|
Ce document a été traduit à l'aide d'une technologie de traduction automatique. Bien que nous nous efforcions de fournir des traductions exactes, nous ne fournissons aucune garantie quant à l'exhaustivité, l'exactitude ou la fiabilité du contenu traduit. En cas de divergence, la version originale anglaise prévaut et fait foi. |
Écriture de requêtes PromQL pour des graphiques représentatifs
Autres indications
Lorsque SUSE Observability affiche des données dans un graphique, il est presque toujours nécessaire de modifier la résolution des données stockées pour les adapter à l’espace disponible pour le graphique. Pour obtenir les graphiques les plus représentatifs possibles, suivez ces directives :
-
N’interrogez pas la métrique brute, mais agrégez-la toujours dans le temps (en utilisant les fonctions
*_over_timeourate). -
Utilisez le paramètre
${__interval}comme plage pour les agrégations dans le temps, il s’ajustera automatiquement avec la résolution du graphique. -
Utilisez le paramètre
${__rate_interval}comme plage pour les agrégationsrate, il s’ajustera également automatiquement avec la résolution du graphique, mais prend en compte des comportements spécifiques derate.
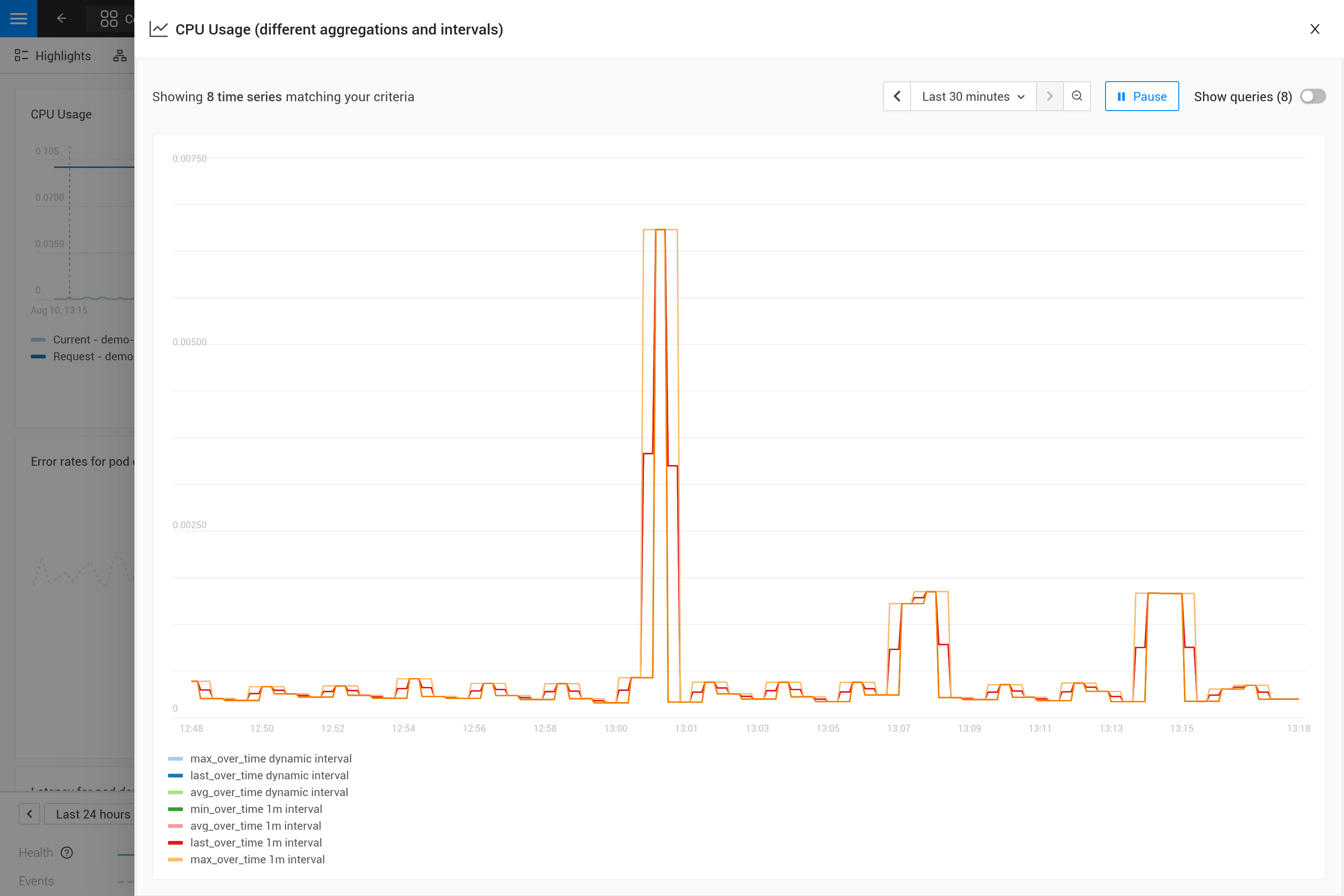
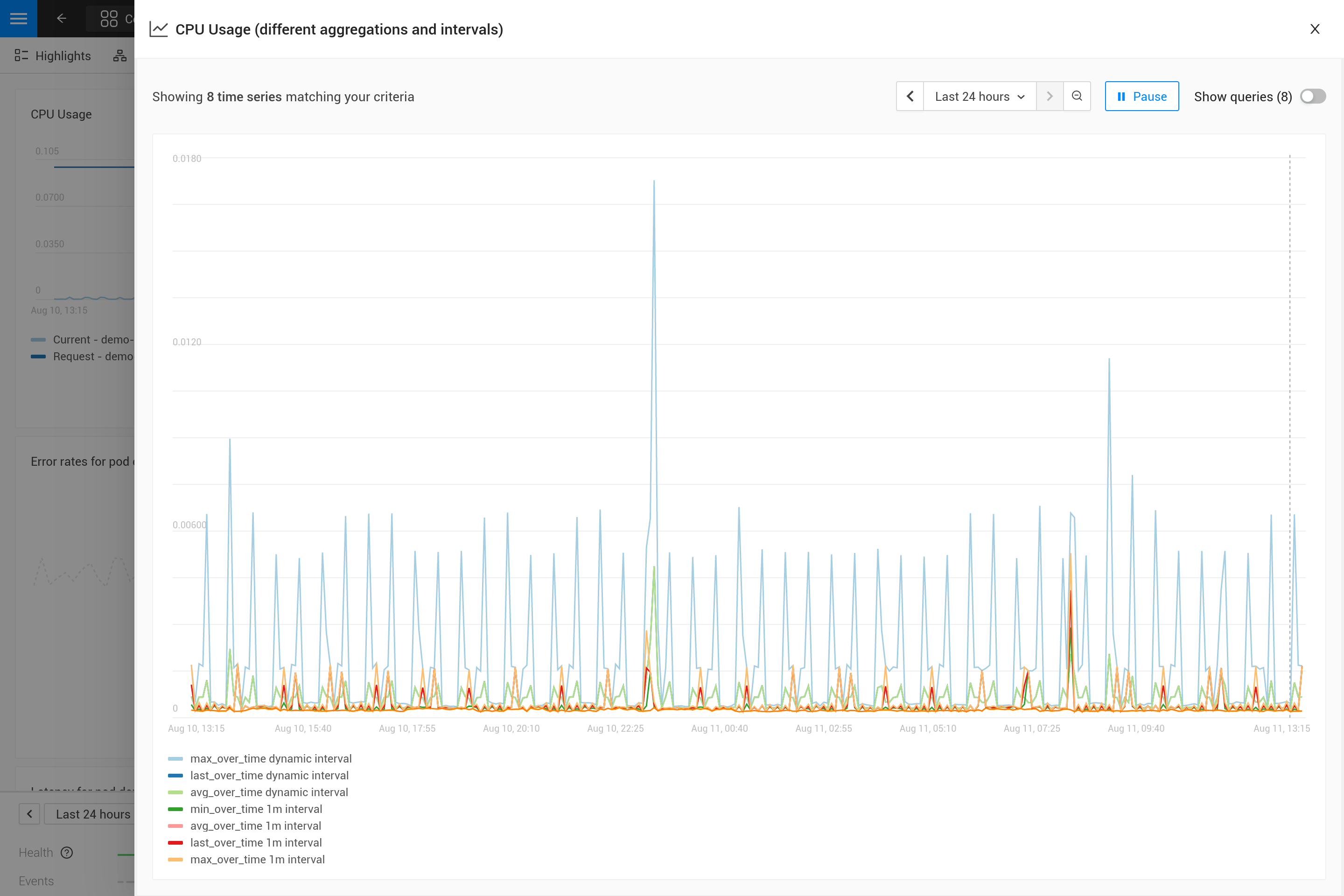
Appliquer une agrégation signifie souvent qu’un compromis est fait pour mettre en avant certains modèles dans les métriques plus que d’autres. Par exemple, pour de grandes fenêtres temporelles, max_over_time montrera tous les pics, mais ne montrera pas tous les creux. Alors que min_over_time fait exactement l’opposé et avg_over_time lisse à la fois les pics et les creux. Pour montrer ce comportement, voici un exemple de liaison de métriques utilisant l’utilisation de l’UC des pods. Pour essayer par vous-même, copiez-le dans un fichier YAML et utilisez le CLI pour l’appliquer dans votre propre SUSE Observability (vous pouvez le supprimer plus tard).
nodes:
- _type: MetricBinding
chartType: line
enabled: true
tags: {}
unit: short
name: CPU Usage (different aggregations and intervals)
priority: HIGH
identifier: urn:custom:metric-binding:pod-cpu-usage-a
queries:
- expression: sum(max_over_time(container_cpu_usage{cluster_name="${tags.cluster-name}", namespace="${tags.namespace}", pod_name="${name}"}[${__interval}])) by (cluster_name, namespace, pod_name) /1000000000
alias: max_over_time dynamic interval
- expression: sum(min_over_time(container_cpu_usage{cluster_name="${tags.cluster-name}", namespace="${tags.namespace}", pod_name="${name}"}[${__interval}])) by (cluster_name, namespace, pod_name) /1000000000
alias: min_over_time dynamic interval
- expression: sum(avg_over_time(container_cpu_usage{cluster_name="${tags.cluster-name}", namespace="${tags.namespace}", pod_name="${name}"}[${__interval}])) by (cluster_name, namespace, pod_name) /1000000000
alias: avg_over_time dynamic interval
- expression: sum(last_over_time(container_cpu_usage{cluster_name="${tags.cluster-name}", namespace="${tags.namespace}", pod_name="${name}"}[${__interval}])) by (cluster_name, namespace, pod_name) /1000000000
alias: last_over_time dynamic interval
- expression: sum(max_over_time(container_cpu_usage{cluster_name="${tags.cluster-name}", namespace="${tags.namespace}", pod_name="${name}"}[1m])) by (cluster_name, namespace, pod_name) /1000000000
alias: max_over_time 1m interval
- expression: sum(min_over_time(container_cpu_usage{cluster_name="${tags.cluster-name}", namespace="${tags.namespace}", pod_name="${name}"}[1m])) by (cluster_name, namespace, pod_name) /1000000000
alias: min_over_time 1m interval
- expression: sum(avg_over_time(container_cpu_usage{cluster_name="${tags.cluster-name}", namespace="${tags.namespace}", pod_name="${name}"}[1m])) by (cluster_name, namespace, pod_name) /1000000000
alias: avg_over_time 1m interval
- expression: sum(last_over_time(container_cpu_usage{cluster_name="${tags.cluster-name}", namespace="${tags.namespace}", pod_name="${name}"}[1m])) by (cluster_name, namespace, pod_name) /1000000000
alias: last_over_time 1m interval
scope: (label = "stackpack:kubernetes" and type = "pod")
Après l’avoir appliqué, ouvrez la perspective des métriques pour un pod dans SUSE Observability (de préférence un pod avec des pics et des creux dans l’utilisation de l’UC). Agrandissez le graphique en utilisant l’icône dans le coin supérieur droit pour obtenir une meilleure vue. Vous pouvez également changer la fenêtre temporelle pour voir quels sont les effets des différentes agrégations (30 minutes contre 24 heures par exemple).
|
Lorsque la liaison de métriques ne spécifie pas d’agrégation, SUSE Observability utilisera automatiquement l’agrégation |
Pourquoi est-ce nécessaire ?
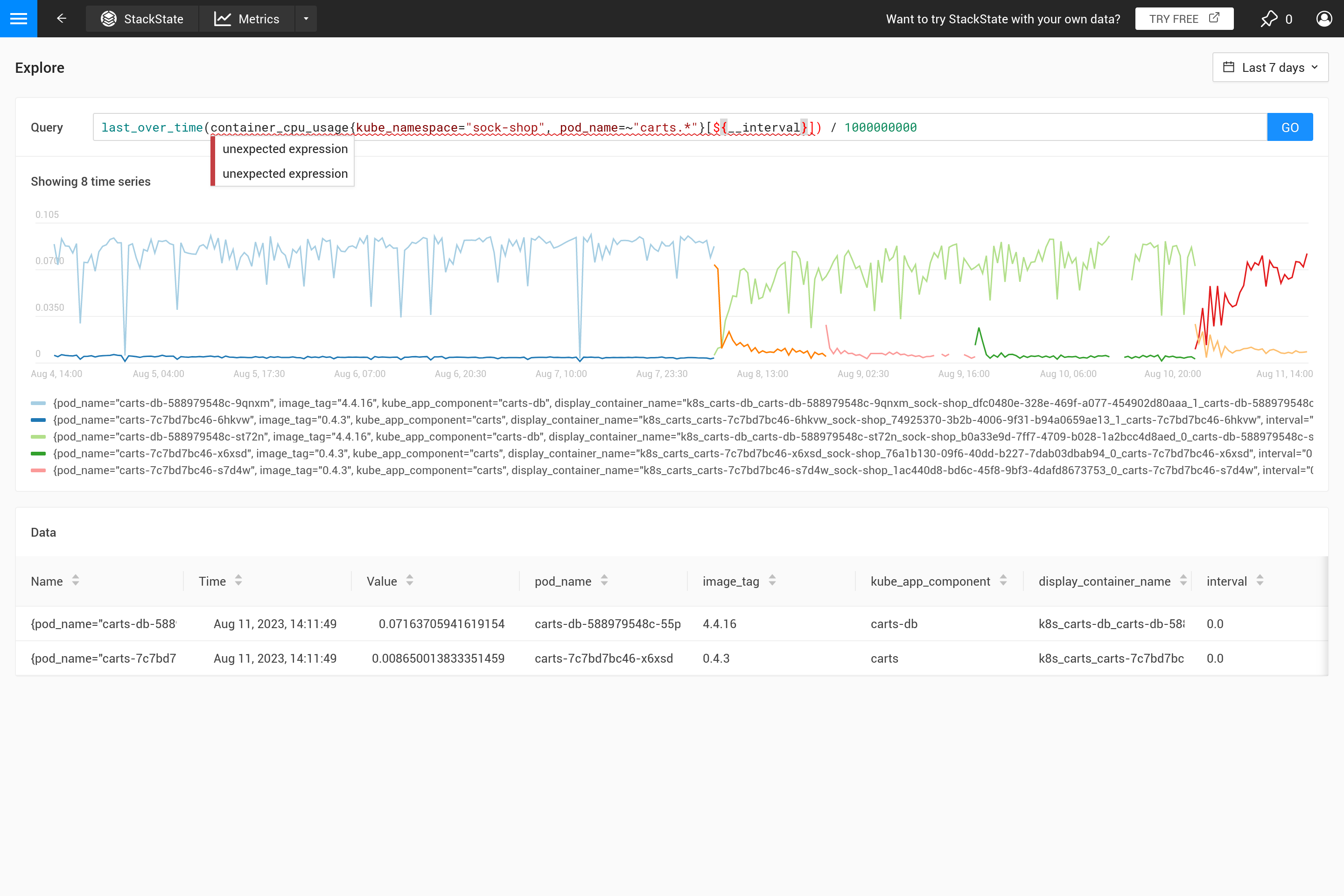
Tout d’abord, pourquoi devriez-vous utiliser une agrégation ? Il n’est pas logique de récupérer plus de points de données du magasin de métriques que ce qui peut tenir dans le graphique. Par conséquent, SUSE Observability détermine automatiquement l’étape nécessaire entre 2 points de données pour obtenir un bon résultat. Pour des fenêtres de temps courtes (par exemple, un graphique montrant seulement 1 heure de données), cela se traduit par une petite étape (environ 10 secondes). Les métriques ne sont souvent collectées que toutes les 30 secondes, donc pour des étapes de 10 secondes, la même valeur se répétera pendant 3 étapes avant de changer pour la valeur suivante. En zoomant sur une fenêtre de temps d’une semaine, une étape beaucoup plus grande sera nécessaire (environ 1 heure, selon la taille exacte du graphique à l’écran).
Lorsque les étapes deviennent plus grandes que la résolution des points de données collectés, une décision doit être prise sur la manière de résumer les points de données de la plage horaire d’une heure en une seule valeur. Lorsqu’une agrégation dans le temps est déjà spécifiée dans la requête, elle sera utilisée pour cela. Cependant, si aucune agrégation n’est spécifiée, ou lorsque l’intervalle d’agrégation est plus petit que l’étape, l’agrégation last_over_time est utilisée, avec la taille step comme intervalle. Le résultat est que seul le dernier point de données pour chaque heure est utilisé pour "résumer" tous les points de données de cette heure.
Pour résumer, lors de l’exécution d’une requête PromQL pour une plage de temps d’une semaine avec une étape d’une heure, cette requête :
container_cpu_usage /1000000000
est automatiquement convertie en :
last_over_time(container_cpu_usage[1h]) /1000000000
Essayez-le vous-même sur le SUSE Observability playground.
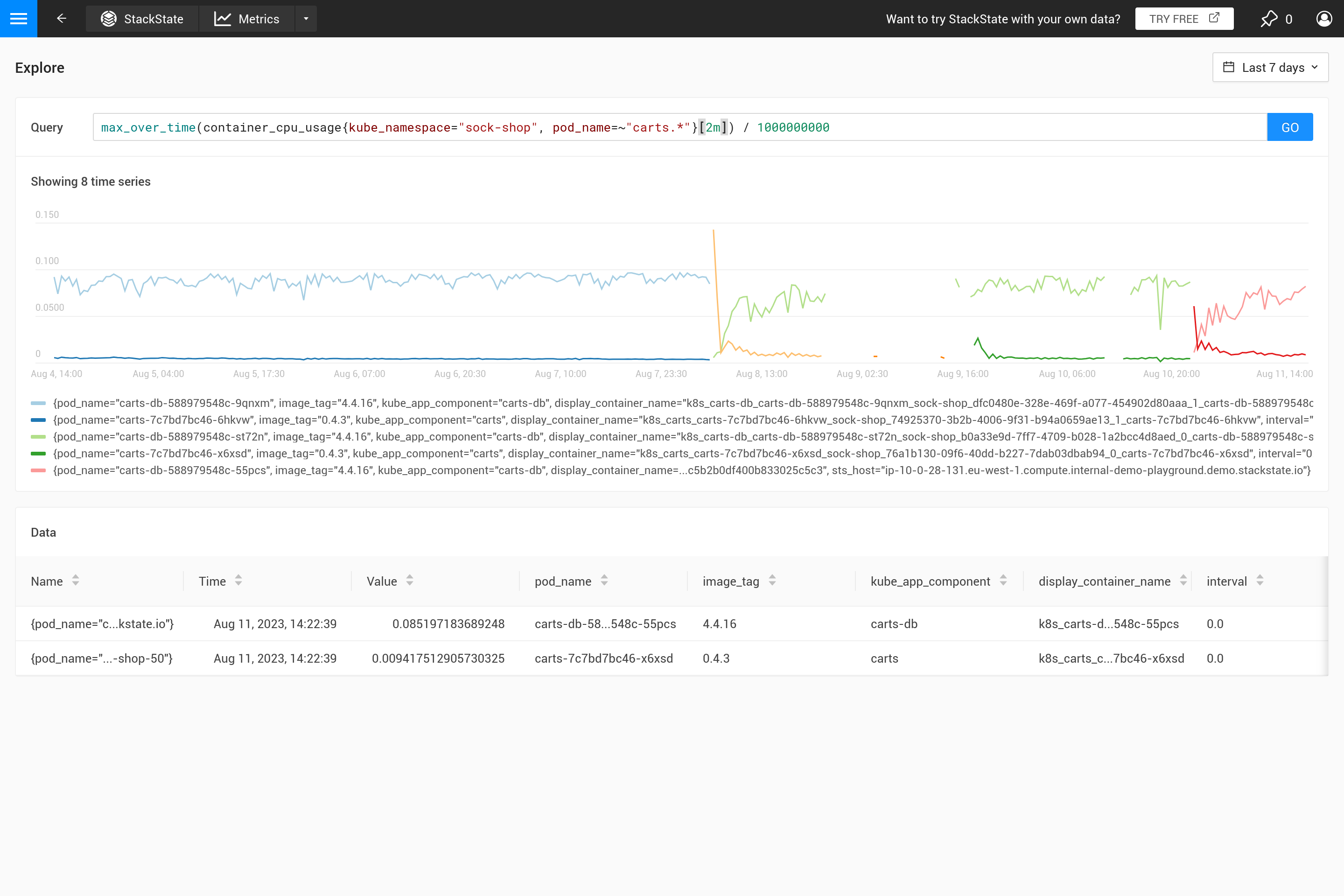
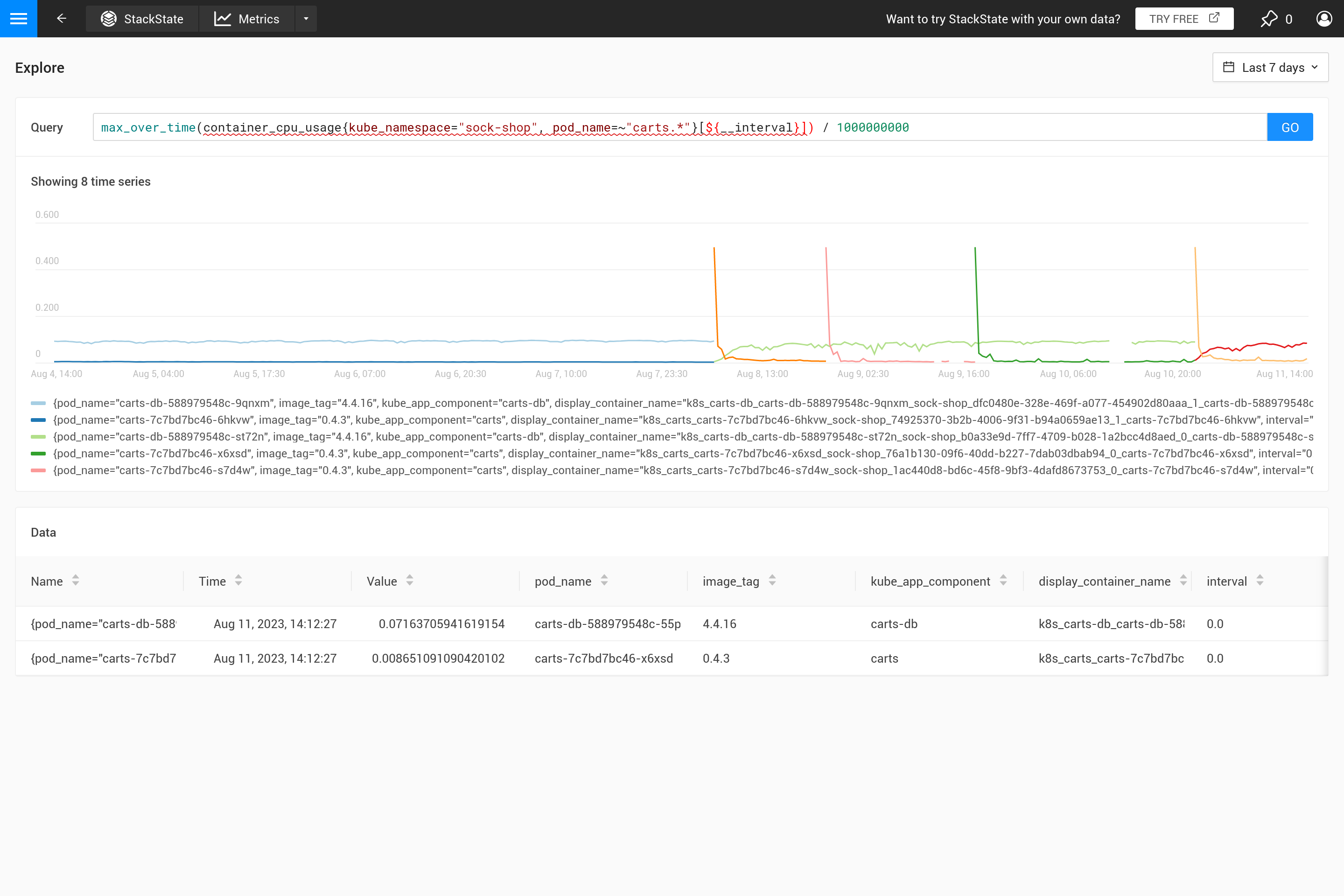
Souvent, ce comportement n’est pas intentionnel et il est préférable de décider vous-même quel type d’agrégation est nécessaire. En utilisant différentes fonctions d’agrégation, il est possible de mettre en évidence certains comportements (au détriment de masquer d’autres comportements). Est-il plus important de voir des pics, des creux, un graphique lisse, etc. ? Utilisez alors le paramètre ${__interval} pour la plage, car il est automatiquement remplacé par la taille step utilisée pour la requête. Le résultat est que tous les points de données dans l’étape sont utilisés.
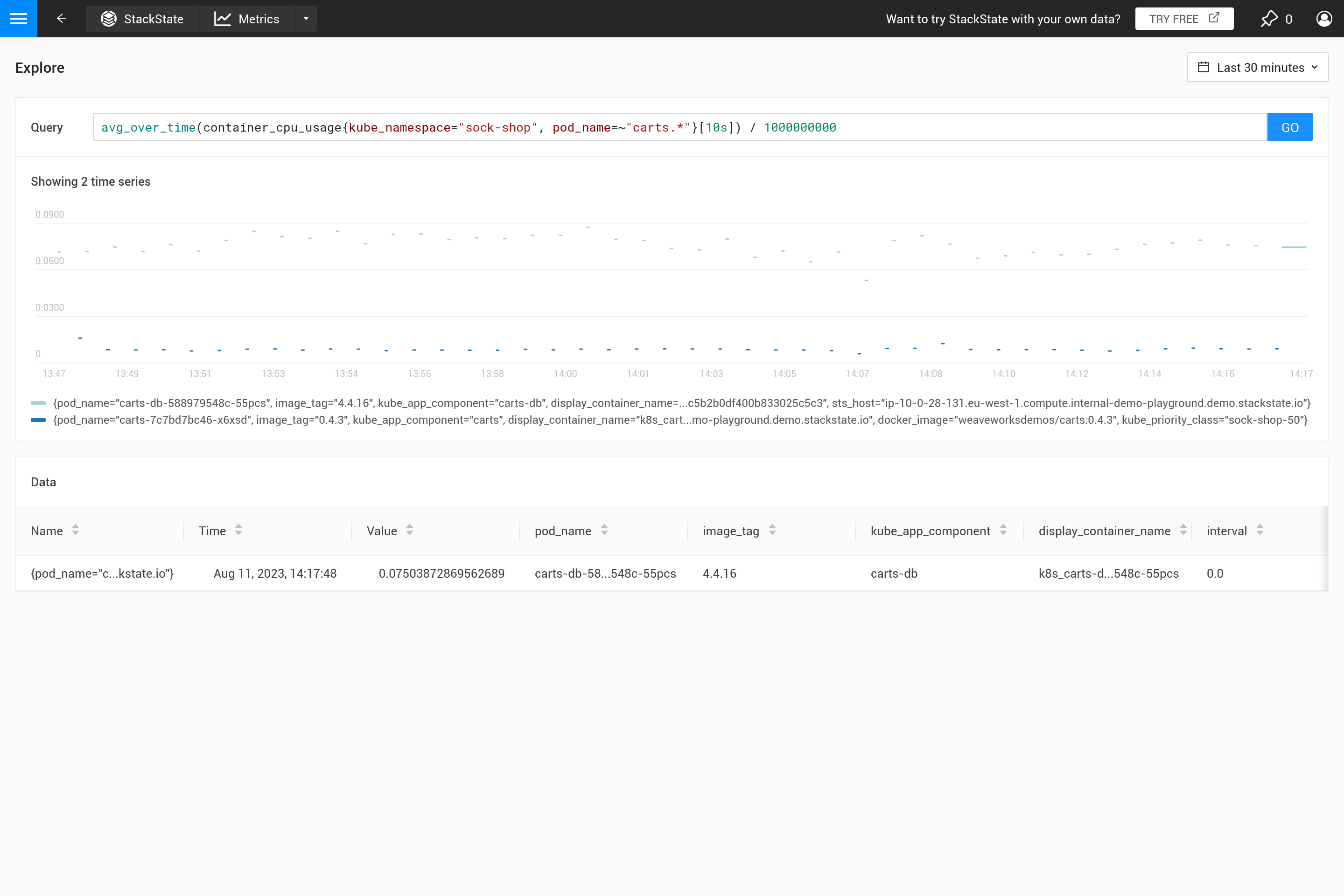
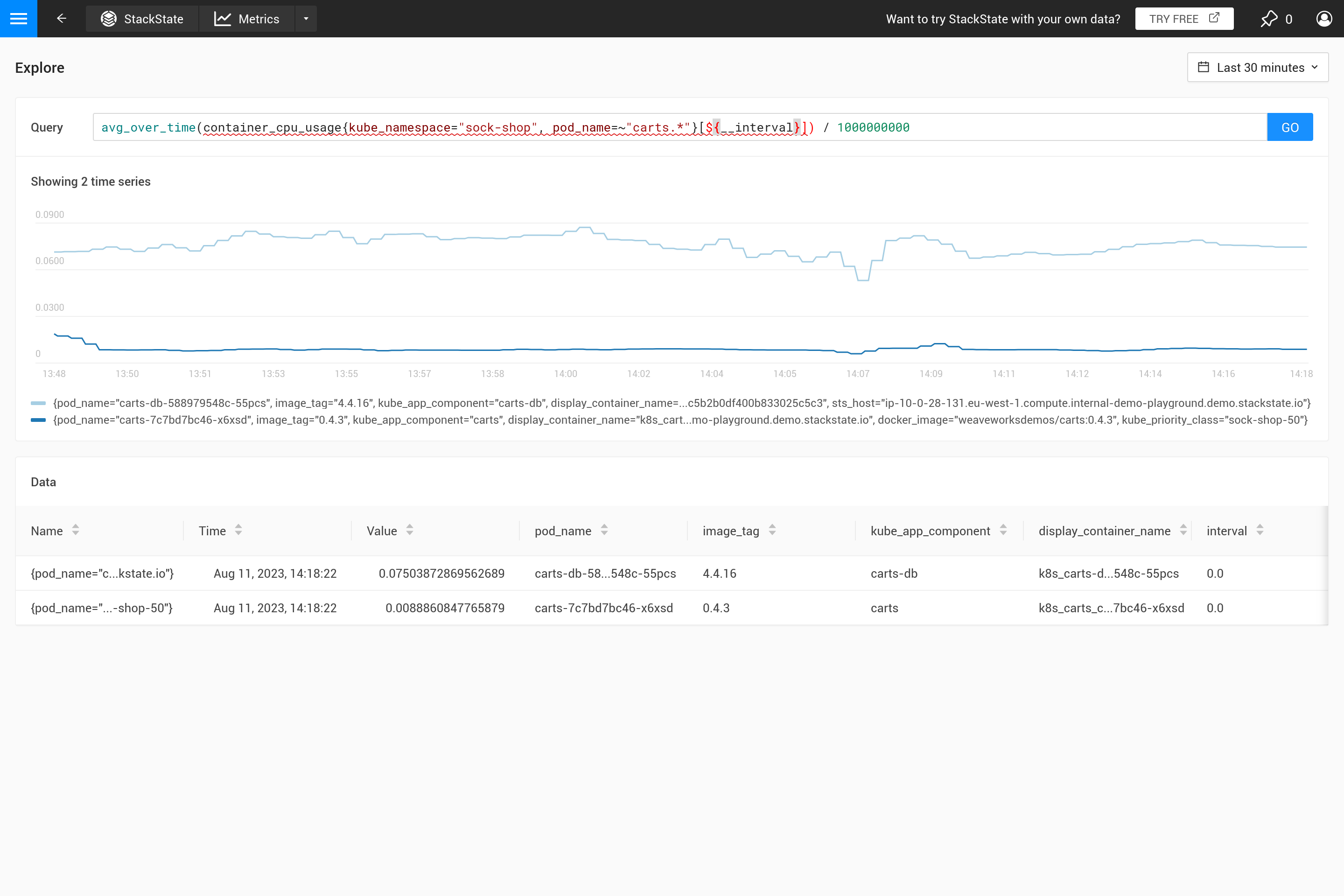
Le paramètre ${interval} empêche un autre problème. Lorsque la taille step et donc la valeur ${interval} se réduisent à une taille plus petite que la résolution des données métriques stockées, cela entraînerait des lacunes dans le graphique.
Par conséquent, ${__interval} ne sera jamais plus petit que 2 fois l’intervalle de collecte par défaut (l’intervalle de collecte par défaut est de 30 secondes) de l’agent d’observabilité SUSE.
Enfin, la fonction rate() nécessite au moins 2 points de données dans l’intervalle pour calculer un taux. Avec moins de 2 points de données, le taux n’aura pas de valeur. Par conséquent, ${__rate_interval} est garanti d’être toujours au moins 4 fois l’intervalle de collecte. Cela garantit qu’il n’y a pas de lacunes inattendues ou d’autres comportements étranges dans les graphiques de taux, sauf si des données sont manquantes.
Il existe d’excellents articles de blog sur Internet qui expliquent cela plus en détail :