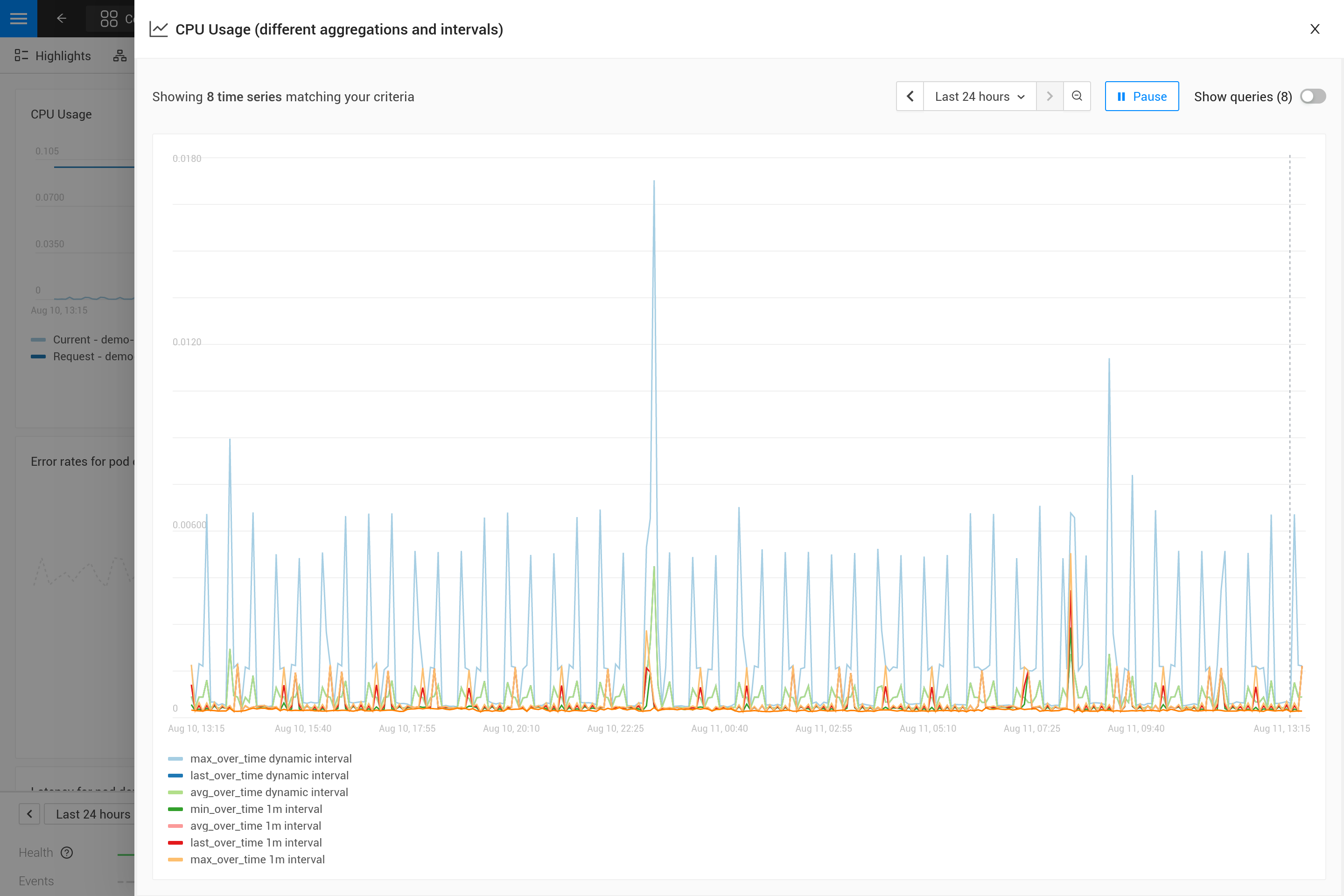
应用聚合通常意味着在指标中强调某些模式而牺牲其他模式。例如,对于较大的时间窗口,max_over_time 会显示所有峰值,但不会显示所有谷值。而 min_over_time 则完全相反,avg_over_time 会平滑处理峰值和谷值。为了展示这种行为,这里是一个使用 Pod CPU 使用率的示例指标绑定。要自己尝试,请将其复制到 YAML 文件中,并在您自己的 SUSE Observability 中使用 CLI 来应用它(您可以稍后去除它)。
nodes:
- _type: MetricBinding
chartType: line
enabled: true
tags: {}
unit: short
name: CPU Usage (different aggregations and intervals)
priority: HIGH
identifier: urn:custom:metric-binding:pod-cpu-usage-a
queries:
- expression: sum(max_over_time(container_cpu_usage{cluster_name="${tags.cluster-name}", namespace="${tags.namespace}", pod_name="${name}"}[${__interval}])) by (cluster_name, namespace, pod_name) /1000000000
alias: max_over_time dynamic interval
- expression: sum(min_over_time(container_cpu_usage{cluster_name="${tags.cluster-name}", namespace="${tags.namespace}", pod_name="${name}"}[${__interval}])) by (cluster_name, namespace, pod_name) /1000000000
alias: min_over_time dynamic interval
- expression: sum(avg_over_time(container_cpu_usage{cluster_name="${tags.cluster-name}", namespace="${tags.namespace}", pod_name="${name}"}[${__interval}])) by (cluster_name, namespace, pod_name) /1000000000
alias: avg_over_time dynamic interval
- expression: sum(last_over_time(container_cpu_usage{cluster_name="${tags.cluster-name}", namespace="${tags.namespace}", pod_name="${name}"}[${__interval}])) by (cluster_name, namespace, pod_name) /1000000000
alias: last_over_time dynamic interval
- expression: sum(max_over_time(container_cpu_usage{cluster_name="${tags.cluster-name}", namespace="${tags.namespace}", pod_name="${name}"}[1m])) by (cluster_name, namespace, pod_name) /1000000000
alias: max_over_time 1m interval
- expression: sum(min_over_time(container_cpu_usage{cluster_name="${tags.cluster-name}", namespace="${tags.namespace}", pod_name="${name}"}[1m])) by (cluster_name, namespace, pod_name) /1000000000
alias: min_over_time 1m interval
- expression: sum(avg_over_time(container_cpu_usage{cluster_name="${tags.cluster-name}", namespace="${tags.namespace}", pod_name="${name}"}[1m])) by (cluster_name, namespace, pod_name) /1000000000
alias: avg_over_time 1m interval
- expression: sum(last_over_time(container_cpu_usage{cluster_name="${tags.cluster-name}", namespace="${tags.namespace}", pod_name="${name}"}[1m])) by (cluster_name, namespace, pod_name) /1000000000
alias: last_over_time 1m interval
scope: (label = "stackpack:kubernetes" and type = "pod")
应用后,打开 SUSE Observability 中 Pod 的指标视角(最好是一个 CPU 使用率有一些峰值和谷值的 Pod)。使用图表右上角的图标放大图表,以获得更好的视图。现在,您还可以更改时间窗口,以查看不同聚合的效果(例如 30 分钟与 24 小时)。
|
当指标绑定未指定聚合时,SUSE Observability 将自动使用 |
为什么这是必要的?
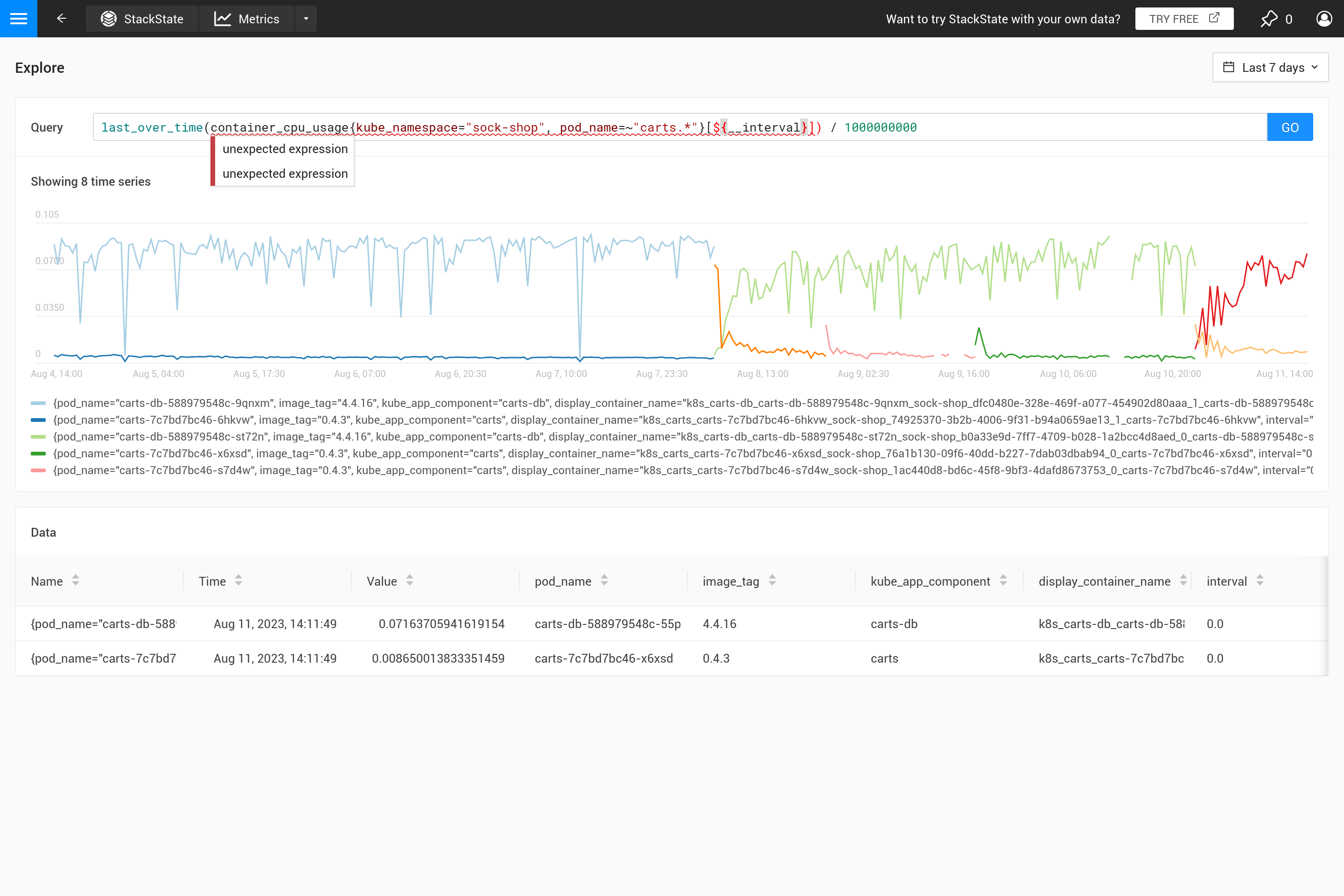
首先,您为什么应该使用聚合?从度量存储中检索的数据点数量不能超过图表所能容纳的数量。因此,SUSE Observability 会自动确定两个数据点之间所需的步长,以获得良好的结果。对于短时间窗口(例如仅显示 1 小时数据的图表),这会导致较小的步长(大约 10 秒)。度量通常每 30 秒收集一次,因此对于 10 秒的步长,相同的值将在 3 个步长内重复,然后才会更改为下一个值。缩小到 1 周的时间窗口将需要更大的步长(大约 1 小时,具体取决于屏幕上图表的确切大小)。
当步长大于收集的数据点的分辨率时,需要决定如何将 1 小时时间范围内的数据点汇总为一个值。当查询中已经指定了时间上的聚合时,将使用该聚合来进行汇总。然而,如果没有指定聚合,或者当聚合间隔小于步长时,将使用 last_over_time 聚合,间隔为 step 大小。结果是每小时仅使用最后一个数据点来“汇总”该小时内的所有数据点。
总之,当执行针对 1 周时间范围的 PromQL 查询,步长为 1 小时时,该查询:
container_cpu_usage /1000000000
会自动转换为:
last_over_time(container_cpu_usage[1h]) /1000000000
您可以在 SUSE Observability playground 上亲自尝试。
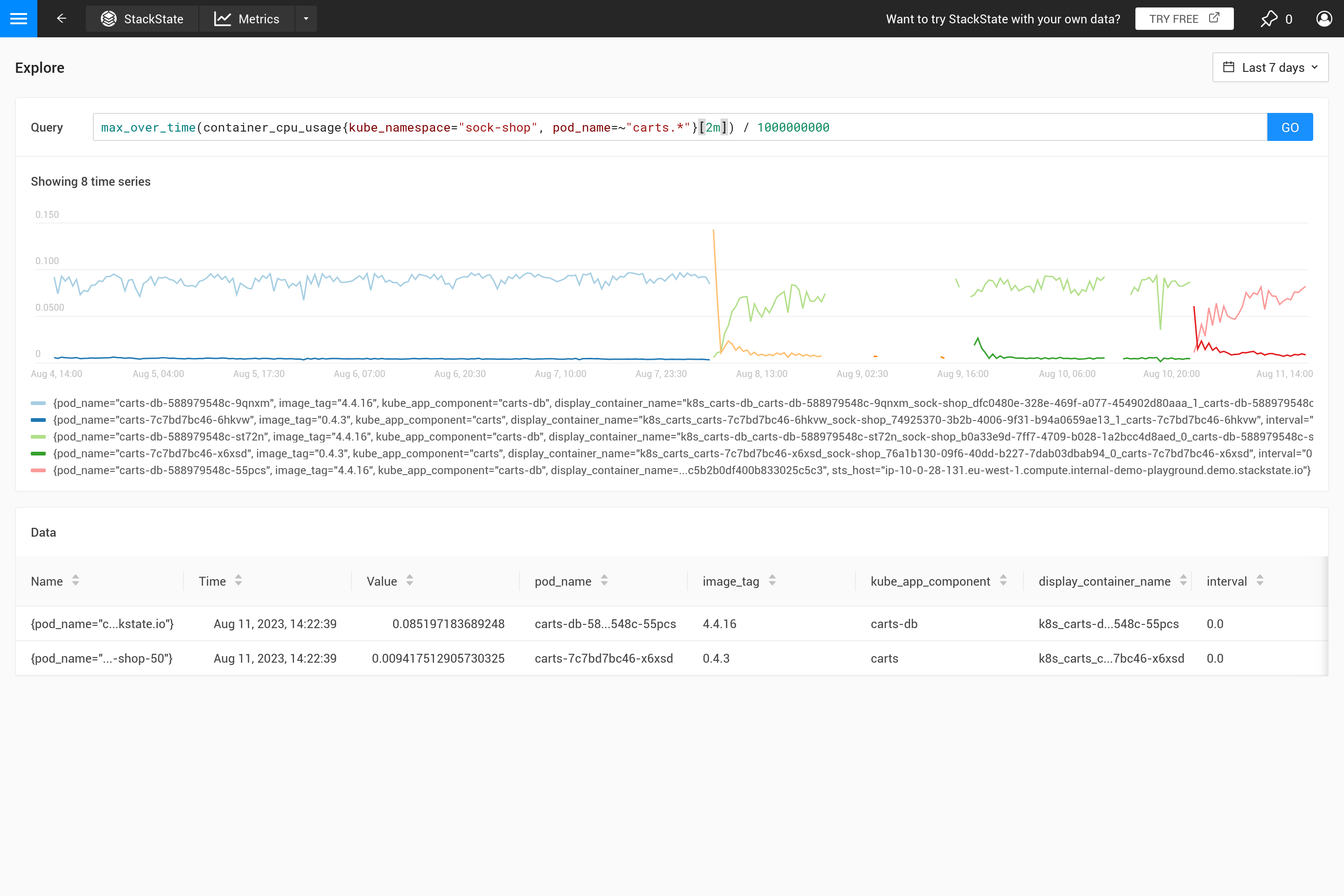
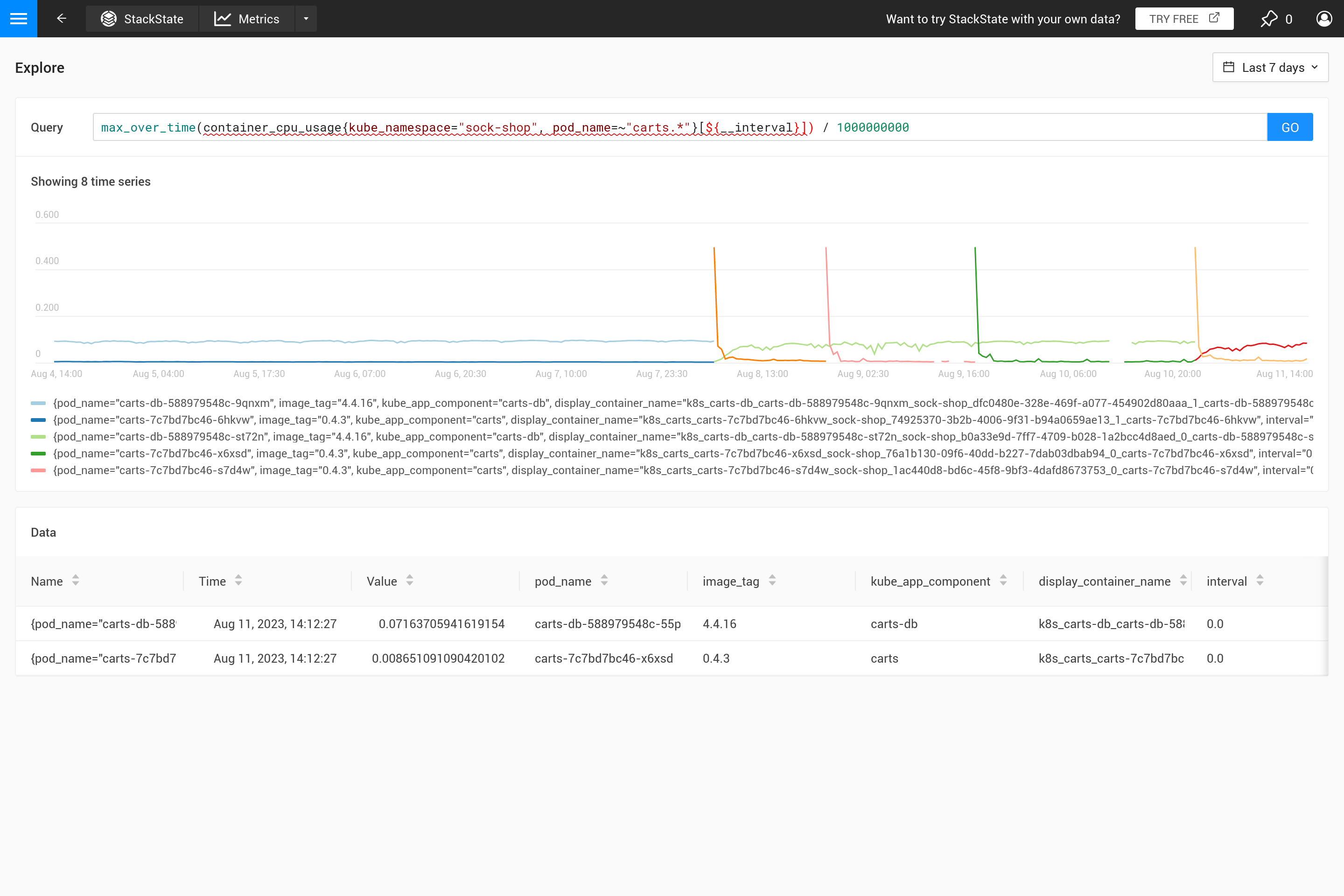
这种行为通常不是预期的,最好自己决定需要什么样的聚合。使用不同的聚合函数可以强调某些行为(代价是隐藏其他行为)。更重要的是查看峰值、谷值、平滑图表等吗?那么使用 ${__interval} 参数作为范围,因为它会自动替换为查询中使用的 step 大小。结果是步长内的所有数据点都被使用。
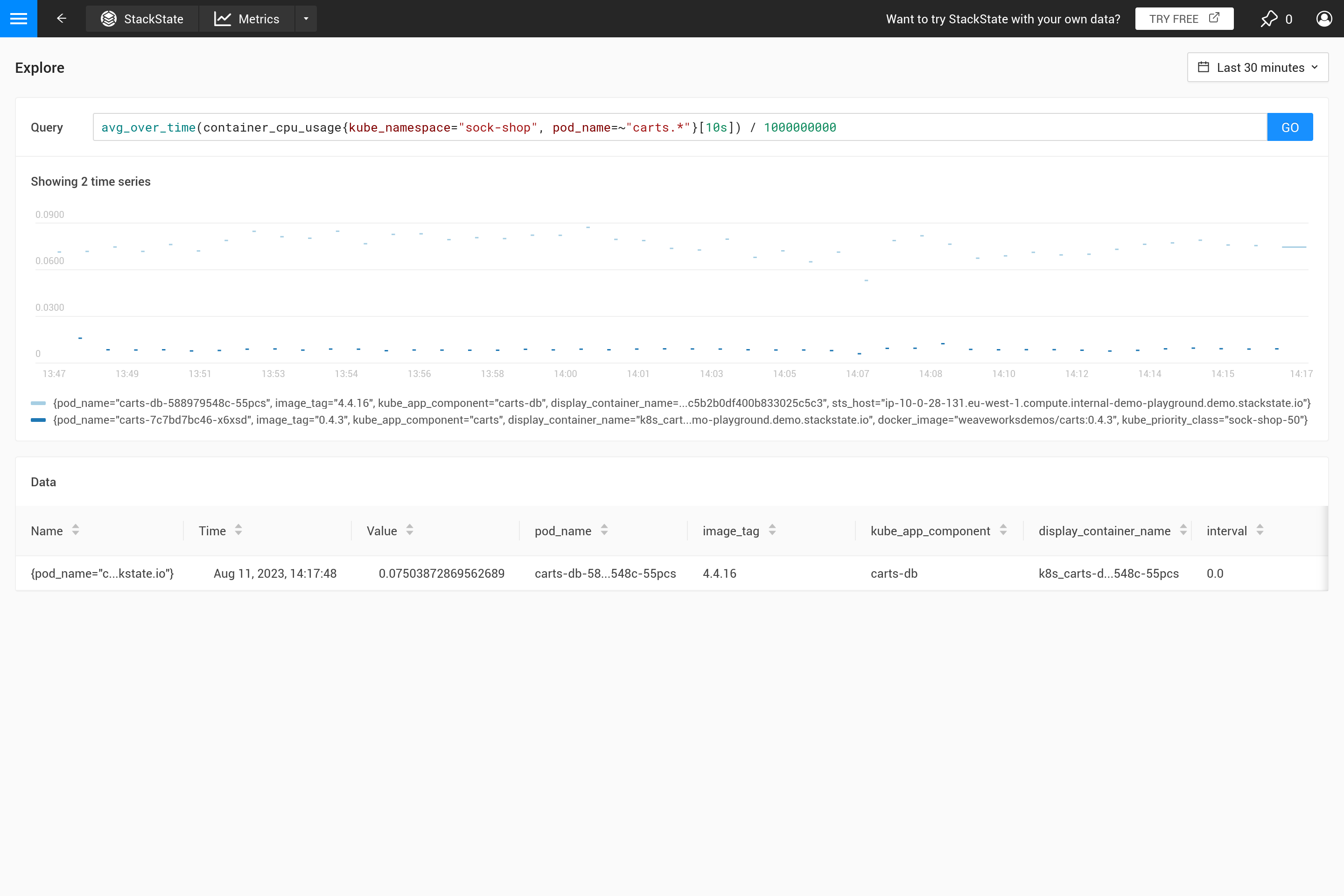
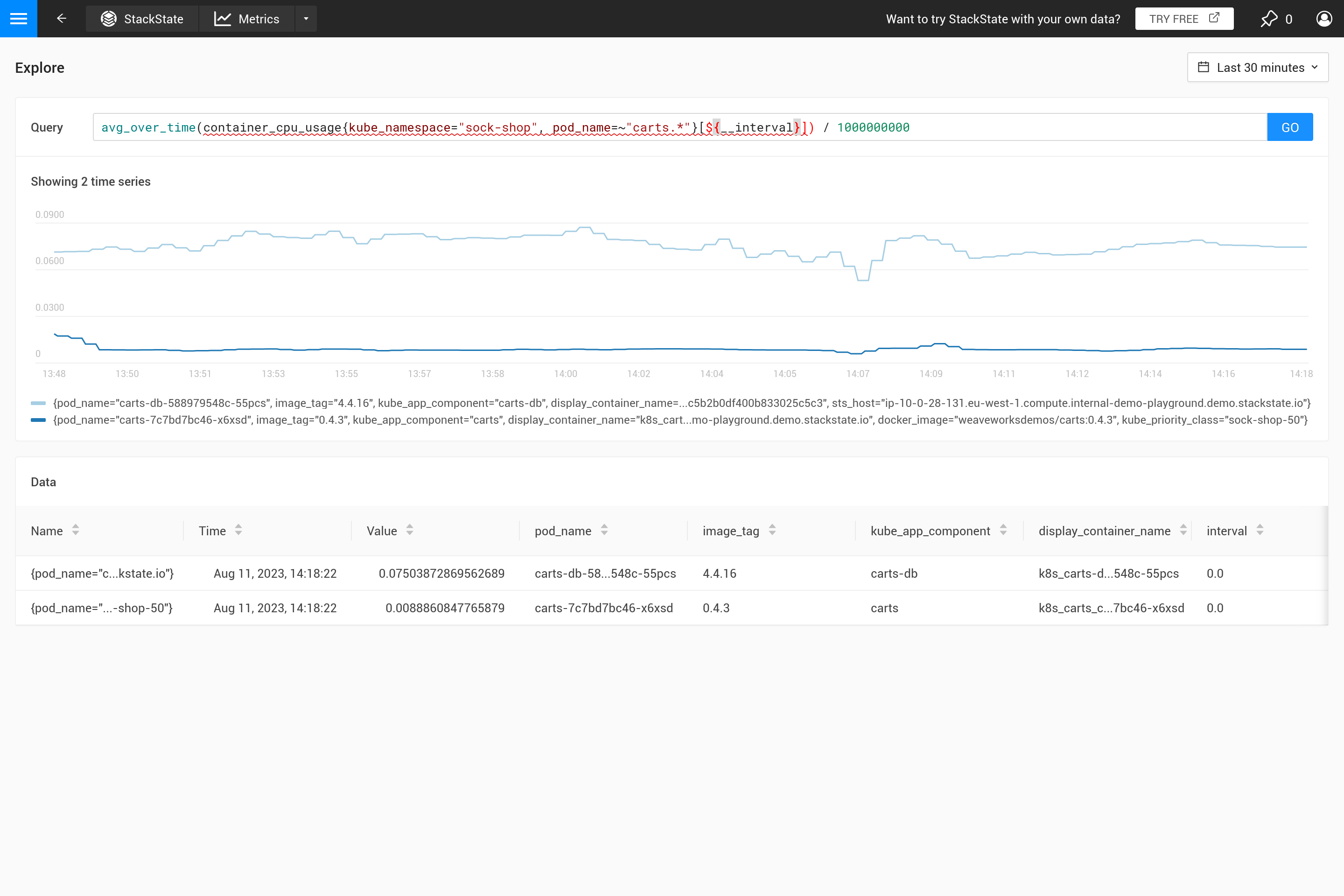
${interval} 参数防止了另一个问题。当`step`的大小以及`${interval}`的值缩小到小于存储的度量数据的分辨率时,这将导致图表中出现空白。
因此,${__interval} 永远不会缩小到小于默认抓取间隔两倍(默认抓取间隔为 30 秒)的值,这是 SUSE Observability 代理的设置。
最后,rate() 函数至少需要 2 个数据点在区间内才能计算出速率。如果数据点不足 2 个,速率将没有值。因此,${__rate_interval} 保证始终至少为抓取间隔的 4 倍。这保证了速率图表中不会出现意外的空白或其他奇怪的行为,除非数据缺失。
互联网上有一些优秀的博客文章详细解释了这一点: