Dépannage avancé
Lorsque vous êtes un client privilégié, contactez le support de SUSE Observability à https://scc.suse.com/ pour obtenir de l’aide pour configurer SUSE Observability dans votre grappe locale. Utilisez Paquet de support (journaux) pour collecter des informations sur votre instance pour l’équipe de support.
Cette page fournit des informations détaillées sur les sous-systèmes de la plateforme SUSE Observability pour dépanner les problèmes de déploiement et d’exploitation. Cette page ne doit être consultée que lorsque les étapes du dépannage ne donnent pas de solution.
Approche générale de dépannage
L’approche générale pour dépanner les problèmes opérationnels de la plateforme SUSE Observability est la suivante :
-
Obtenir un aperçu du comportement des pods via
kubectl get pods -
Utilisez les informations détaillées sur les sous-systèmes dans ce document, ainsi que les symptômes du problème, pour déterminer quels pods/sous-systèmes pourraient être la cause racine.
-
Inspectez les journaux/métadonnées des pods suspects via :
-
kubectl logs <pod-name> --all-containers=true -
kubectl describe pod <pod-name> -
Un moyen rapide d’obtenir tous les journaux/descriptions liés à SUSE Observability est via le Paquet de support (journaux).
-
-
Il se peut que les journaux indiquent un dysfonctionnement d’une dépendance, dans ce cas, enquêtez sur la dépendance.
Aperçu des sous-systèmes
Bases de données
SUSE Observability est alimenté par diverses bases de données, chaque fois qu’une base de données dysfonctionne, cela doit être examiné en premier car tous les autres services en dépendent.
-
Zookeeper: Zookeeper est utilisé pour la découverte de services, l’orchestration et le basculement. Zookeeper est déployé en utilisant 1 ou plusieurs pods avec le nom :-
suse-observability-zookeeper-<n>
-
-
Kafka: Kafka est utilisé pour le passage de messages entre presque tous les services : Kafka est déployé par les pods suivants :-
suse-observability-kafka-<n>: Déploiement principal de Kafka -
<release-name>-kafkaup-operator-kafkaup-*: Opérateur d’assistance effectuant des mises à niveau de Kafka
-
-
StackGraph: StackGraph stocke les paramètres (utilisateur) et la topologie. StackGraph est composé de plusieurs composants et a 2 modes de déploiement. HA et non-HA.-
Tephra: Gère le démarrage, les validations et les conflits des transactions de base de données. Servi par le pod<release-name>-hbase-tephra-<n>-
<release-name>-hbase-tephra-<n>: Pod du serveur de transactions Tephra. Suit les transactions et les conflits.
-
-
HBase-HA: Stocke les données de StackGraph, réparties sur plusieurs pods avec différentes responsabilités :-
<release-name>-hbase-hdfs-nn-0: Nœud de nom pour HDFS, suit l’index des fichiers -
<release-name>-hbase-hdfs-snn-0: Nœud de nom secondaire, effectue le travail de nettoyage après le nœud de nom -
<release-name>-hbase-hdfs-dn-<n>: Datanode HDFS, stocke les données réelles -
<release-name>-hbase-hbase-master-<n>: HBase Master, coordonne les tables et les régions -
<release-name>-hbase-hbase-rs-<n>: Serveur de région HBase, sert les tables et les régions, stocke ses données sur HDFS
-
-
HBase-non-HA:-
<release-name>-hbase-stackgraph-0: Tous les composants de StackGraph déployés en tant que pod unique dans la configurationnon-HA. Cela inclut également sa propre instance de Zookeeper.
-
-
-
VictoriaMetrics: Stocke les données métriques. Est déployé par les pods :-
suse-observability-victoria-metrics-<n>-0: Nœud principal de stockage de données/query de VictoriaMetrics -
suse-observability-vmagent-0: Agent d’ingestion pour VictoriaMetrics. Les données sont envoyées à vmagent avant d’être transférées et stockées.
-
-
ClickHouse: Stocke les données de trace. Déployé par les pod(s) suivants :-
suse-observability-clickhouse-shard0-<n>: Stockage principal de ClickHouse
-
-
ElasticSearch: Stocke les événements et les journaux. Déployé par les pods suivants :-
suse-observability-elasticsearch-master-<n>: Stockage principal d’Elasticsearch -
<release-name>-prometheus-elasticsearch-exporter-*: Exporte les métriques de performance des instances Elasticsearch
-
Services d’ingestion
La plateforme d’observabilité SUSE reçoit des données envoyées par l’agent et l’agent OpenTelemetry (OTEL). Les services d’ingestion effectuent un traitement initial et amènent les données au stockage.
-
Receiver: Le récepteur implémente l’API côté collecte pour l’agent d’observabilité SUSE. Il accepte et autorise les données de télémétrie (journaux, événements, métriques ou topologie) et les transfère au magasin de données correspondant ou à Kafka. Il peut être déployé en mode simple ou en mode partagé :-
Receiver-Split:-
<release-name>-suse-observability-receiver-logs-*: Reçoit les journaux et les place dans Elasticsearch -
<release-name>-suse-observability-receiver-process-agent-*: Reçoit des informations sur les processus et la connectivité réseau et les transfère aux sujets Kafka -
<release-name>-suse-observability-receiver-base-*: Toutes les autres données de l’agent d’observabilité SUSE passent par ici.
-
-
Receiver-NonSplit:-
<release-name>-suse-observability-receiver-*: Toutes les données de l’agent d’observabilité SUSE passent par ici.
-
-
-
OpenTelemetry Collector: Fournit un point de terminaison auquel les agents OpenTelemetry peuvent envoyer des données OpenTelemetry et produit des traces, des métriques et une topologie basées sur les données envoyées.-
suse-observability-otel-collector-0: Pod unique implémentant le collecteur OTEL
-
Traitement et service
La plateforme d’observabilité SUSE effectue la corrélation et la surveillance des données de télémétrie qu’elle reçoit. Les résultats sont fournis au client à la demande via l’API. La plateforme principale peut être exécutée en mode distribué et non distribué. Le mode distribué permet un débit plus élevé.
-
Correlator: Corrèle les informations de connexion TCP pour les transformer en topologie. Implémenté par le pod :-
<release-name>-suse-observability-correlate-*
-
-
Events2Elasticsearch: Traite les événements et les stocke dans Elasticsearch : Implémenté par le pod :-
<release-name>-suse-observability-e2es-*
-
-
Anomaly Detection: La plateforme d’observabilité SUSE effectue la détection d’anomalies (désactivée par défaut) sur les métriques, produisant des violations de santé :-
<release-name>-anomaly-detection-spotlight-manager-*: Travail de détection d’anomalies distribué -
<release-name>-anomaly-detection-spotlight-worker-*: Effectue la détection d’anomalies sur les flux de métriques
-
-
Platform-Distributed: La plateforme contient les principaux composants de traitement et l’API de service. En mode distribué, les unités fonctionnelles sont séparées. Les pods qui appartiennent à la plateforme :-
<release-name>-suse-observability-api-*: Fournit toutes les données à l’utilisateur et gère l’installation/désinstallation de StackPack. -
<release-name>-suse-observability-checks-*: Exécute les moniteurs -
<release-name>-suse-observability-health-sync-*: Traite les informations de santé (violation) provenant des moniteurs et de l’agent d’observabilité SUSE et les attache à la topologie. -
<release-name>-suse-observability-initializer-*: Coordonne l’initialisation des magasins de données et des migrations. -
<release-name>-suse-observability-notification-*: Transmet des notifications basées sur les violations de santé et les paramètres de l’utilisateur aux systèmes en aval comme Slack/Opsgenie. -
<release-name>-suse-observability-slicing-*: Optimise en continu l’historique de topologie pour un accès rapide. -
<release-name>-suse-observability-state-*: Traitement des violations de santé et agrégation de celles-ci dans la santé des composants. -
<release-name>-suse-observability-sync-*: Traite les données de topologie combinées avec les paramètres de l’utilisateur et les transforme en graphique de topologie.
-
-
Platform-Mono:-
<release-name>-suse-observability-server-*: Contient toutes les fonctionnalités de la configurationPlatform-Distributedmais dans un seul pod.
-
Divers
-
Routing: Accepte les connexions et les dirige vers le bon service backend :-
<release-name>-suse-observability-router-: Routeur basé sur Envoy.
-
-
UI: Interface utilisateur basée sur React.-
<release-name>-suse-observability-ui: Ne sert que le code et les ressources statiques de l’interface utilisateur, tout comportement dynamique est géré par leapi.
-
-
Backup/Restore: Exécute périodiquement des tâches pour sauvegarder les différents magasins de données. Dispose d’un pod en cours d’exécution en continu :-
suse-observability-minio-*: Fournit une interface abstraite pour interagir avec le stockage de sauvegarde.
-
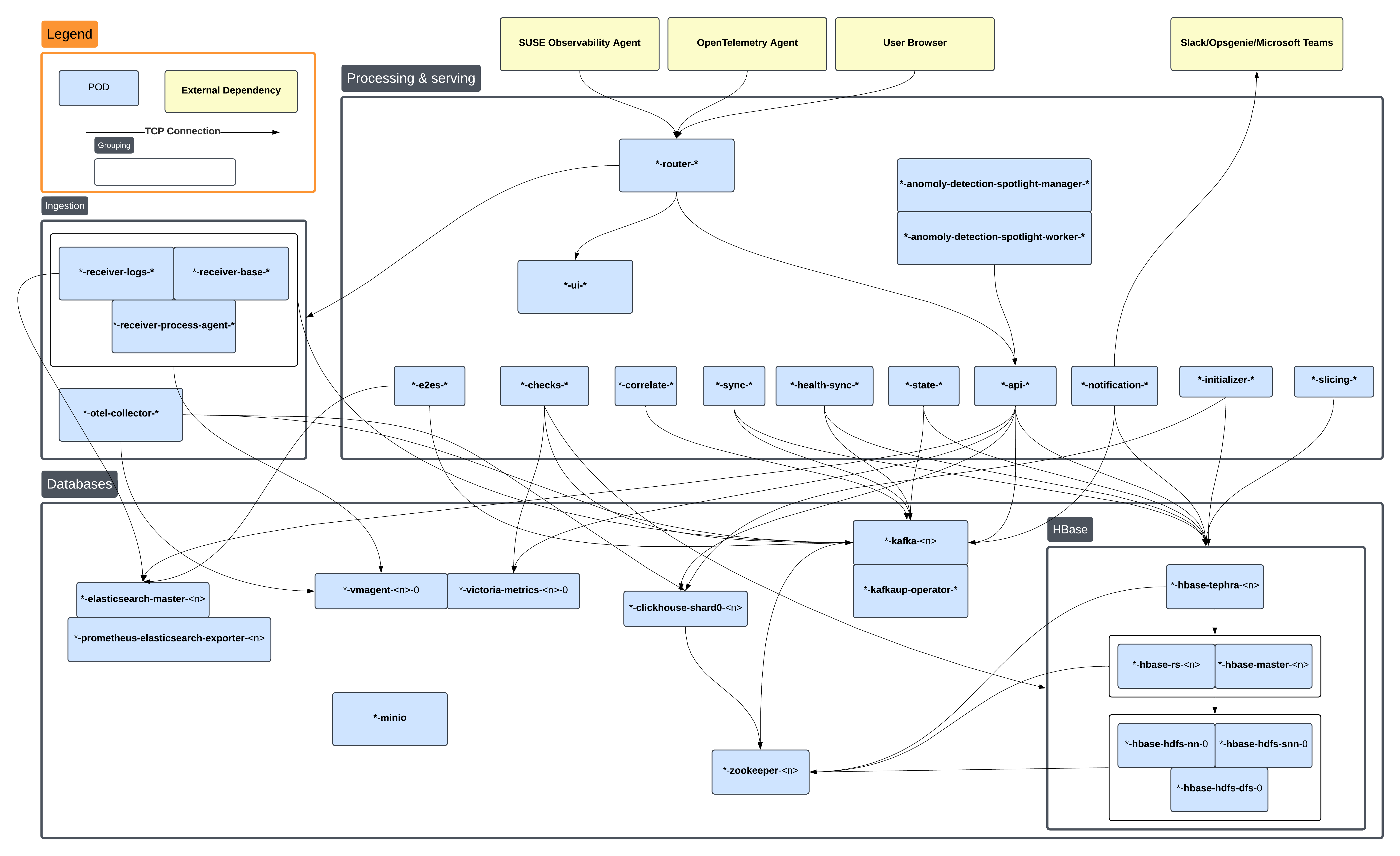
Relations entre les sous-systèmes.
Pour trouver efficacement la cause profonde d’un problème, il est important de comprendre quels pods dépendent des autres lors du déploiement. Le diagramme suivant montre un aperçu des pods avec des connexions TCP qui peuvent exister entre eux. Lors de la recherche d’une cause profonde, il est logique de se tourner vers le pod qui est le plus 'bas' dans cette chaîne de dépendance.
Les noms des pods dans ce diagramme sont abrégés pour des raisons de concision.